


G-gen の杉村です。Google Cloud (旧称 GCP) の PostgreSQL 互換のフルマネージドサービスである AlloyDB for PostgreSQL について解説します。
- 概要
- アーキテクチャ
- 可用性
- スケーラビリティ
- 分析(OLAP)
- バックアップ・リストア
- 接続
- データのインポート・エクスポート
- AI 機能
- セキュリティ・監査
- 運用とモニタリング
- チューニング
- Cloud SQL からの移行
- AlloyDB Omni

概要
AlloyDB とは
AlloyDB for PostgreSQL は、Google Cloud が提供する高性能な PostgreSQL 互換のフルマネージドサービスです。様々なアプリケーションから高性能なオペレーショナルデータベースとして利用できます。
Cloud SQL と同じく DBaaS(DB as a Service)として分類することができますが、AlloyDB はパフォーマンス・可用性・スケーラビリティの面で通常の PostgreSQL よりも優れており、特に厳しい非機能要件があるエンタープライズシステムに対応できるデータベースとして位置づけられています。
- 参考 : AlloyDB の概要
AlloyDB はストレージ機構などに独自の技術が使用されており、その性能は標準の PostgreSQL と比較してトランザクション処理では「4倍以上高速」、分析処理では「最大100倍高速」と公称されています。またバックアップ、パッチ適用、ストレージの拡張など多くの運用タスクが自動化されており、運用の容易さも特徴です。可用性 SLA は 99.99% です。
- 参考 : AlloyDB for PostgreSQL の仕組み: データベース対応のインテリジェントなストレージ
- 参考 : AlloyDB Service Level Agreement (SLA)
サービスの位置づけ
Google Cloud のフルマネージドのデータベースサービスとしては、他に Cloud SQL がありますが、AlloyDB は特に高いパフォーマンスが求められるシステムに対応できるデータベースとして位置づけられています。
このサービス展開は、Amazon Web Services(AWS)において、Amazon RDS と Amazon Aurora が別個に存在するのと似ています。Google Cloud サービスとしての位置づけは、Amazon RDS が Cloud SQL、Amazon Aurora が AlloyDB にそれぞれ対応していると考えて良いでしょう。
なお名前に for PostgreSQL と冠してはいますが、他の DB エンジン版の AlloyDB の提供は今のところありません。
Cloud SQL についての詳細は、以下の記事を参照してください。
PostgreSQL との互換性
2026年1月現在では、PostgreSQL 14、15、16、17、18 との互換性を持った AlloyDB クラスタを構築できます。
AlloyDB は PostgreSQL との「100% 互換」を謳っています。AlloyDB のデータベースへの接続には、psql コマンドラインなどの PostgreSQL 用クライアントを用いることができます。また AlloyDB は、PostgreSQL の各種パラメータや拡張機能(extension)に対応しています。
通常の PostgreSQL では postgresql.conf 等で設定する各種パラメータは、AlloyDB ではデータベースフラグと呼ばれる設定値として管理され、Web コンソールや gcloud コマンドで管理します。
既存の PostgreSQL データベースから AlloyDB への移行を検討する際、パラメータや拡張機能が AlloyDB でも利用可能なのか、以下の公式ドキュメントで確認する必要があります。
料金
AlloyDB は、利用した分だけ料金が発生する従量課金です。以下の軸で課金されます。
- 割り当てた CPU/Memory
- 利用したストレージ (バックアップ用含む)
- ネットワーク (他リージョンへの egress のみ)
AlloyDB には「プライマリインスタンス」と「読み取りプールノード」が存在し、それぞれスペック(CPU、Memory)を指定できます。インスタンスが存在した時間に応じ、時間単位で課金が発生します。
またストレージはデータベースに必要な分のサイズが自動的に割り当てられ、自動でスケールアップ・ダウンします。利用したデータサイズ分だけの課金が発生します。
