


G-gen の出口です。本記事では、Eventarc と Workflows を利用して イベントドリブンに Cloud Run jobs を実行する方法をご紹介します。

概要
Cloud Run functions と Cloud Run jobs
イベントドリブンにデータを処理するには、Cloud Run functions を使った方法などがあります。例えば、Cloud Storage にオブジェクトが格納されたら自動的に Cloud Run functions が起動するような処理を、非常に簡単に実装できます。しかし、Cloud Run functions には最大9分(イベントドリブン関数の場合)の実行時間制限があるなど、いくつかの制約があります。
当記事では、Cloud Run jobs を使ってイベントドリブンな処理を実現する検証を行いました。Cloud Run jobs には、Cloud Run functions と比較して以下のようなメリットがあります。
- 最大実行時間が168時間であること(2025年1月現在では24時間を超える処理は Preview)
- タスクの並列実行数を明示的に指定可能であること
Cloud Run jobs については以下の記事で解説していますので、ご参照ください。
また以下の記事では、Cloud Storage にテキストファイルが格納されたことを起点として Cloud Run functions を呼び出し、Vertex AI Gemini API で取得したテキストの要約結果を BigQuery に保存する処理を実装しています。
当記事では、上記記事の Cloud Run functions の部分を Cloud Run jobs に置き換えて、イベントドリブンに Cloud Run jobs を実行する構成を実装します。
検証の概要
当記事で行った検証のアーキテクチャは以下の通りです。
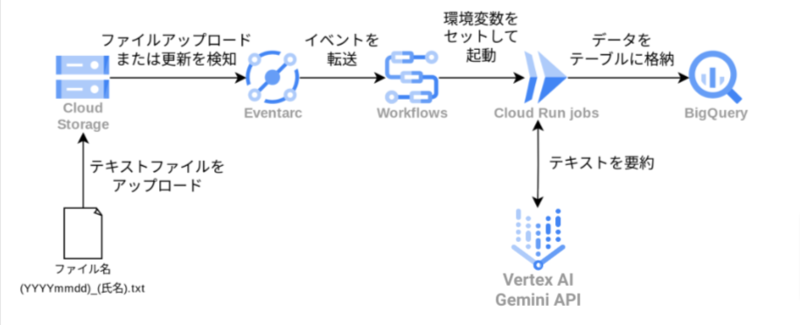
- ローカル PC から日報のテキストファイルを Cloud Storage にアップロード
- ファイルがアップロードされたことを検知して Eventarc トリガーが Workflows を起動
- Workflows が受け取ったイベント情報を環境変数にセットして Cloud Run jobs を起動
- Cloud Run jobs が Gemini で日報ファイルを要約し、結果を BigQuery テーブルに格納
Eventarc
Eventarc は Google Cloud でイベントドリブンアーキテクチャを構築するためのフルマネージドサービスです。イベントの発生元から様々な宛先への転送を、サーバレスで容易に構築できます。
- 参考 : Eventarc の概要
- 参考 : イベント ドリブン アーキテクチャ
以下の記事では Eventarc を使ったアーキテクチャの例が紹介されていますので、ご参照ください。
Workflows
Workflows(または Cloud Workflows)は Google Cloud のフルマネージドでサーバーレスなオーケストレーションサービスです。定義した順番に Cloud Run や Cloud Run functions を実行したり、BigQuery でクエリを発行するなど、様々な Google Cloud サービスを実行したり、任意の HTTP エンドポイントにリクエストを送ることができます。
- 参考 : ワークフローの概要
以下の記事で Workflows について解説していますので、ご参照ください。
Cloud Storage の準備
Cloud Storage バケットの作成
日報ファイルをアップロードするためのバケットを作成します。
バケット名に置き換えてください の部分を、作成されるバケット名に置き換えて、以下のコマンドを実行します。
BUCKET_NAME="作成されるバケット名に置き換えてください" gcloud storage buckets create gs://${BUCKET_NAME} --location=asia-northeast1
Cloud Strage サービスエージェントへの権限付与
Cloud Storage からのトリガーを作成する場合、Pub/Sub パブリッシャーのロールをプロジェクトの Cloud Storage サービスエージェントに付与する必要があります。
プロジェクト ID に置き換えてください の部分を、ご自身のプロジェクト ID に置き換えて、以下のコマンドを実行します。
PROJECT="プロジェクト ID に置き換えてください" SERVICE_ACCOUNT="$(gcloud storage service-agent --project=${PROJECT})" gcloud projects add-iam-policy-binding ${PROJECT} \ --member="serviceAccount:${SERVICE_ACCOUNT}" \ --role='roles/pubsub.publisher'
BigQuery テーブルの作成
日報データを格納するための BigQuery テーブルを作成します。
以下のコマンドでは、report という名前のデータセットと、daily_report という名前のテーブルを作成します。
# データセットを作成 bq --location=asia-northeast1 mk \ --dataset \ ${PROJECT}:report # テーブルを作成 bq mk \ --table \ --schema date:DATE,name:STRING,text:STRING \ --clustering_fields date,name \ ${PROJECT}:report.daily_report
name カラムと date カラムをクラスタ化してテーブルを作成することで、name カラムおよび date カラムでフィルタをかけるクエリを実行したときにスキャン量を削減して、パフォーマンスを向上させることができます。
Cloud Run jobs の作成
サービスアカウントの作成
Cloud Run jobs で使用するサービスアカウントを作成します。
