


G-gen 又吉です。今回は BigQuery に備わる機械学習機能である BigQuery ML で、2 項ロジスティック回帰を用いた分類モデルを作成してみました。
BigQuery ML とは
BigQuery ML とは、BigQuery 上で機械学習モデルを作成、評価、実行ができるGoogle Cloud の機械学習プロダクトのひとつです。
通常、機械学習を行うには機械学習フレームワークに対する高度なプログラミングスキルと知識を必要としますが、BigQuery ML を用いれば SQL を用いて機械学習の一連の工程を実装できます。
BigQuery 自体はフルマネージドサービスであり、また BigQuery をデータウェアハウス (DWH) として使われている場合はデータをエクスポートする必要がないため機械学習モデルの開発効率を向上させることができます。
以下の記事では BigQuery ML を詳細に解説していますので、ご参照ください。
サポートされているモデル
BigQuery ML では、2023年3月現在以下のモデルをサポートしています。
- Linear regression
- Binary logistic regression
- Multiclass logistic regression
- K-means clustering
- Matrix Factorization
- Time series
- Boosted Tree
- Deep Neural Network
- Vertex AI AutoML Tables
- TensorFlow model importing
- Autoencoder
今回使用するデータ
今回使用するデータは、kaggle で提供されている Loan Approval Prediction の Traning Dataset.csv を使用します。
このデータセットは、住宅ローン全般を取り扱っている会社がモデルとなっており、その会社でローンの審査を受ける個人の情報 (性別、婚姻状況、教育、扶養家族の数、収入、ローン金額、信用履歴など) と「実際にローンの審査が通ったのか否か」が記載されています。
今回は、BigQuery ML を用いて「各個人の情報と審査の結果を教師データとして、ローンの審査が通るか通らないかを予測する分類モデル」を作成したいと思います。
準備
準備の工程は Cloud Shell 環境にて gcloud コマンドを用いて行います。
各種ファイルのアップロード
先程ダウンロードした Traning Dataset.csv データを、traning_dataset.csv にリネームし、 Cloud Shell にアップロードします。
また、schema.json というファイルを新規作成し、以下を記入します。
[ { "name": "Loan_ID", "type": "STRING", "mode": "Required", "description": "Unique Loan ID" }, { "name": "Gender", "type": "STRING", "mode": "Nullable", "description": "Male/ Female" }, { "name": "Married", "type": "BOOLEAN", "mode": "Nullable", "description": "Applicant married (Y/N)" }, { "name": "Dependents", "type": "STRING", "mode": "Nullable", "description": "Number of dependents" }, { "name": "Education", "type": "STRING", "mode": "Nullable", "description": "Applicant Education (Graduate/ Under Graduate)" }, { "name": "Self_Employed", "type": "BOOLEAN", "mode": "Nullable", "description": "Self-employed (Y/N)" }, { "name": "ApplicantIncome", "type": "INTEGER", "mode": "Nullable", "description": "Applicant income" }, { "name": "CoapplicantIncome", "type": "FLOAT", "mode": "Nullable", "description": "Coapplicant income" }, { "name": "LoanAmount", "type": "INTEGER", "mode": "Nullable", "description": "Loan amount in thousands" }, { "name": "Loan_Amount_Term", "type": "INTEGER", "mode": "Nullable", "description": "Term