以下は、N2 または C4A マシンタイプにおける 2 vCPU / 16 GB のプライマリインスタンス + スタンバイインスタンスという構成で、ストレージ利用が 100 GB の場合の利用料金の試算です(2026年1月現在、東京リージョン)。
- vCPU: $0.08458 * 2 vCPU * 730h * 2 VMs = $246.9736 /月
- Memory: $0.01434 * 16 GB RAM * 730h * 2 VMs = $334.9824 /月
- Storage: $0.000526 * 100 GB * 730h = $38.398 /月
→ 計 $620.354 /月
上記に加えて、バックアップストレージにも課金が発生します。
最新の料金は、以下の公式ページをご参照ください。
無料トライアル
AlloyDB では無料トライアルクラスタ(free trial clusters)を作成可能です。
無料トライアルクラスタでは 8 vCPU と最大 1 TB のストレージを利用でき、30日間の試用が可能です。SLA は適用されず、バックアップも取得できませんが、有償版とほとんど同等の機能を使うことができます。
無料期間中の30日が経過した後は、データベースへのリクエストが受け付けられなくなり、そこから15日後にはデータも削除されます。無料クラスタは、有償クラスタにアップグレードすることが可能です。
無料トライアルクラスタの作成には、有効な請求先アカウントと紐づけられた Google Cloud プロジェクトが必要です。
アーキテクチャ
クラスタ
AlloyDB for PostgreSQL の基本の管理単位はクラスタです。クラスタの全体像は以下の図の通りです。

- 参考 : AlloyDB の概要
プライマリインスタンス
クラスタはプライマリインスタンスを持ちます。プライマリインスタンスはクラスタに1つだけですが「高可用性」設定にすると、フェイルオーバ用のレプリカ(スタンバイインスタンス)を持つことができます。
クライアントは読取・書込アクセスをこのプライマリインスタンスに向けて行います。そのための単一の IP アドレスが発行されます。IP アドレスはフェイルオーバしても変わりません。
プライマリインスタンスのスタンバイインスタンスが存在するクラスタを「高可用性(High available)クラスタ」と呼び、単一のプライマリインスタンスしか持たないクラスタを「基本(Basic)クラスタ」と呼びます。なおサービスリリース当初は高可用性クラスタのみでしたが、2023年9月21日のアップデートにより、基本クラスタが作成可能になりました。
読み取りプールインスタンス
読み取りプールインスタンス(Read pool instance)は、読取専用アクセスを提供するノードの集合体です。つまり読み取りプールインスタンスという語は単一のノードを指すのではなく、読取専用ノードのグループを指します。
読み取りプールインスタンスには読取用の IP アドレスが発行され、その IP アドレスへのアクセスは読み取りプールインスタンスのいずれかのノードに割り振られます。ノードの数を増減することで、読取ワークロードを負荷分散することが可能です。
プライマリインスタンスは必須ですが、読み取りプールインスタンスの作成は任意です。作成すると利用料金が発生する代わりに、分析的な用途を含む読取ワークロードを分散させることができます。
また、AlloyDB の読み取りプールインスタンスには、オートスケーリングを設定できます。CPU 使用率またはスケジュールに基づいて、読み取りプールインスタンス内のノード数を自動的に増減できます。
ネットワーク
AlloyDB のクラスタはユーザが管理する VPC(Virtual Private Cloud)ネットワークの中ではなく、Google Cloud が管理する VPC ネットワークの中に作成されます。
ユーザの VPC ではなく Google Cloud が管理するマネージドな VPC であるという点がポイントです。これは、プライベートサービスアクセスという仕組みであり、クラスタが配置される Google Cloud 管理の VPC をサービスプロデューサーのネットワークと呼びます。これは Cloud SQL や Cloud Memorystore などと同じ仕組みです。
サービスプロデューサーのネットワークとユーザの VPC ネットワークは、VPC ネットワークピアリングで接続することになります。

- 参考 : プライベート IP の概要
- 参考 : プライベート サービス アクセスの概要