Cloud Run jobs が Gemini API で文章を要約したり、BigQuery にデータを書き込んだり、ログを出力したりするために、以下のロールを Workflows で使用するサービスアカウントに付与する必要があります。
- BigQuery データ編集者(
roles/bigquery.dataEditor) - BigQuery ジョブユーザー(
roles/bigquery.jobUser) - Storage オブジェクト閲覧者(
roles/storage.objectViewer) - Vertex AI ユーザー(
roles/aiplatform.user) - ログ書き込み(
roles/logging.logWriter)
以下のコマンドを実行すると、sa-daily-report-job という名前のサービスアカウントが作成され、その後、必要なロールが付与されます。
gcloud iam service-accounts create sa-daily-report-job gcloud projects add-iam-policy-binding ${PROJECT} \ --member=serviceAccount:sa-daily-report-job@${PROJECT}.iam.gserviceaccount.com \ --role=roles/bigquery.dataEditor gcloud projects add-iam-policy-binding ${PROJECT} \ --member=serviceAccount:sa-daily-report-job@${PROJECT}.iam.gserviceaccount.com \ --role=roles/bigquery.jobUser gcloud projects add-iam-policy-binding ${PROJECT} \ --member=serviceAccount:sa-daily-report-job@${PROJECT}.iam.gserviceaccount.com \ --role=roles/storage.objectViewer gcloud projects add-iam-policy-binding ${PROJECT} \ --member=serviceAccount:sa-daily-report-job@${PROJECT}.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding ${PROJECT} \ --member=serviceAccount:sa-daily-report-job@${PROJECT}.iam.gserviceaccount.com \ --role=roles/logging.logWriter
Docker コンテナの作成に必要なリソースの作成
主要な処理を Python コードで実行する main.py、コード内で利用するパッケージをリスト化した requirements.txt、そして Procfile を作成します。
Procfile とは、コンテナの起動時に呼び出されるプロセスを定義するファイルで、Python で Buildpack を利用する場合においては、ファイルの作成が必須になります。Buildpack を利用すれば、Dockerfile を作成せずにコードをコンテナイメージに変換することができます。
- 参考 : Google Cloud の Buildpack
- 参考 : Procfile について
main.py
import vertexai from vertexai.generative_models import GenerativeModel, Part, SafetySetting import os import argparse from datetime import datetime import logging from google.cloud import bigquery, storage import google.cloud.logging PROJECT_ID = os.environ.get("PROJECT_ID") REGION = os.environ.get("REGION") DATASET_ID = os.environ.get("DATASET_ID") TABLE_ID = os.environ.get("TABLE_ID") TABLE_NAME = f"{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}" INPUT_BUCKET = os.environ.get("INPUT_BUCKET") INPUT_FILE = os.environ.get("INPUT_FILE") # Vertex AI の初期化 vertexai.init(project=PROJECT_ID, location=REGION) # Cloud Logging クライアントのインスタンス化 logger_client = google.cloud.logging.Client() logger_client.setup_logging() logger = logging.getLogger() logger.setLevel(logging.DEBUG) # Cloud Storage クライアントのインスタンス化 storage_client = storage.Client() # Cloud Storage からファイルを読んで Gemini に要約させる関数 def summarize_text_from_file() -> str: try: # Cloud Storage にあるファイルのテキストを読み取る bucket = storage_client.bucket(INPUT_BUCKET) blob = bucket.blob(INPUT_FILE) file_content = blob.download_as_string() text = file_content.decode("utf-8") except