


G-gen の山崎です。 当記事では、Cloud Storage に格納されたテキストファイルに対して、Cloud Run functions にてVertex AI Gemini API を呼び出し、取得したテキストの要約結果を BigQuery に保存する処理を構築したので解説します。

システム構成
当記事では、Cloud Storage に格納されたテキストファイルに対して、イベントドリブンな処理を行う構成を検証したときの経緯をご紹介します。
今回構築したシステム構成は、以下のとおりです。
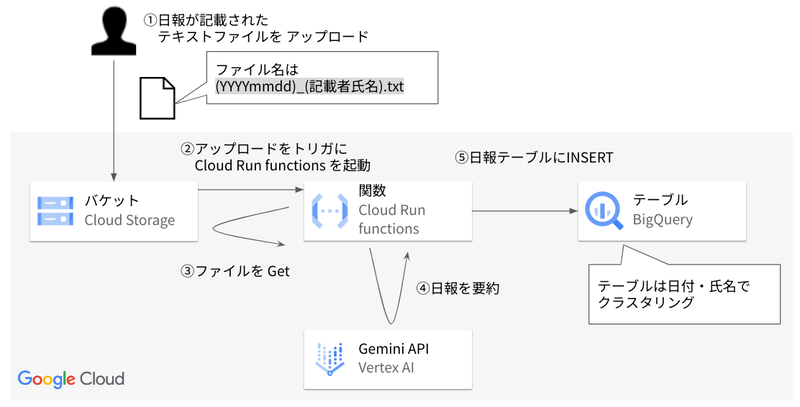
Cloud Storage の日報格納用バケットにテキストファイルがアップロードされると、それをトリガーにして Cloud Run functions が起動します。
起動した Cloud Run functions は、アップロードされたテキストファイルを Gemini で要約し、結果を BigQuery に保存します。
上記のように、ある1つの処理が完了したことをきっかけに、別の処理がトリガーされるようなアーキテクチャをイベントドリブンといいます。スケジュール起動のバッチ処理等に比べて、タイムラグなく処理を行うことが可能です。
前提知識
今回使用する Google Cloud サービスの詳細は、以下の記事をご参照ください。
Cloud Storage
Cloud Run functions
BigQuery
環境構築
以下の順序で環境を構築しました。
- API の有効化
- Cloud Storage の構築
- BigQuery の構築
- Cloud Run functions の構築
API の有効化
Google Cloud プロジェクトで、今回の構成に必要な Google Cloud サービスの API を有効化します。
gcloud services enable \ artifactregistry.googleapis.com \ cloudfunctions.googleapis.com \ run.googleapis.com \ logging.googleapis.com \ aiplatform.googleapis.com \ cloudbuild.googleapis.com \ storage.googleapis.com \ pubsub.googleapis.com \ eventarc.googleapis.com \
Cloud Storage の構築
バケットの作成
日報を格納するバケットを作成します。
以下のコマンドラインを用いました。実行する際には、変数 BUCKET_NAME、PROJECT_ID の値をご自身の環境に合わせて置き換えてください。
BUCKET_NAME="BUCKET_NAME" PROJECT_ID="PROJECT_ID" gcloud storage buckets create gs://${BUCKET_NAME} \ --project=${PROJECT_ID} \ --location=asia-northeast1
Cloud Storage サービスエージェントに権限付与
Cloud Storage のサービスエージェントに対し、 Pub/Sub へパブリッシュするための IAM 権限を付与します。
PROJECT_ID の値をご自身の環境に合わせて置き換えてください。
PROJECT_ID="PROJECT_ID" SERVICE_ACCOUNT="$(gcloud storage service-agent --project=${PROJECT_ID})" gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${SERVICE_ACCOUNT}" \ --role='roles/pubsub.publisher'
この作業の意味については、以下の記事の Cloud Storage サービスエージェントに権限付与 の項をご参照ください。
BigQuery の構築
日報の要約結果を保存するための BigQuery データセットとテーブルを作成します。作成するテーブルのスキーマ構成は以下のとおりです。
| 列名 | データ型 | 説明 |
|---|---|---|
| report_date | DATE | 日付 |
| name | STRING | 名前 |
| original_text | STRING | 日報の原文 |
| summary | STRING | 日報の要約 |
以下のコマンドラインを用いました。実行する際は、PROJECT_ID の値をご自身の環境に合わせて置き換えてください。
PROJECT_ID="PROJECT_ID" # データセットの作成 bq --location=asia-northeast1 mk \ --dataset test # テーブルの作成 bq mk \ --table \ test.report \ report_date:DATE,name:STRING,original_text:STRING,summary:STRING