なお AlloyDB へは、プライベートサービスアクセスを使う接続方法の他に、パブリック IP アドレスを使用して接続する方法や、Private Service Connect を用いて接続する方法もあります。
クロスリージョンレプリケーション
AlloyDB ではオプションとして、クロスリージョンレプリケーションを利用可能です。クロスリージョンレプリケーションを有効化すると、メインのクラスタ(プライマリクラスタ)とは別のリージョンにセカンダリクラスタが作成され、非同期でデータがレプリケーションされます。
セカンダリクラスタは読み取り専用のクラスタであり、手動でプライマリに昇格させることができます。
クロスリージョンレプリケーションは災害対策目的のほか、ユーザやアプリケーションに近いリージョンに読み取り専用のセカンダリクラスタを置くことで、読み取りレイテンシの改善にも用いることができます。
- 参考 : クロスリージョン レプリケーションの概要
可用性
スタンバイインスタンス
前述の通り、プライマリインスタンスは任意でフェイルオーバ用レプリカ(スタンバイインスタンス)を持つことができます。
アクティブ系のプライマリインスタンスに異常が検知されると、自動的にスタンバイインスタンスにフェイルオーバが発生します。
フェイルオーバしても、読取・書込用の IP アドレスは変わりませんので、アプリケーションからは一定時間のダウンタイムのあと、設定変更なしで再度コネクションを張ることができます。
またフェイルオーバをテストするため、手動でフェイルオーバを発生させることも可能です。
読み取りワークロードの可用性
読み取りプールインスタンスには複数のノードを含むことができます。
読み取り専用 IP アドレスが一つ払い出され、この単一の IP アドレスにアクセスすれば、いずれかのノードに割り振られます。読み取りプールインスタンスに複数のノードを作成することで、読取専用ワークロードの可用性を高めることが可能です。
可用性 SLA
AlloyDB for PostgreSQL の可用性 SLA は 99.99% です。
所定の計算方法に従った月間稼働率がこれを下回った場合、Financial Credits が還元されます(要申請)。
なお SLA が適用されるには、クラスタが「Multi-zone instance」である必要があります。これは「プライマリインスタンスの高可用性設定が有効化されている」または「最低2ノードの読み取りプールインスタンスを持っている」状態を指します。
災害対策 (DR)
前述のクロスリージョン・レプリケーションを用いることで、リージョンをまたいだ災害対策(Disaster Recovery)を実現できます。
クロスリージョン・レプリケーションを有効化すると、別リージョンのセカンダリクラスタ(読み取り専用)にデータが非同期でレプリケーションされます。プライマリクラスタのリージョンがダウンした際には、セカンダリクラスタを読み書き用のプライマリクラスタに昇格させることができます。
スケーラビリティ
AlloyDB のスケーラビリティの概念を整理すると、大まかに以下のようになります。
| 対象 | 垂直スケール | 水平スケール |
|---|---|---|
| プライマリインスタンス | 可 (マシンタイプ変更) | 不可 |
| 読み取りプールインスタンス | 可 (マシンタイプ変更) | 可 (ノード数変更) |
プライマリインスタンスは読み書きを司る単一のインスタンスのため、水平にスケールすることはできませんが、スペック変更による垂直スケールは可能です。
読み取りプールインスタンスは読み取り専用のノード集団ですので、ノード数を増やして水平にスケールすることも、スペックを上げて垂直にスケールすることも可能です。また、CPU 使用率やスケジュールに基づいたオートスケーリングも可能です。
- 参考 : Scale an instance
分析(OLAP)
AlloyDB カラムナエンジンとは
AlloyDB は業務用データベースとして OLTP(Online Transaction Processing)処理に向いたデータベースです。しかし AlloyDB カラムナエンジンを搭載しており、分析的処理(OLAP、Online Analytical Processing)も高速に行うことができます。
なおこのように OLTP と OLAP の両方のワークロードを処理できる特性を持つデータベースを、HTAP(Hybrid Transaction Analytical Processing)データベースと呼ぶこともあります。
カラムナとは「列指向」を意味しており BigQuery を始めとする多くの分析用データベースが列指向データベースです。AlloyDB ではカラムナエンジンにより、テーブルの特定データを列志向でメモリ上に保持することで、集計等の分析的なクエリを高速に処理できます。