Exception as e: logger.error(f"Error during reading file: {e}") raise try: # Gemini に要約させる model = GenerativeModel("gemini-1.5-flash-002") generation_config = { "max_output_tokens": 500, "temperature": 0.1, "top_p": 0.1, } response = model.generate_content( f"""以下の文章を要約してください:\n{file_content}\n要約:\n""", generation_config=generation_config ) except Exception as e: logger.error(f"Error during summarization: {e}") raise return response.candidates[0].content.parts[0].text # BigQuery のテーブルにデータを挿入する関数 def insert_into_bigquery(summary_text: str): try: # ファイルの名前から日付と名前を取得する file = INPUT_FILE.split("/")[-1] # フォルダ部分を消す date_str, name_txt = file.split("_") name = name_txt.split(".")[0] try: date_object = datetime.strptime(date_str, '%Y%m%d') formatted_date = date_object.strftime("%Y-%m-%d") except ValueError: raise ValueError("Invalid filename date format. Expected YYYYMMDD.") client = bigquery.Client(project=PROJECT_ID) table_ref = client.get_table(f"{TABLE_NAME}") # 重複にならないように、データを挿入する query = f"""MERGE {TABLE_NAME} t USING ( SELECT CAST('{formatted_date}' AS DATE) AS date, '{name}' AS name, '''{summary_text}''' AS text) i ON t.date = i.date AND t.name = i.name WHEN MATCHED THEN UPDATE SET text = i.text WHEN NOT MATCHED THEN INSERT (date, name, text) VALUES (i.date, i.name, i.text)""" query_job = client.query(query) try: query_job.result() logger.debug(f"{INPUT_FILE} insert successful.") except Exception as e: logger.error(f"{INPUT_FILE} insert failed: {e}") raise except Exception as e: logger.error(f"An unexpected error occurred while insert into bigquery: {e}") raise if __name__ == "__main__": summary_result = summarize_text_from_file() insert_into_bigquery(summary_result)
requirements.txt
google-cloud-aiplatform==1.73.0 google-cloud-bigquery==3.25.0 google-cloud-logging==3.11.2
Procfile
Buildpacks では web プロセスを定義することが必須です。web プロセスを定義しなかった場合、 web process not found in Procfile というエラーが発生します。
ただし、今回は HTTP トラフィックを受信する必要がないので、実際には web プロセスは使用されません。
web: echo "no web" python: python
Artifact Registry の作成
コンテナイメージを保存するための Artifact Registry 標準リポジトリを作成します。
以下のコマンドでは、my-repo という名前のリポジトリを作成します。
gcloud artifacts repositories create my-repo \ --repository-format=docker \ --location=asia-northeast1
Artifact Registry にアップロード
Buildpack を使用してコンテナイメージをビルドし、作成した Artifact Registry リポジトリにプッシュします。
以下のコマンドでは、ソースコードをビルドし、my-repo リポジトリに daily-report-job というイメージ名でプッシュします。
gcloud builds submit --pack image=asia-northeast1-docker.pkg.dev/${PROJECT}/my-repo/daily-report-job
Cloud Run jobs の作成
以下のコマンドでは、daily-report-job という名前の Cloud Run jobs を作成します。