Cloud Run functions の構築
Python のバージョン
この記事では、Python 3.12.0 を使用しました。
$ python --version Python 3.12.0
requirements.txt の作成
以下のライブラリを requirements.txt に定義します。requirements.txt は、Python のソースコードから利用するライブラリの依存関係を定義したテキストファイルです。
functions-framework==3.5.0 google-cloud-aiplatform==1.60.0 google-cloud-bigquery==3.19.0 google-cloud-logging==3.9.0 google-cloud-storage==2.5.0 pandas-gbq==0.20.0 pandas==2.1.4
main.py の作成
ソースコードは以下のとおりです。15行目から25行目で参照している環境変数は、Cloud Run functions のデプロイ時に値を設定します。
import functions_framework import google.cloud.logging import logging import os import pandas as pd import pandas_gbq import vertexai from datetime import datetime, timezone, timedelta from google.cloud import bigquery from google.cloud import storage from vertexai.preview.generative_models import GenerativeModel # 環境変数を一箇所にまとめる ENV = { 'PROJECT_ID': os.environ.get('PROJECT_ID'), 'LOCATION': os.environ.get('LOCATION'), 'TEMPERATURE': float(os.environ.get('TEMPERATURE')), 'MAX_OUTPUT_TOKENS': int(os.environ.get('MAX_OUTPUT_TOKENS')), 'TOP_P': float(os.environ.get('TOP_P')), 'TOP_K': int(os.environ.get('TOP_K')), 'LOG_LEVEL': int(os.environ.get('LOG_LEVEL')), 'MODEL': os.environ.get('MODEL'), 'TABLE_ID': os.environ.get('TABLE_ID'), } # ロギング設定 logging.basicConfig(level=ENV['LOG_LEVEL']) logger = logging.getLogger() # Vertex AI の初期化 vertexai.init(project=ENV['PROJECT_ID'], location=ENV['LOCATION']) model = GenerativeModel(ENV['MODEL']) # BigQuery のクライアントを作成 bigquery_client = bigquery.Client() def download_from_gcs(bucket_name, object_name): """GCS からファイルをダウンロードする""" storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) blob = bucket.blob(object_name) return blob.download_as_string().decode('utf-8') def generate_summary(text): """Vertex AI を使用してテキストを要約する""" prompt = f"以下の文章を要約してください:\n{text}\nSummary:\n" responses = model.generate_content( prompt, generation_config={ "temperature": ENV['TEMPERATURE'], "max_output_tokens": ENV['MAX_OUTPUT_TOKENS'], "top_p": ENV['TOP_P'], "top_k": ENV['TOP_K'], } ) return responses.text def save_to_bigquery(report_date, name, original_text, summary): """BigQuery にデータを保存する""" records = [ {"report_date": report_date, "name": name, "original_text": original_text, "summary": summary} ] df = pd.DataFrame(records) df['report_date'] = pd.to_datetime(df['report_date'], errors='coerce') pandas_gbq.to_gbq(df, ENV['TABLE_ID'], ENV['PROJECT_ID'], if_exists='append') return @functions_framework.cloud_event def main(cloud_event): # イベントデータの取得 event_data = cloud_event.data bucket_name = event_data["bucket"] object_name = event_data["name"] # ファイル情報のパース file_name = os.path.splitext(object_name)[0] report_date, name = file_name.split("_", 1) # ファイル名から日付と名前を抽出 # GCS からデータを取得 data = download_from_gcs(bucket_name, object_name) # 要約の生成 summary = generate_summary(data) # BigQuery に結果を保存 save_to_bigquery(report_date, name, data, summary) logger.info("処理終了!") return
サービスアカウントの作成(Cloud Run functions 起動用)
アップロードをトリガーに Cloud Run functions を起動するサービスアカウントを作成します。
実行する際は、PROJECT_ID の値をご自身の環境に合わせて置き換えてください。
PROJECT_ID="PROJECT_ID" SERVICE_ACCOUNT_NAME=fnc-trigger # サービスアカウントの作成 gcloud iam service-accounts create ${SERVICE_ACCOUNT_NAME} \ --description="トリガー用サービスアカウント" \ --display-name=${SERVICE_ACCOUNT_NAME} # サービスアカウントへ権限付与 gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/run.invoker" gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/eventarc.eventReceiver"
サービスアカウントの作成(Cloud Run functions 実行用)
Cloud Run functions を実行するサービスアカウントを作成します。
実行する際は、PROJECT_ID の値をご自身の環境に合わせて置き換えてください。
PROJECT_ID="PROJECT_ID" SERVICE_ACCOUNT_NAME=register-daily-report # サービスアカウントの作成 gcloud iam service-accounts create ${SERVICE_ACCOUNT_NAME} \ --description="Cloud Run functions実行用サービスアカウント" \ --display-name=${SERVICE_ACCOUNT_NAME} # サービスアカウントへ権限付与 gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/bigquery.jobUser" gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/bigquery.dataEditor" gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/storage.objectViewer" gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member="serviceAccount:${SERVICE_ACCOUNT_NAME}@${PROJECT_ID}.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"
Cloud Run functions のデプロイ
Cloud Run functions をデプロイします。
実行する際は、PROJECT_ID の値をご自身の環境に合わせて置き換えてください。またソースコードや requirements.txt が存在するディレクトリに移動してからコマンドを実行してください。
