


G-gen の杉村です。BigQuery に対して自然言語で問い合わせする方法の1つである、BigQuery remote MCP server を、Gemini CLI を使って検証してみた結果を紹介します。

はじめに
BigQuery remote MCP server とは
BigQuery remote MCP server とは、Google Cloud が管理するインフラ上で起動するリモート MCP サーバー群である Google Cloud MCP Servers の1つです。BigQuery に対して、CLI ツールや IDE といった MCP クライアントを介して、自然言語によるクエリを投入することができます。
Google Cloud MCP Servers では、BigQuery の他にも、Compute Engine や Google Kubernetes Engine(GKE)、Google Maps などのための MCP サーバーが提供されています。詳細は以下の記事を参照してください。
料金に関する注意点
BigQuery remote MCP server を使って BigQuery に対してクエリを実行すると、BigQuery の利用料金が発生します。
BigQuery の利用料金は、デフォルトのオンデマンド課金モードでは、スキャン量に応じた従量課金です。オプショナルな BigQuery Editions を使用していると、事前に設定した上限に基づいてスロットを消費し、その分に応じた課金が行われます。
特に、サイズの大きいテーブル等にはパーティションと、パーティションフィルタ要件(Partition filter requirements)を設定するなどして、意図せず大きなクエリ(フルスキャン)が発生しないように対策をしておくことが推奨されます。
準備作業
当記事の検証では、MCP クライアントとして Gemini CLI を使用します。Gemini CLI については、以下の記事を参照してください。
Gemini CLI から BigQuery remote MCP server を使用するため、セットアップとして以下の作業を行いました。
- Google Cloud プロジェクトで BigQuery remote MCP server を有効化
- Gemini CLI の構成ファイル(
.gemini/settings.json)に MCP サーバーの情報を追記 - アプリケーションのデフォルト認証情報(ADC)を設定
上記の手順の詳細は、以下の記事で紹介されています。設定作業には、5分もかかりませんでした。
単一テーブルに対する集計
質問の投入
Gemini CLI に対して、以下のようなクエリを自然言語で投入します。なお当記事では、Google Cloud プロジェクト名を my-project で統一しています。まずは、あえてデータセット名やテーブル名を指定せずに、質問を投入します。