gcloud run jobs create daily-report-job \ --image=asia-northeast1-docker.pkg.dev/${PROJECT}/my-repo/daily-report-job:latest \ --command=python \ --args=main.py \ --region=asia-northeast1 \ --service-account=sa-daily-report-job@${PROJECT}.iam.gserviceaccount.com --set-env-vars=INPUT_BUCKET=${BUCKET_NAME},INPUT_FILE=input_file.txt,PROJECT_ID=${PROJECT},DATASET_ID=report,TABLE_ID=daily_report
環境変数 INPUT_BUCKET および INPUT_FILE は、実際には Workflows がジョブを起動する際に送られてきたイベント情報を利用してオーバーライドされます。
Workflows の作成
サービスアカウントの設定
Workflows で使用するサービスアカウントを作成します。
Workflows は環境変数をオーバーライドして Cloud Run jobs を起動し、実行結果を受け取るために、以下のロールを Workflows で使用するサービスアカウントに付与する必要があります。
- Cloud Run デベロッパー(
roles/run.developer)
なお環境変数をオーバーライドして Cloud Run jobs を起動するロールとして、上記の他に「オーバーライドを使用する Cloud Run ジョブ エグゼキュータ(roles/run.jobsExecutorWithOverrides)」ロールがありますが、こちらだと実行結果を受け取るために必要な run.executions.get 権限が不足しているため、上記のロールとしています。
以下のコマンドを実行すると、sa-cloud-run-job-workflow という名前のサービスアカウントが作成され、その後、必要なロールが付与されます。
gcloud iam service-accounts create sa-cloud-run-job-workflow gcloud projects add-iam-policy-binding ${PROJECT} \ --member=serviceAccount:sa-cloud-run-job-workflow@${PROJECT}.iam.gserviceaccount.com \ --role=roles/run.developer
ワークフローの作成
Cloud Run jobs を実行するためのワークフローを、cloud-run-job-workflow.yaml という YAML ファイルに定義します。
cloud-run-job-workflow.yaml
main: params: [event] steps: - init: assign: - project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")} - event_bucket: ${event.data.bucket} - event_file: ${event.data.name} - job_name: daily-report-job - job_location: asia-northeast1 - run_job: call: googleapis.run.v1.namespaces.jobs.run args: name: ${"namespaces/" + project_id + "/jobs/" + job_name} location: ${job_location} body: overrides: containerOverrides: env: - name: INPUT_BUCKET value: ${event_bucket} - name: INPUT_FILE value: ${event_file} result: job_execution - finish: return: ${job_execution}
ワークフローのデプロイ
以下のコマンドを実行してワークフローをデプロイします。
gcloud workflows deploy cloud-run-job-workflow \ --location=asia-northeast1 \ --source=cloud-run-job-workflow.yaml --service-account=serviceAccount:sa-cloud-run-job-workflow@${PROJECT}.iam.gserviceaccount.com
Eventarc トリガーの設定
サービスアカウントの設定
Eventarc で使用するサービスアカウントを作成します。
Eventarc は Cloud Storage からイベントを受信して Workflows を起動するため、以下のロールを Eventarc で使用するサービスアカウントに付与する必要があります。
- Eventarc イベント受信者(
roles/eventarc.eventReceiver) - ワークフロー起動元(
roles/workflows.invoker)
以下のコマンドを実行すると、サービスアカウント sa-cloud-run-job-workflow-trigger が作成され、そのサービスアカウントに必要な権限が付与されます。
gcloud iam service-accounts create sa-cloud-run-job-workflow-trigger gcloud projects add-iam-policy-binding ${PROJECT} \ --member=serviceAccount:sa-cloud-run-job-workflow-trigger@${PROJECT}.iam.gserviceaccount.com \ --role=roles/eventarc.eventReceiver gcloud projects add-iam-policy-binding ${PROJECT} \ --member=serviceAccount:sa-cloud-run-job-workflow-trigger@${PROJECT}.iam.gserviceaccount.com \ --role=roles/workflows.invoker