カラムナエンジンはデータベースフラグ(AlloyDB の設定パラメータ)である google_columnar_engine.enabled を on にすることで有効化されます(インスタンス再起動が発生)。デフォルトだとインスタンスのメモリの30%が割り当てられますが、この値もデータベースフラグで設定可能です。
カラムナエンジンによりメモリ上に保持される領域はカラムストア(column store)と呼ばれます。カラムストアには特定の型のデータしか入りませんが、一般的な型はサポートされています。詳細は以下のドキュメントをご参照ください。
- 参考 : AlloyDB カラム型エンジンについて
自動カラムナ化
カラムナエンジンでは、自動カラムナ化(auto-columnarization)が利用可能です。
自動カラムナ化は、アプリケーションのワークロードを自動で分析して、割り当て容量も考慮しつつカラムストアに入れるべき列を決定します。
新規インスタンスでは自動カラムナ化はデフォルトで有効で、1 時間に一度、カラムストアの内容を更新・最適化します。
自動カラムナ化は無効化したり、頻度を変更したり、あるいは即時実行することが可能です。
手動でのカラムストア管理
前述の自動カラムナ化のほか、手動でカラムストアを管理することもできます。
google_columnar_engine.relations フラグに DATABASE_NAME.SCHEMA_NAME.TABLE_NAME(COLUMN_LIST) の形式で定義することで、明示的にカラムストアに入れるべき列名を指定できます。
- 参考 : カラムストア コンテンツを手動で管理する
BigQuery からの連携クエリ
Google Cloud の高性能でスケーラブルなデータウェアハウスである BigQuery から、AlloyDB へ連携クエリ(federated queries)を投入することが可能です。
連携クエリにより、BigQuery のユーザーインターフェイスから SQL を投入し、AlloyDB 上のテーブルデータを SELECT できます。この機能により、BigQuery に保持しているテーブルと AlloyDB 上のテーブルを結合(JOIN)することや、AlloyDB のデータを BigQuery に移動(Extract)すること等が可能になり、分析の利便性が向上します。
なお連携クエリでは、SQL が自動的に最適化され、AlloyDB 上の計算リソースも利用してフィルタしたうえで BigQuery にデータが転送される点に留意してください。この仕組みを SQL プッシュダウン(SQL pushdown)と呼びます。
- 参考 : AlloyDB 連携クエリ
- 参考 : 連携クエリの概要
バックアップ・リストア
バックアップの種類
AlloyDB のバックアップは、バックアップという名称のクラウドリソースとして取得することができます。バックアップには以下の3種類があります。
なおバックアップの取得はストレージレイヤで完結するため、実行してもパフォーマンス影響は無いとされています。
| 名称 | 説明 |
|---|---|
| 継続バックアップ (Continuous backups) | デフォルトは有効化。ポイントインタイムリカバリを可能にするバックアップ |
| オンデマンドバックアップ (On-demand backups) | 手動で採取されたバックアップ。Google Cloud コンソールや gcloud コマンド等で実行 |
| 自動バックアップ (Automated backups) | 自動スケジュールで取られたバックアップ。デフォルトで有効 (日次・14日保持) |
- 参考 : データのバックアップと復元の概要
継続バックアップとそのリストア
継続バックアップ(Continuous backup)はポイントインタイムリカバリ(point-in-time recovery、クラスタを任意の時点に巻き戻すリカバリのこと)を可能にするバックアップです。デフォルトで有効化されています。
継続バックアップが有効化されていると、1日に1回、データの変更に対する変更ログが増分でバックアップされるようになります。このバックアップを使い、既存クラスタを任意の時点まで巻き戻す(ポイントインタイムリカバリ)ことが可能です。マイクロセカンドの粒度で、最大で過去35日まで巻き戻すことができます。
継続バックアップは1〜35日間分のバックアップ取得するよう設定できます。デフォルトでは14日間の設定になっています。