of the loan in months" }, { "name": "Credit_History", "type": "INTEGER", "mode": "Nullable", "description": "Credit history meets guidelines" }, { "name": "Property_Area", "type": "STRING", "mode": "Nullable", "description": "Urban/ Semi-Urban/ Rural" }, { "name": "Loan_Status", "type": "BOOLEAN", "mode": "Nullable", "description": "(Target) Loan approved (Y/N)" } ]
Cloud Shell 上のディレクトリが以下のように構成できれば必要なファイルの準備は揃っています。
root ├── training_dataset.csv └── schema.json
データセットの作成
BigQuery のデータセットを作成します。
bq mk --dataset --location=asia-northeast1 <DATASET_NAME>
- DATASET_NAME:データセット名
テーブルの作成
BigQuery のテーブルを作成します。
bq mk --table <PROJECT_ID>:<DATASET_NAME>.<TABLE_NAME> schema.json
- PROJECT_ID:プロジェクト ID
- TABLE_NAME:テーブル名
テーブルにデータをロード
作成したテーブルにデータをロードします。
bq --location=asia-northeast1 load \ --source_format=CSV \ --skip_leading_rows=1 \ <PROJECT_ID>:<DATASET_NAME>.<TABLE_NAME> training_dataset.csv
データの確認
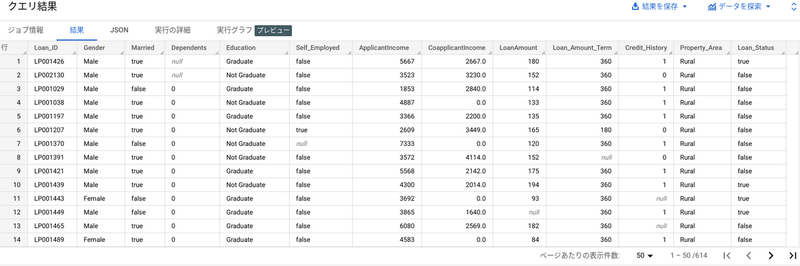
BigQuery を開いてクエリエディタで以下 SQL を実行します。(614行/13列)
SELECT * FROM `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>`
モデルの作成
データの前処理を行います。
ここからは BigQuery のコンソール画面 (クエリエディタ) から作業を行います。 まずはデータの前処理を行い、前処理を終えたデータをビューとして定義します。
CREATE OR REPLACE VIEW `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>` AS SELECT * EXCEPT(Loan_ID), CASE WHEN MOD(ABS(FARM_FINGERPRINT(Loan_ID)), 10) < 8 THEN 'training' WHEN MOD(ABS(FARM_FINGERPRINT(Loan_ID)), 10) >= 8 THEN 'prediction' END AS dataframe FROM `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>` WHERE Gender is not null AND Married is not null AND Dependents is not null AND Education is not null AND Self_Employed is not null AND ApplicantIncome is not null AND CoapplicantIncome is not null AND LoanAmount is not null AND Loan_Amount_Term is not null AND Credit_History is not null AND Property_Area is not null AND Loan_Status is not null
「Loan_Status」列には、True (審査が通った) と False (審査に落ちた) の 2 つの値が入っており、「Loan_Status」列と関連性のある属性を用いてモデルを構築します。
したがって、「Loan_ID」列は一意の値を持ち「Loan_Status」列とは関係がないため除外してます。
また、トレーニングデータと予測データを分けるために、「dataframe」列を作成しています。
最後に、各列に null が含まれる行を除外しています。
前処理を終えると 480行13列 のデータになります。
「dataframe」列を元に、トレーニングデータと予測データの割合は以下のようになっています。
| No | 種別 | 数量 | 全体 (480) に占める割合 [%] |
|---|---|---|---|
| 1 | training | 360 | 75 % |