Eventarc の作成
以下のコマンドで、Eventarc トリガーを cloud-run-job-workflow-trigger という名前で作成します。
このコマンドでは、さきほど作成したサービスアカウント sa-cloud-run-job-workflow-trigger を指定したり、destination-workflow オプションで宛先のワークフローである cloud-run-job-workflow を指定しています。
gcloud eventarc triggers create cloud-run-job-workflow-trigger \ --location=asia-northeast1 \ --destination-workflow=cloud-run-job-workflow \ --destination-workflow-location=asia-northeast1 \ --event-filters="type=google.cloud.storage.object.v1.finalized" \ --event-filters="bucket=${BUCKET_NAME}" \ --service-account=sa-cloud-run-job-workflow-trigger@${PROJECT}.iam.gserviceaccount.com
動作確認
まずは、日報のテキストファイルを用意します。例として、以下のテキストが書き込まれたテキストファイル 20241231_山田太郎.txt を作成します。
今日の業務内容: 午前: 昨日取得したオンラインストアの顧客行動ログデータ(約5TB)のBigQueryへのロード作業を実施。Dataflowパイプラインを用いて、パーティショニングとクラスタリングを行い、クエリパフォーマンスの最適化を図った。ロード完了後、データの整合性を確認し、データ品質に問題がないことを検証した。ロード時間は予想通り約3時間であったが、一部データの重複が確認されたため、重複データ削除クエリを記述し実行。約1%の重複データが削除された。 午後: BigQuery上で顧客セグメンテーションのためのSQLクエリを開発・実行。購買頻度、平均購入額、最終購入日などを基に、"高頻度購入者", "低頻度低額購入者", "休眠顧客" の3つのセグメントに分類するクエリを作成した。各セグメントの人口統計データ(年齢、性別など)との関連性を分析するために、ユーザー属性テーブルと結合し分析を実施。 分析結果を可視化するために、Looker Studioを用いたダッシュボードを作成開始。本日中に主要指標の表示まで完了させた。 その他: プロジェクトXの今後の分析計画についてチームリーダーとミーティングを実施。 顧客チャーン予測モデル構築のためのデータ準備について議論し、必要なデータ項目とデータソースを特定した。来週から機械学習モデルの構築に着手する予定。 また、BigQueryの料金を監視し、コスト最適化のための検討を開始した。パーティショニングとクラスタリングの効果を検証し、更なる最適化の可能性を探る。 課題と問題点: データログに含まれる一部の顧客IDに重複が見られた。データ収集元でのデータクレンジングの必要性を指摘し、関係部署への報告を検討している。 Looker Studioダッシュボードの作成に時間がかかっている。より効率的な可視化ツールの検討が必要かもしれない。 明日の予定: プロジェクトX: 顧客チャーン予測モデル構築のためのデータ準備開始。必要なデータの抽出と前処理を行う。 プロジェクトY (準備段階): プロジェクトYの要件定義書作成に向けて、関係者との打ち合わせを行う。 コメント: 本日、プロジェクトXのデータ分析が大きく進展した。BigQueryとDataflowパイプラインを用いたデータ処理は効率的であった。しかし、データ品質に関する課題も浮き彫りになったため、関係部署との連携を強化し、データクオリティ向上に努める必要がある。
この日報ファイルを Cloud Storage にアップロードします。
gcloud storage cp 20241231_山田太郎.txt gs://${BUCKET_NAME}
BigQuery を見ると、テーブルに日報のデータが書き込まれていることが確認できました。
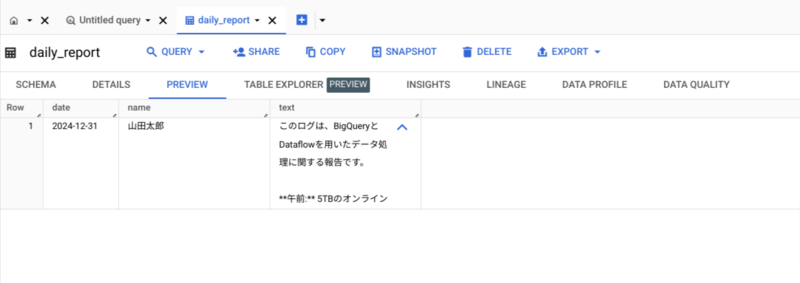
以下は、要約後の文章です。
このログは、BigQueryとDataflowを用いたデータ処理に関する報告です。 **午前:** 5TBのオンラインストリームデータのBigQueryへのロード作業を実施。Dataflowパイプラインを用いてパーティショニングとクレンジングを行い、クエリの最適化を実現しました。処理時間は予想通り約3時間でしたが、一部データの欠損が確認され、1%のデータが復旧不能でした。 **午後:** BigQuery上で、課金タイプ、平均課金額、最終課金日などを基に、「高課金ユーザー」、「低課金ユーザー」、「潜在顧客」の3つのセグメントに分類するSQLクエリを作成・実行しました。各セグメントのユーザー属性(年齢、性別など)との関連性を分析し、Looker Studioで視覚化しました。 **その他:** プロジェクトXの今後の分析計画として、チャーン予測モデルとプロモーション施策のデータ整備を決定しました。BigQueryのログを監視し、コスト最適化のための改善策を検討します。パーティショニングとクレンジングのポイントを明確化し、今後のデータ品質向上に繋げます。 **課題と問題点:** 一部の顧客IDにデータ欠損が見つかりました。データの完全性確保のため、データクレンジングとモニタリングの強化が必要です。Looker Studioでのダッシュボード作成に時間がかかっています。より効率的な可視化方法の検討が必要です。 **今後の予定:** プロジェクトXでは、チャーン予測のためのデータ整備と必要なデータの抽出・前処理を行います。プロジェクトY(チャーン予測モデル)では、要件定義書を作成し、関係者との打ち合わせを行います。 全体として、データ処理は概ね成功しましたが、データ欠損や可視化の効率性といった課題が残っており、今後の改善が必要であることが報告されています。