オンデマンドバックアップ・自動バックアップとそのリストア
オンデマンドバックアップと自動バックアップは、クラスタのある時点のスナップショットを取得するバックアップです。これら2つの違いは取得契機が手動か自動か、の違いです。
最長1年の保存期間を設定可能で、期限が過ぎたバックアップは自動的に削除されます。
オンデマンドバックアップは毎回フルバックアップになるのに対して、自動バックアップは増分バックアップ(incremental backup)です。これは、データ保存料金に影響するため、料金試算に留意が必要です。
デフォルトでは、バックアップはクラスタと同じロケーション(リージョン)に保存されますが、オンデマンドバックアップは、別のロケーションを保存先として選択できます。これにより、災害対策やリージョンレベルの大規模障害に対処することができます。
オンデマンドバックアップまたは自動バックアップからのリストアは、新しいクラスタとして行われます。つまり、既存クラスタの中身がバックアップの時点に巻き戻るのではなく、バックアップを取った時点のデータを使って新規クラスタを作成することになります。なおこれは Compute Engine や Cloud SQL のバックアップ(スナップショット)と同様です。
接続
クライアント
AlloyDB for PostgreSQL へは psql コマンドなど、通常の PostgreSQL のクライアントソフトウェアから接続することができます。
ネットワーク
クライアントから、プライマリインスタンスもしくは読み取りプールインスタンスが提供する IP アドレスに接続します。
IP アドレスは、インターネットに公開されないプライベート IP アドレスが払い出されるほか、オプションでパブリック IP アドレスも有効化できます。パブリック IP アドレスを有効化する場合、承認された外部ネットワーク(Authorized external networks)を CIDR 形式で指定することで、接続を許可する接続元 IP アドレス範囲を限定できます。
基本的にはプライベート IP アドレスのみを使って利用することが望ましいですが、Clodu Run などのサーバーレスプラットフォームから、後述の AlloyDB Auth proxy を使ってアクセスさせる場合などにパブリック IP が利用できます。
VPC ファイアウォールで TCP ポート 5432 への Egress (外向き) 通信が許可されている限り、AlloyDB クラスタを作成したサービスプロデューサーネットワークと接続されている VPC 内の VM からは、AlloyDB クラスタに接続することができます。
- 参考 : 接続の概要
認証・認可
後述の AlloyDB Auth proxy を使わない限り、データベースユーザの考え方は PostgreSQL と同様です。
クラスタ作成直後は postgres ユーザでログインすることができます。ログイン用パスワードはクラスタ作成時に指定します。開発やアプリケーションからの接続のためには、管理特権を持たないユーザを新規作成することが推奨されます。
AlloyDB Auth proxy
AlloyDB Auth proxy とは
AlloyDB Auth proxy は AlloyDB を利用するアプリケーション側のローカルにインストールする、プロキシソフトウェアです。AlloyDB Auth proxy の利用は必須ではありませんが、推奨されています。
AlloyDB Auth proxy 経由で AlloyDB に接続することで、AlloyDB に IAM 権限で認証・認可 (ログイン) することができます。またアプリケーションからデータベースへの通信が TLS(TLS 1.3, 256-bit AES cipher)で暗号化されます。
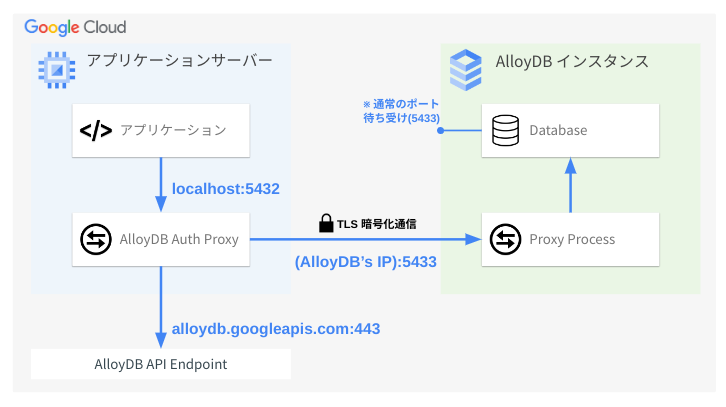
アプリケーションからは、ローカルで動作する AlloyDB Auth proxy クライアントソフトウェアに向けて TCP 5432 ポートで接続します(127.0.0.1:5432 もしくは localhost:5432。複数の読み取りプールインスタンスなど、複数のインスタンスをターゲットするときポート番号が1ずつ増える)。すると AlloyDB Auth proxy クライアントは、AlloyDB に向けてコネクションを張ります。
アプリケーションが Compute Engine や Cloud Run など Google Cloud 環境で動作している場合、インスタンス等にアタッチされているサービスアカウントの権限(roles/alloydb.client ロール)でデータベースにログインすることが可能です。