`my-project` プロジェクトの BigQuery から、以下を調べて。
Cloud Audit Logs から、過去1週間に実行された API リクエストのうち、最も使われた Google Cloud サービスを特定して。
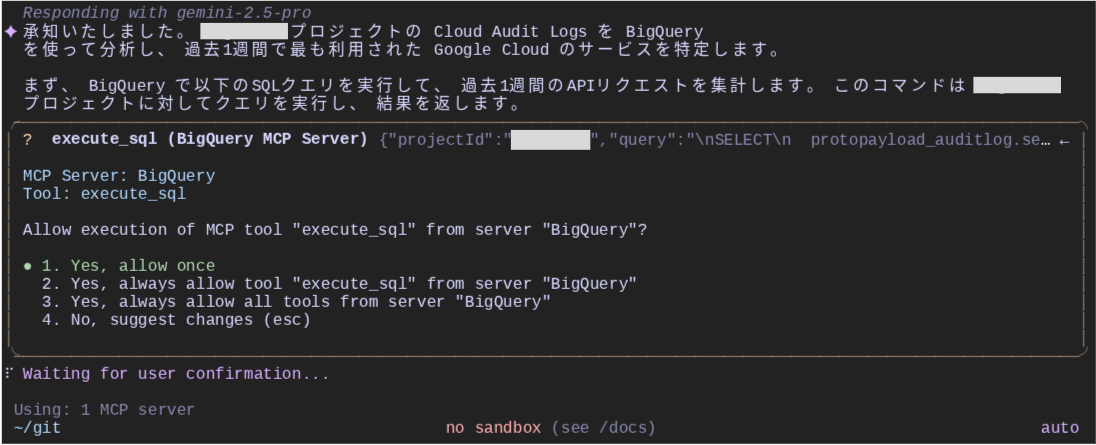
最初のトライ
Gemini は、まずはあてずっぽうのデータセット名とテーブル名を指定してクエリを実行しようとしました。execute_sql は、BigQuery に対して SQL を実行するツールです。このクエリは、存在しないテーブルを指定しているので失敗します。
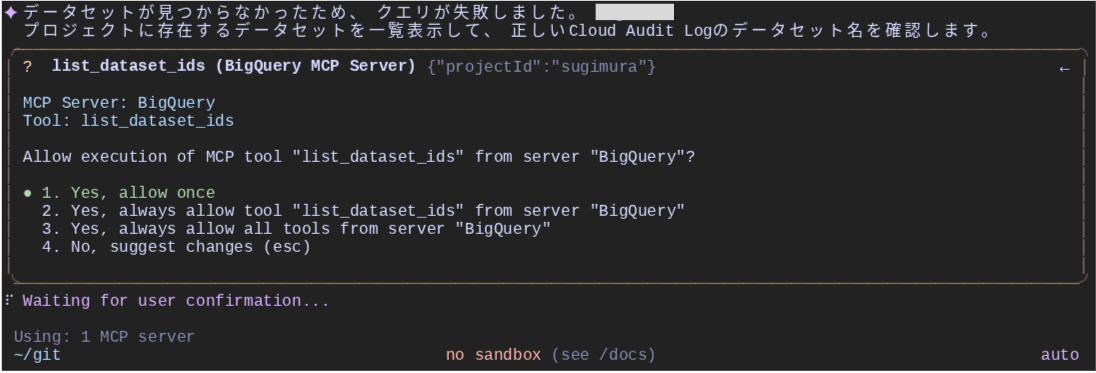
データセットとテーブルの特定
クエリがうまくいかなかったため、データセットとテーブルを特定するため、データセットをリストアップするツールである list_dataset_ids を使用しようとします。
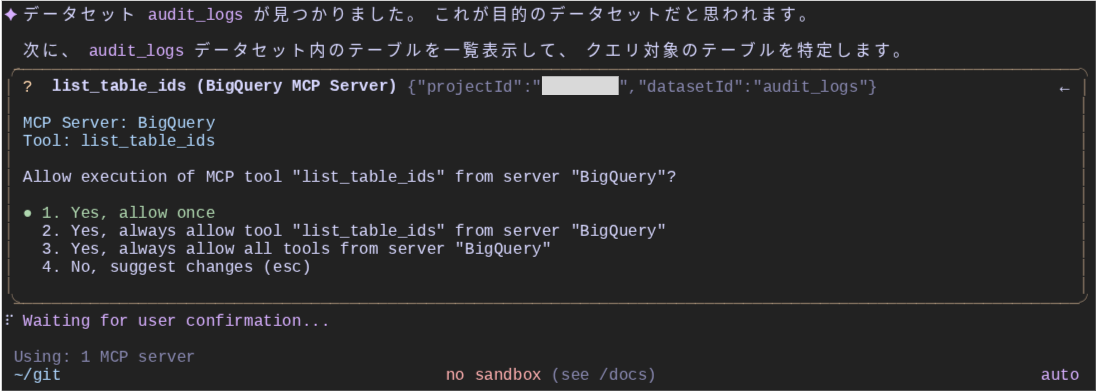
データセット名がわかったため、次はテーブル ID をリストアップするために list_table_ids ツールを使用しています。
集計の実行
目当てのテーブルがわかったため、再度 execute_sql を使い、集計 SQL を実行します。