| 2 | prediction | 120 | 25 % |
モデル構築
モデル構築を行います。
CREATE OR REPLACE MODEL `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, data_split_method='NO_SPLIT', enable_global_explain=TRUE, input_label_cols=['Loan_Status']) AS SELECT * EXCEPT(dataframe) FROM `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>` WHERE dataframe = 'training'
CREATE OR REPLACE MODEL 構文を用いてモデルを構築していきます。
OPTIONS の中に各種パラメータを定義します。
model_type には [LOGISTIC_REG] (ロジスティック回帰モデル) を選択します。
デフォルトでは、ロジスティック回帰モデルの作成に使用されるトレーニング データは重み付けされていないため、auto_class_weights を True に設定することでラベルに偏りが出てもバランスを取ってくれます。
data_split_method はトレーニングデータと評価データでデータを分けることができますが、今回は「dataframe」列を追加しデータ分割をしているため、明示的に不要としています。
enable_global_explain はモデルに対するグローバルな特徴の重要性を評価するために必要です。本検証の最後に使用するため True にしておきます。
input_label_cols はトレーニングデータのラベル列名となるため、今回は「Loan_Status」を記入します。
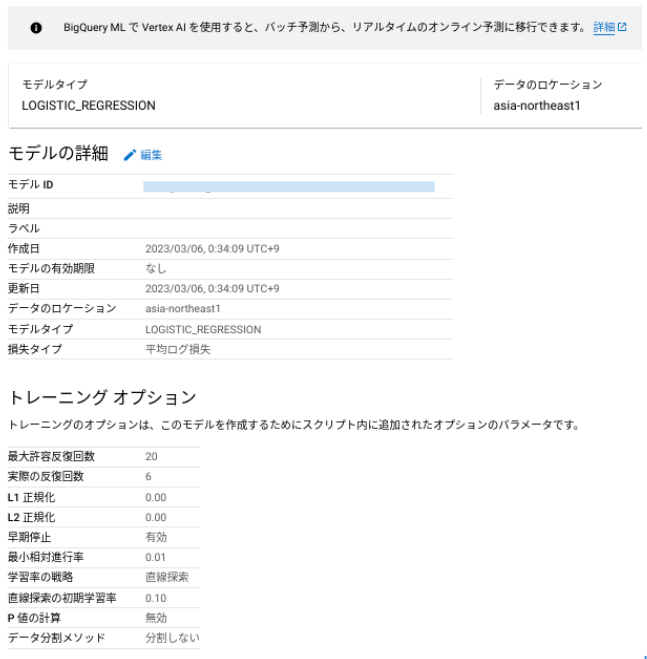
トレーニングが完了すると、モデルの結果を確認していきます。 トレーニング結果には、今回使ったモデルの詳細やトレーニングオプションについて確認することができます。
モデルの評価を確認する前に分類モデルの評価指標について軽く触れておきます。 分類モデルは主に以下の 4 つの評価指標を持ちます。
- 真陽数 (True Positive : TP):正解が「◯」のものを、「◯」と予測した回数
- 真陰数 (True Nagative : TN) :正解が「✕」のものを、「✕」と予測した回数
- 偽陽数 (False Pasitive : FP):正解が「✕」のものを、「◯」と予測した回数
- 偽陰数 (False Nagative : FN):正解が「◯」のものを、「✕」と予測した回数
上記の評価指標の組み合わせから以下のような指標が算出できます。
| No | 用語 | 概要 |
|---|---|---|
| 1 | 適合率 (Precision) | 「◯」と予測したデータのうち、正しく分類できたデータの割合。式は TP / (TP+FP) |
| 2 | 再現率 (Recall) または 真陽性率 (True Positive Tate) | 正解が「◯」だったデータのうち、正しく「◯」と予測できた割合。式は TP / (TP + FN) |
| 3 | 偽陽性率 (False Positive Rate) | 正解が「✕」だったデータを、誤って「◯」と予測した割合。 式は FP / (FP + TN) |
| 3 | 精度 (Accuracy) | 全データ数のうち、正しく分類できたデータ数の割合。よく正解率ともいいます。式は (TP + TN) / (TP + TN + FP + FN) |
| 4 | F1 スコア (f1-score) | 適合率と再現率の調和平均。式は 2×適合率×再現率 / (適合率 + 再現率) |
| 5 | ログ損失 (Log loss) | モデル予測とターゲット値の間の交差エントロピー。値が小さいほど高品質のモデルであることを示す。 |
| 6 | ROC AUC | 横軸に偽陽性率、縦軸に真陽性率を取った曲線の下の面積。0 ~ 1 の範囲を取り、値が高いほど高品質のモデルであることを示す。 |
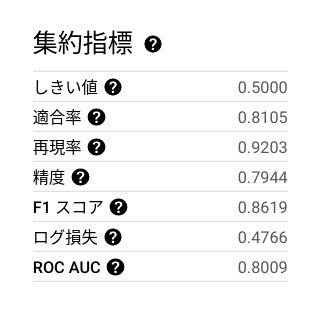
今回のモデルの評価を確認してみます。 値が 0 に近ければ高品質とされる LogLoss が 0.4766 をとり、0 ~ 1 の範囲で値が高いほど高品質とされる ROC AUC は 0.8009 をとっております。
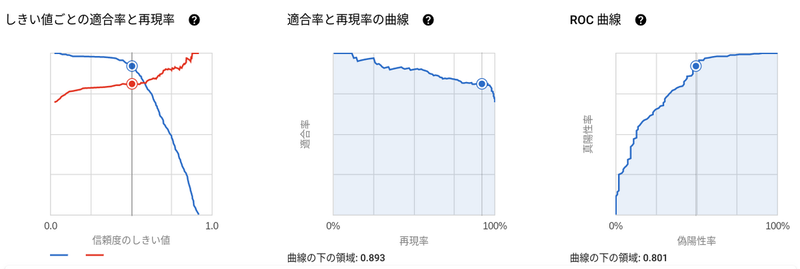
また、しきい値を変えることで適合率や再現率を調整することができます。
適合率は正解が「◯」を「✕」として分類してもよいが、正解が「✕」のものを確実に「✕」として分類したい場合に有用なので、今回のようなローンの審査において結果が False のものは極力 False と分類したいという要件があるなら重要な指標となるかと思います。
逆に再現率は正解が「✕」を「◯」と分類しても問題なく、かつ正解が「◯」は確実に「◯」として分類したい場合に有用なので、病気の診断などで再現率が重視されるケースが多いです。