パブリック IP を使った接続
前掲の構成図では、AlloyDB Auth proxy から AlloyDB のプライベート IP アドレスへ接続していますが、パブリック IP アドレスを使って接続させることもできます。
Cloud Run などのサーバーレスプラットフォームから AlloyDB へ接続する際は、AlloyDB Auth proxy を利用してパブリック IP 経由でアクセスすることで、ネットワークのオーバーヘッドを抑えながらセキュアにアクセスさせることができます。
- 参考 : パブリック IP を使用して接続する
詳細は以下の記事も参照してください。
通信要件
アプリケーションの動作環境からは以下の外向き(Egress)ネットワーク通信要件が存在します。
- 0.0.0.0/0 への 443/TCP(
alloydb.googleapis.comへの接続のため) - AlloyDB インスタンスの IP アドレスへの 5433/TCP
Cloud Run における Auth proxy 利用
Cloud Run のサイドカーコンテナ機能を利用して AlloyDB Auth Proxy を使用する方法については、以下の記事もご参照ください。
マネージドコネクションプール
マネージドコネクションプール(managed connection pooling)は、AlloyDB 側で管理されたコネクションプールを利用できる機能です。
有効化すると、データベースクライアントとのコネクションがプールの中から動的に割り当てられ、リソース使用量とレイテンシが最適化されます。これにより、突然のコネクション量のスパイクがあっても、既存のコネクションを再利用するなどにより対処できます。また、短時間のコネクションが頻発するようなケースでも有用です。
接続モードとして、トランザクションレベルまたはセッションレベルでのコネクション割り当てが選択できます。また最大、最小のプールサイズなど、複数の設定項目があります。
- 参考 : マネージド接続プーリングを構成する
データのインポート・エクスポート
インポート
以下のフォーマットのファイルを、AlloyDB にインポートすることができます。
- CSV(1テーブル = 1ファイル。
psqlコマンドライン使用) - DMP(PostgreSQL のバイナリアーカイブファイル。
pg_restore使用) - SQL(
psqlコマンドライン使用)
インポートするには、ファイルを Cloud Storage に配置して、コマンドラインを実行します。
- 参考 : 移行の概要 - データのインポート
エクスポート
AlloyDB のデータは、以下のフォーマットでエクスポートできます。
- CSV(1テーブル/1ファイル。
psql使用) - DMP(PostgreSQL のバイナリアーカイブファイル。
pg_dump使用) - SQL(
pg_dump使用)
コマンドライン等を用いて AlloyDB からローカルマシンへデータをエクスポートする方法が公式ドキュメントで紹介されています。
- 参考 : 移行の概要 - データのエクスポート
移行ツール
Database Migration Service を利用することで、他のデータベースエンジンのデータベースから、AlloyDB にデータを移行することができます。Database Migration Service は、データベースのデータを移行するための Google Cloud サービスです。
詳細は以下のリンクから公式ドキュメントをご参照ください。
| ソース(移行元) | ドキュメントリンク | 備考 |
|---|---|---|
| PostgreSQL | Database Migration Service for PostgreSQL to AlloyDB | Amazon Aurora にも対応 |
| Oracle Database | Database Migration Service for Oracle to AlloyDB | - |
AI 機能
自然言語によるクエリ
AlloyDB AI natural language を使うと、生成 AI により、自然言語を使って AlloyDB のデータベースに対してクエリが実行できます。アプリケーションのエンドユーザーによる自然言語の質問に対して、AI が SQL を自動生成し、結果を返答するような仕組みを構築可能です。
有効化するには、alloydb_ai_nl 拡張機能をインストールする必要があります。
- 参考 : AlloyDB AI 自然言語の概要