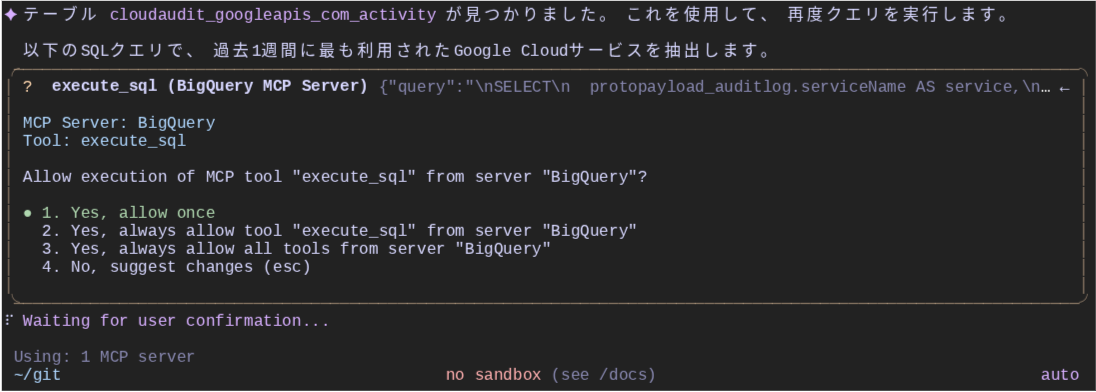
期待した結果が表示されました。なお、最初からデータセット ID とテーブル ID を指定すれば、調査のステップを省略して集計を実行してくれます。
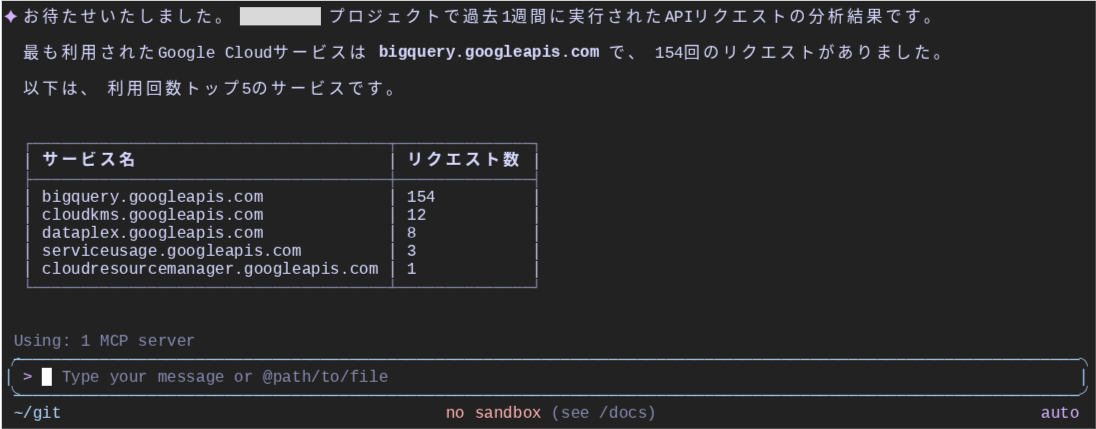
結合を伴うクエリ
テーブルの準備
次に、複数のテーブルの結合を伴うようなクエリも想定します。
my_dateset_tokyo データセットに、以下のようなテーブルを用意しました。架空の顧客マスターと、注文履歴です。
customers
| id | name | industry | area |
|---|---|---|---|
| 1 | 株式会社AAA | IT・通信 | 東京都 |
| 2 | BBB商事株式会社 | 卸売・小売 | 大阪府 |
| 3 | 北海道CCCフーズ | 飲食・サービス | 北海道 |
| 4 | 福岡DDDクリエイティブスタジオ | 広告・出版 | 福岡県 |
| 5 | 名古屋EEE工業 | 製造 | 愛知県 |
orders
| id | timestamp | customer_id | item |
|---|---|---|---|
| 1001 | 2025-12-01 09:30:00.000000 UTC | 1 | ボールペン |