このように、適合率と再現率は性質が異なるため、ユースケースに合わせて調整していく必要があります。
しかし、適合率と再現率はトレード・オフの関係であるため、適合率を極端に高めると再現率が極端に下がるのであまり良いモデルとは言えません。そこで、適合率と再現率の調和平均である F1 スコアも考慮しつつ最適なしきい値を決めていくことをおすすめします。
今回は特に要件がないため、しきい値を 0.5 として予測を行っていきたいと思います。
予測
以下の SQL を実行し予測を行います。
SELECT * FROM ML.PREDICT (MODEL `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>`, ( SELECT * EXCEPT(dataframe) FROM `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>` WHERE dataframe = 'prediction' ), STRUCT(0.5 as threshold) )
ML.PREDICT 関数 を用いて予測を行います。 STRUCT 型で threshold (しきい値) を 0.5 として設定しています。
元の列に加え、以下の 3 つの列が追加されます。
- predicted_
label_column_name:ラベルの予測結果 - predicted_
label_column_name_probs.label:ラベル (今回は True or False) - predicted_
label_column_name_probs.prob:ラベルに対応する予測確率
結果は以下のようになりました。
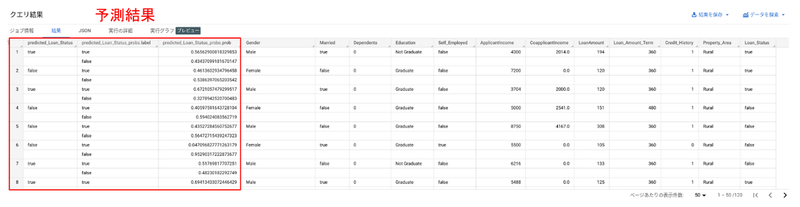
赤枠部分が今回の予測結果です。ローンの審査が通るか通らないかに対して、一番左の predicted_Loan_Status 列で、True or False が表示されています。
このように過去の教師データをもとに、機械学習モデルで予測が簡単にできました。
評価
先程予測に用いたデータには正解のラベルもあるので、予測データに対して評価も行ってみます。 以下の SQL から評価を実行できます。
SELECT * FROM ML.EVALUATE (MODEL `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>`, ( SELECT * FROM `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>` WHERE dataframe = 'prediction' ) STRUCT(0.5 as threshold) )
ML.EVALUATE関数 で評価を行います。

評価に用いる複雑な計算式が SQL 一発で出せるのは魅力的ですね。
正しく分類できたデータの割合を示す精度 (accuracy) が 81.7% でした。 他にも、適合率 (precision) や F1 スコア (f1_score) もともに 8 割を超えています。
最後に、特徴量の重要度スコアを見てみましょう。
SELECT *, ROUND(attribution *100 / ( SELECT SUM(attribution) FROM ML.GLOBAL_EXPLAIN(MODEL `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>`) ), 1) AS percentage FROM ML.GLOBAL_EXPLAIN(MODEL `<PROJECT_ID>.<DATASET_NAME>.<TABLE_NAME>`)
ML . GLOBAL_EXPLAIN関数 を用いて特徴量の重要度スコアを算出します。
特徴量の重要度スコアとは、各特徴量がどれほど影響を及ぼしているか数値化されています。
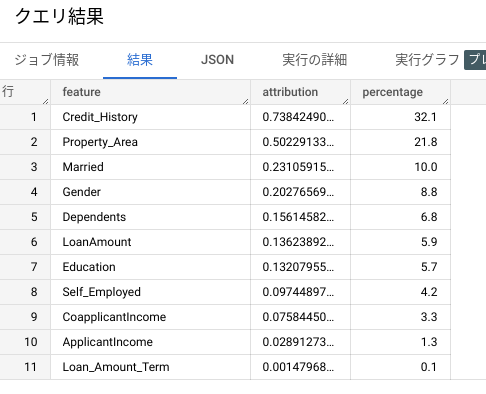
特に、以下の特徴量の影響が大きいようです。
- Credit_History (Credit history meets guidelines)
- Property_Area (Urban/ Semi-Urban/ Rural)
- Married (Applicant married)
いかがでしたでしょうか。BigQuery ML を使えば SQL を用いて、機械学習モデルの作成、予測、評価が簡単に実行できました。
又吉 佑樹(記事一覧)
クラウドソリューション部
はいさい、沖縄出身のクラウドエンジニア!
セールスからエンジニアへ転身。Google Cloud 全 11 資格保有。Google Cloud Champion Innovator (AI/ML)。Google Cloud Partner Top Engineer 2024。Google Cloud 公式ユーザー会 Jagu'e'r でエバンジェリスト。好きな分野は生成 AI。
Follow @matayuuuu