モデルエンドポイント管理
モデルエンドポイント管理は、SQL 経由で外部の AI モデルを呼び出しできる機能です。
Vertex AI のエンベディングモデルを呼び出したり、マルチモーダルな生成 AI モデルを呼び出すことができます。
AI 支援によるトラブルシューティング
AlloyDB のトラブルシューティングの際、AI の支援を受けることができます。
利用には、Gemini Cloud Assist の有効化が必要です。
セキュリティ・監査
暗号化
AlloyDB のストレージのデータは、他の Google Cloud サービスと同様に、デフォルトで透過的に暗号化されています。つまり何もしなくても、AlloyDB のストレージのデータは暗号化で保護されており、ストレージ機器の盗難等には対処されています。このデフォルト暗号化の暗号鍵は、Google Cloud によって管理されています。
オプションで、Cloud KMS で管理する、顧客管理の鍵(Customer-managed Encryption Key = CMEK)を用いてストレージを暗号化することもできます。CMEK で暗号化することにより、鍵の管理(作成、廃止、ローテーション等)をコントロールすることができ、厳しい監査要件に耐えることができます。
- 参考 : CMEK について
Cloud KMS についての詳細は、以下の記事も参照してください。
監査ログ
クラスタ管理オペレーションの監査ログ
AlloyDB は、Cloud Audit Logs と統合されており、クラスタの管理系オペレーションの監査ログが出力されます。
クラスタの作成・削除、設定値の編集、バックアップの作成・削除などの更新系オペレーションは「管理アクティビティ監査ログ」と呼ばれ、デフォルトで記録される設定になっています。オフにはできません。
一方でクラスタ一覧の表示やクラスタ設定の取得などの参照系オペレーションは「データアクセス監査ログ」と呼ばれ、明示的に有効化する必要があります。
Cloud Audit Logs で採取されたログは、Cloud Logging のログエクスプローラ等で閲覧することができます。
なおこれらはあくまでクラスタの管理系オペレーションに関する監査ログであり、データベースの中身の操作に対する監査ログは次に紹介する pgAudit で取得することになります。
Cloud Audit Logs の詳細は、以下の記事も参照してください。
DB オペレーションの監査ログ
PostgreSQL データベースの中身の操作に対する監査ログはオープンソースの拡張機能(extension)である pgAudit により提供されます。
pgAudit で採取される情報は SELECT INSERT UPDATE DELETE などの各種 SQL (DDL/DML/DCL) です。記録する対象のオペレーションはデータベースフラグで定義できます。
有効化するにはデータベースフラグ alloydb.enable_pgaudit を on にセットしたうえでデータベースに接続して CREATE EXTENSION で拡張機能を有効化します。
pgAudit により生成されたログは、データアクセス監査ログとして Cloud Audit Logs 経由で Cloud Logging に送信されます。よって、ログを閲覧するためにはデータアクセス監査ログを有効化する必要があります。有効化後、Cloud Logging のログエクスプローラ等でログを閲覧することができます。
- 参考 : pgAudit について
運用とモニタリング
モニタリング
AlloyDB は Cloud Monitoring と統合されており、何も設定しなくても、CPU 使用率やメモリ使用率、ストレージの使用量などをグラフで閲覧することができます。
Cloud Monitoring のコンソール画面から各種メトリクス(採取されたパフォーマンス情報)を閲覧できるほか、AlloyDB のコンソール画面からもプレフィクスされたダッシュボードを確認できます。
Cloud Monitoring についての詳細は、以下の記事も参照してください。
インスタンスの停止・起動・再起動
AlloyDB クラスタのプライマリインスタンスや読み取りプールインスタンスは、停止・起動・再起動が可能です。
セカンダリインスタンスやリードプールインスタンスの個別ノードは、再起動のみが可能です。
停止したインスタンスに対しては、コンピューティング料金が発生しませんが、ストレージ料金は引き続き発生します。
インスタンスを停止すると、自動アップデートは行われなくなります。ただし、バックアップは行われます。