PROJECT_ID="PROJECT_ID" BUCKET="BUCKET_NAME" function=register-daily-report service_account=register-daily-report trigger_service_account=fnc-trigger gcloud functions deploy ${function} \ --gen2 \ --project=${PROJECT_ID} \ --region=asia-northeast1 \ --runtime=python312 \ --memory=512Mi \ --entry-point main \ --timeout=540 \ --trigger-bucket=${BUCKET} \ --service-account=${service_account}@${PROJECT_ID}.iam.gserviceaccount.com \ --trigger-service-account=${trigger_service_account}@${PROJECT_ID}.iam.gserviceaccount.com \ --set-env-vars LOG_EXECUTION_ID=true,PROJECT_ID=${PROJECT_ID},LOCATION=asia-northeast1,LOG_LEVEL=20,TEMPERATURE=1.0,MAX_OUTPUT_TOKENS=800,TOP_P=0.95,TOP_K=40,MODEL=gemini-1.5-flash-001,TABLE_ID=${PROJECT_ID}.test.report
動作検証
検証に使用したダミー日報
ダミーの日報データとして、以下のテキストファイルを使用します。
日報 日付 2024年9月10日 名前 営業一郎 業務報告 お疲れ様です。本日の活動について報告いたします。 本日午前中は、Z社との初回ミーティングを行いました。 Z社は我々の製品群に大いに興味を示しており、特にエコ効率とコスト効率について熱心に問い合わせがありました。 Z社の要望に対し、製品の特性を強調し、彼らの課題解決に最適な提案を行いました。 ミーティングの結果、Z社はさらに具体的な提案を求めてきましたので、次回は製品デモンストレーションを実施する予定です。 また午前中には、製品開発部門との内部ミーティングを行い、顧客からのフィードバックを共有しました。 これにより、製品改良のための具体的な提案を開発部門に伝えることができ、 これらのフィードバックが新製品開発に役立つと確信しています。 午後には、既存の大口顧客であるY社へ訪問しました。 我々の製品が彼らの業務改善にどのように寄与しているか、また、どのような改善が求められているのかを詳細に確認しました。 Y社からのフィードバックは非常に貴重であり、これを元に顧客満足度の向上、そして新製品開発の方向性に活かしていきたいと考えています。 最後に、R社との商談を進めました。 R社は最初から我々の製品に大いに期待していましたが、今日の商談でその期待をさらに上回る提案ができたと感じています。 製品の特性と価値をしっかりと伝え、R社の問題解決に対する当社のコミットメントを強調しました。 これにより、R社からは高い評価を頂き、次回の商談の設定を成功させることができました。 本日も新規顧客開拓や既存顧客との信頼関係強化に努めました。 今後も引き続き、我々の製品とサービスが顧客のビジネスにとって最大の価値を提供することを目指してまいります。 以上、本日の報告となります。よろしくお願いいたします。
検証の実施
日報格納用バケットにテキストファイル(ダミー日報)をアップロードします。
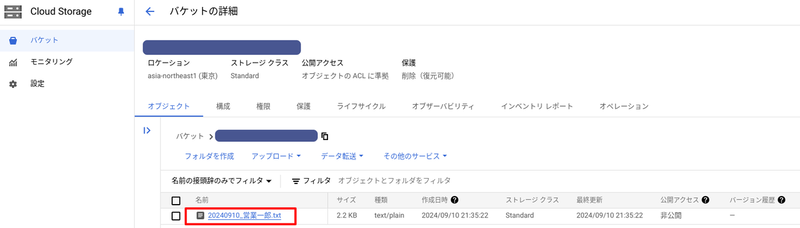
アップロードされた日報の原文と要約後の文章が、BigQuery に保存されていることを確認します。
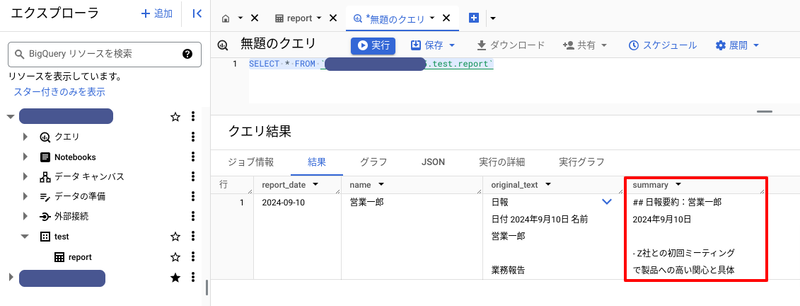
以下は、要約後の文章です。
## 日報要約:営業一郎 2024年9月10日 - Z社との初回ミーティングで製品への高い関心と具体的な提案を求められる。次回製品デモンストレーションを実施予定。 - 製品開発部門とのミーティングで顧客フィードバックを共有し、新製品開発に繋げる。 - 大口顧客Y社への訪問で顧客満足度向上と新製品開発の方向性に関する貴重なフィードバックを得る。 - R社との商談で期待以上の提案を行い、高い評価と次回商談設定に成功。 - 新規顧客開拓と既存顧客との信頼関係強化に積極的に取り組み、顧客ビジネスへの貢献を目指す。
なお、ダミー日報を Cloud Storage バケットにアップロードしてから、BigQuery に要約文が保存されるまでは、30秒もかかりませんでした。イベントドリブンな構成を取ることで、タイムラグのない逐次処理を実現できることがわかります。
山崎 曜(記事一覧)
クラウドソリューション部
元は日系大手SIerにて金融の決済領域のお客様に対して、PM/APエンジニアとして、要件定義〜保守運用まで全工程に従事。
Google Cloud Ambassador、Google Cloud Partner Top Engineer 2025 & 2026(Fellow) 選出。Google Cloud 14 資格保有。
フルスタックな人材を目指し、日々邁進。