| 1002 | 2025-12-01 10:15:00.000000 UTC | 2 | A4コピー用紙 |
| 1003 | 2025-12-01 14:00:00.000000 UTC | 1 | 付箋 |
| 1004 | 2025-12-02 11:20:00.000000 UTC | 3 | ボールペン |
| 1005 | 2025-12-02 13:45:00.000000 UTC | 5 | 油性マーカー |
※いずれのテーブルも省略されており、先頭5行のみ
質問の投入
Gemini CLI に対して、以下のようなクエリを自然言語で投入します。検証のためあえて2つの指示を与えましたが、LLM に複雑な指示を与える際は、1回の実行につき1個の目的を達成させるほうが望む結果を得られやすい点に留意してください。
`my-project` プロジェクトの BigQuery データセット
my_dateset_tokyoから、以下を調べて。
- 2025年12月に最も売れた商品のトップ5
- 最も商品を購入している顧客
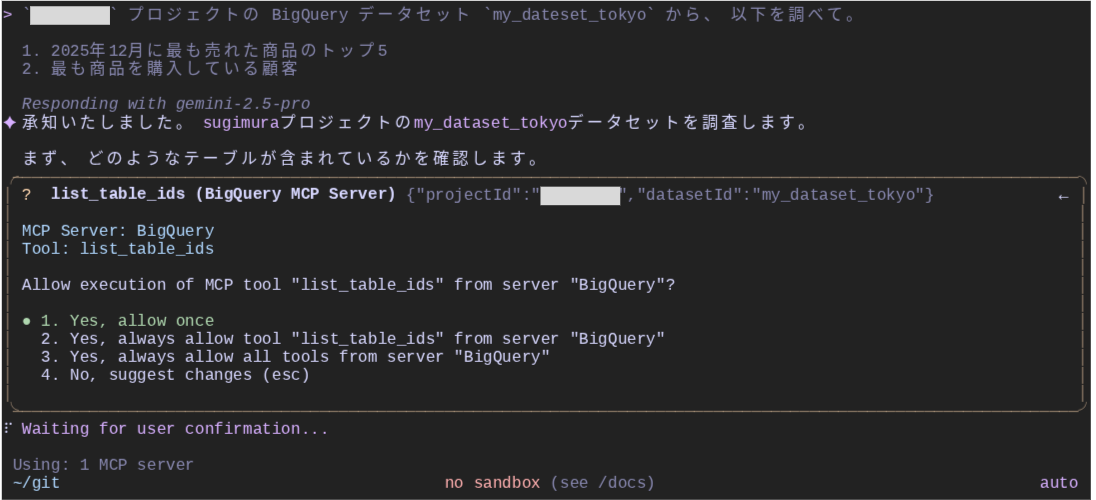
まず Gemini は、テーブルの特定から始めようとしています。対象データセット ID は既に与えられているため、list_table_ids ツールを使ってどのようなテーブルが存在するかを確認します。
スキーマ情報の確認
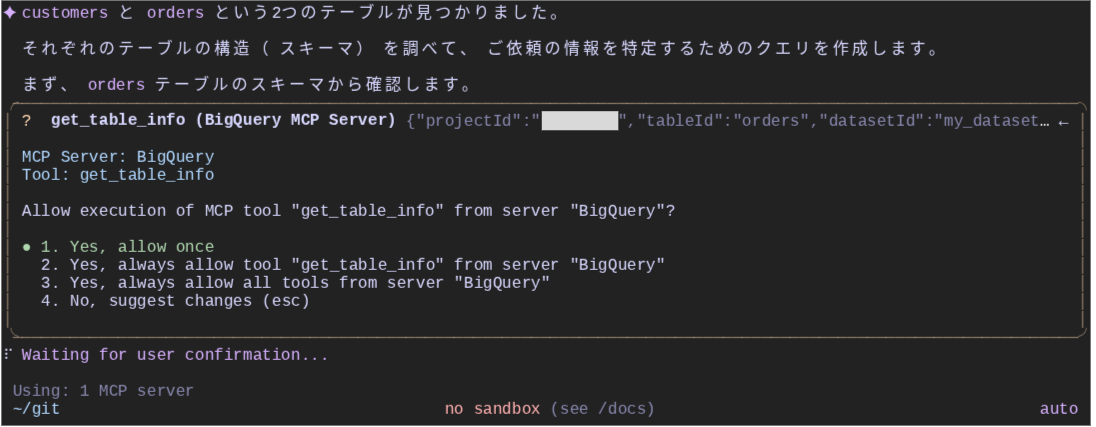