- 参考 : インスタンスを起動、停止、再起動する
チューニング
Query Insights
Query Insights は AlloyDB に組み込まれたクエリ分析ツールです。実行されているクエリのパフォーマンス情報を分析し、チューニングに活かすことができます。
Google Cloud の Web コンソールから閲覧できるほか、Cloud Monitoring API を経由してプログラマブルに情報を取得できるので、既存の APM(Application Monitoring)ツール等に情報を連携することも可能です。
Query Insights ではクエリの user、database、IP address、time range、CPU capacity、CPU and CPU wait、IO Wait、Lock Wait といった情報を閲覧できます。情報は1週間前のものまでが保存されます。
- 参考 : Query Insights について
なお、Query Insights 自体に料金は発生しません。Cloud Monitoring API 経由で情報を取得した場合は、API 呼び出し回数に応じた課金が発生します。
adaptive autovacuum
AlloyDB には adaptive autovacuum(適応的オートバキューム)という機能があります。
PostgreSQL には VACUUM(バキューム)の概念があります。PostgreSQL ではデータを update したり delete しても、そのデータには削除フラグが付くだけで、実際にはまだ存在しています。この不要領域を回収して使えるようにするのが VACUUM です。また VACUUM コマンドにオプションに応じて統計情報の更新やトランザクション ID のラップアラウンド防止のための処理などがされています。
AlloyDB ではデフォルトで adaptive autovacuum が有効化されており、パフォーマンス影響を最小限に抑えながら VACUUM 処理が自動化されています。
enable_google_adaptive_autovacuum フラグにより、有効化/無効化を設定することができます。
- 参考 : 適応型自動バキュームを構成する
インデックスアドバイザ
インデックスアドバイザ(index advisor)は、AlloyDB で処理されるクエリを分析し、パフォーマンス改善のためのインデックスを推奨してくれる機能です。2023/05/08 に GA となりました。
google_db_advisor.enabled フラグを on にすることで有効化できます(再起動が発生)。有効化してから1日程度経過して以降、定期的に分析が実行されます。
アドバイザによる推奨事項は SELECT * FROM google_db_advisor_recommended_indexes; のように SQL で照会することができます。
詳細は以下のドキュメントをご参照ください。
- 参考 : インデックス アドバイザーを使用する
Cloud SQL からの移行
Cloud SQL のバックアップを AlloyDB クラスタとして起動することで、Cloud SQL から AlloyDB への移行を容易に実現できます。
Cloud SQL から採取したバックアップを、AlloyDB の標準クラスタまたは無料トライアルクラスタとして起動できます。
ただし、起動先は同一プロジェクト、同一リージョンである必要があります。また、CMEK 暗号化された Cloud SQL インスタンスや、IAM グループ認証が設定された Cloud SQL インスタンスのバックアップはサポートされていません。
AlloyDB Omni
AlloyDB Omni は Linux サーバ上で動作する、AlloyDB for PostgreSQL のダウンロード版です。
カラムナエンジンや adaptive autovacuum、インデックスアドバイザなど、クラウド版 AlloyDB の持っている機能の一部を搭載しています。
Linux で動作するコンテナベースであり、ハイブリッドクラウド(オンプレミスとクラウドをミックスして利用するアーキテクチャ)や検証用途などのユースケースが想定されます。
詳細は以下のドキュメントをご参照ください。
- 参考 : AlloyDB Omni のドキュメント
- 参考 : AlloyDB Omni, the downloadable edition of AlloyDB, is now generally available
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it