次に、get_table_info ツールを使い、テーブルのスキーマ情報(列名やメタデータ等)を確認します。該当テーブルには、各列に Description(説明)が文字列で付与されており、このメタデータを取得して、Gemini は実行すべき作業を判断します。
最初の集計クエリ
「2025年12月に最も売れた商品のトップ5」という質問に対しては、orders テーブルのみのクエリで事足りるため、まずは同テーブルに対して execute_sql ツールで集計を実施しています。
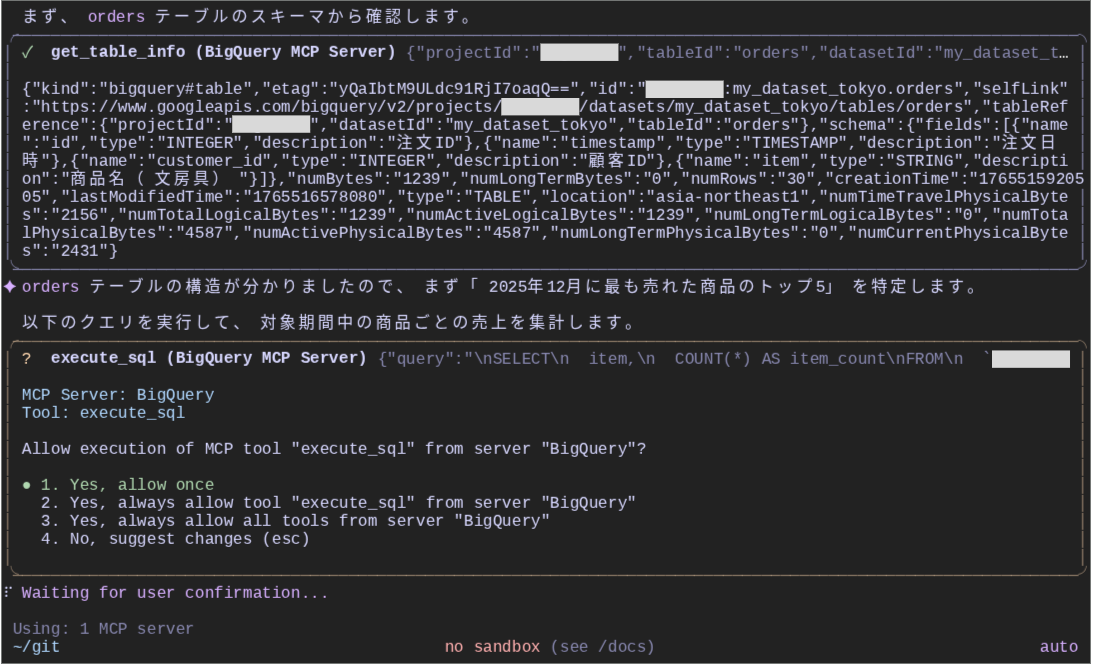
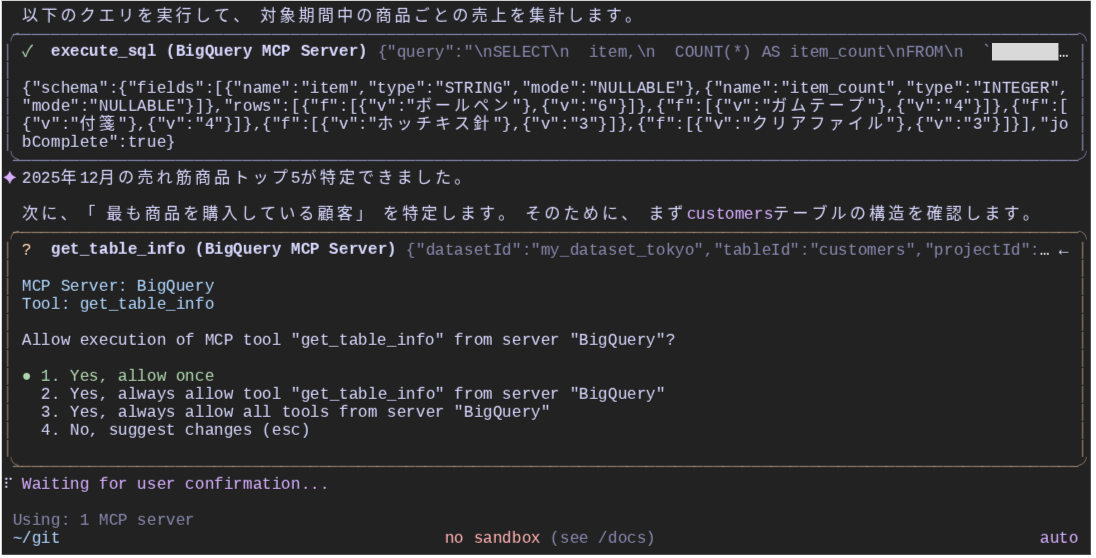
結合クエリ
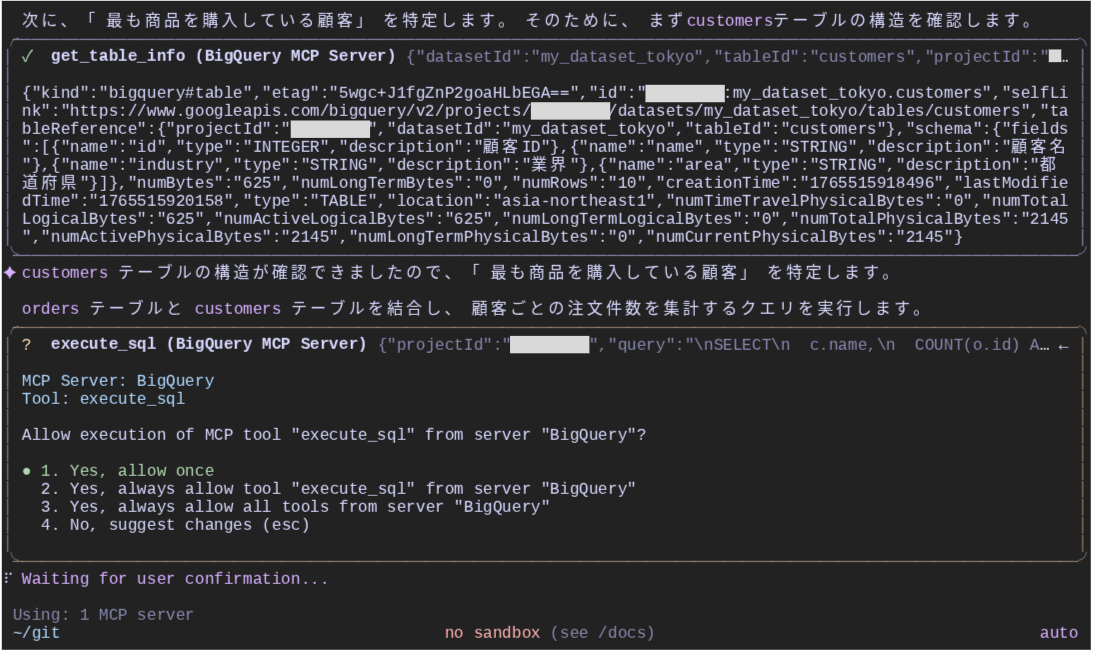
次に、「最も商品を購入している顧客」という質問に対する答えを得るため、customers テーブルのスキーマ情報を get_table_info ツールで確認しています。
2つのテーブルを結合するクエリを execute_sql ツールで実行します。
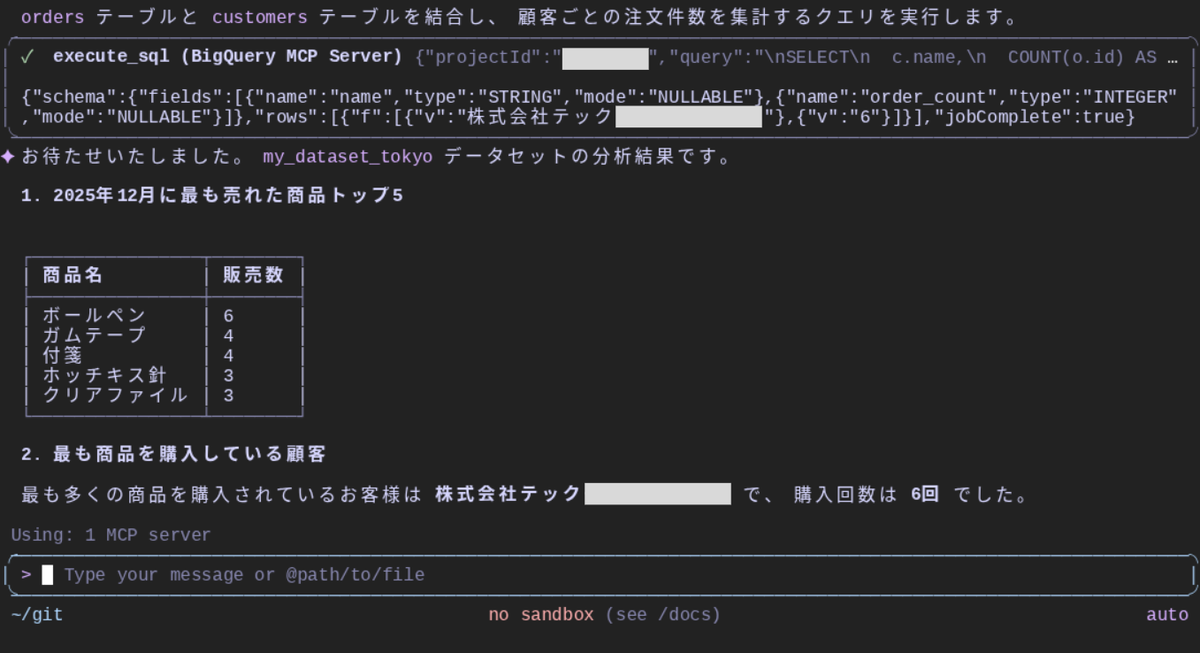
結果の表示
最終的な集計結果が表示されました。
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it