



当記事は みずほリサーチ&テクノロジーズ × G-gen エンジニアコラボレーション企画 で執筆されたものです。
みずほリサーチ&テクノロジーズ株式会社の藤根です。 本日はKaggle初心者を対象に、データ分析サービスであるVertexAIのワークベンチ上にKaggle環境をサクッと構築する手順を解説します。

はじめに
本ブログではVertexAIのワークベンチ上にKaggle環境を構築する手順を解説します。
この記事を読むことで、
- Kaggleのカーネルと同じ環境をVertex AIで構築する
- Kaggle APIを使って、学習データのダウンロードや予測結果を提出する
- LightGBMを使ってタイタニックコンペに挑戦してみる
ことが出来るようになることを目指します。Kagglerを目指す方々が最初に躓きやすい「環境構築」を楽にするきっかけになれば幸いです。
※本記事では環境構築をテーマとするため、AIの理論や各パッケージの解説は割愛いたします。
Kaggle環境構築の必要性
Kaggle Notebooks環境の制約
一般的に、AI・データ分析を行うためには大量のCPU/GPUやメモリなどのコンピューティングリソースを必要とします。幸い、KaggleではPython/Rのプログラムを無料で実行できるKaggle Notebooksサービスを提供しており、インターネットに接続可能なPCさえあれば、GPU/TPUアクセラレーターの無料使用や、コンペデータのダウンロードや予測結果の提出までを誰でもワンストップで実行できる環境が整っています。
「じゃあNotebooksで十分では?」と思いたくなりますが、Notebooksの技術仕様には以下制約が記載されており、長時間の学習やマシンリソースの拡張には適していません。
- Notebookの連続稼働時間は、CPU/GPUマシンで最大12時間、TPUマシンで最大9時間まで
- GPU/TPUアクセラレーターの利用可能時間は、それぞれ30時間/1週間まで
- 1時間以上アクティブな画面操作がないと、セッションタイムアウトが発生(学習途中のモデルの重みや変数は、外部ストレージに都度保存しない限り削除される)
- CPU/GPU/TPU毎のマシンスペックは固定であり、拡張できない
また、近年はCode Competitionsという、予測結果ファイルではなく予測プログラムを提出するコンペ形式が増えてきました。このため、Notebooks以外でコンペ用の学習環境を別途準備する場合、Pythonと使用パッケージのバーションを一致させる必要性があります。
Google Colaboratory環境の制約
Notebooks以外で無料で使えるAI学習環境としては、Google Colaboratoryも有名です。しかし、
- 無料版ではハイスペックなGPUリソースをほとんど利用できない
- 使用するパッケージのバージョンをKaggle Notebooksに合わせる作業が必要
- データセットや学習モデルが巨大な場合、Google Driveの無料ストレージ枠に収まらないことがある
等の理由から、安定した学習環境を得るにはPro/Pro+へのアップグレードが前提と思われます。
本記事では、そんな環境構築のいくつかの選択肢の一つとして、VertexAIによる構築を試したものになります。
事前準備
Google Cloudのアカウントをご用意下さい。本記事では小規模のインスタンスタイプを使用するため、少額の費用が発生します。
続いて、Kaggleにサインインしてアカウントを取得後、Kaggle API Documentationを参考にAPIトークン(kaggle.jsonファイル)をダウンロードします。1度発行されたファイルやトークン値は再発行されないため、無くさないようにご注意下さい。
VertexAI ワークベンチの起動
VertexAI ワークベンチの新規作成
VertexAI ワークベンチ新規作成画面の表示
ワークベンチのインスタンスを新規作成します。gcloudにもVertexAI用のCLIコマンドがあるのですが、以降で使用するKaggle用コンテナが起動できなかったため、マネージドコンソール画面での操作手順を解説します。
サイドバーから「VertexAI」⇒「ワークベンチ」を選択します。API承認画面が出たら有効化します。
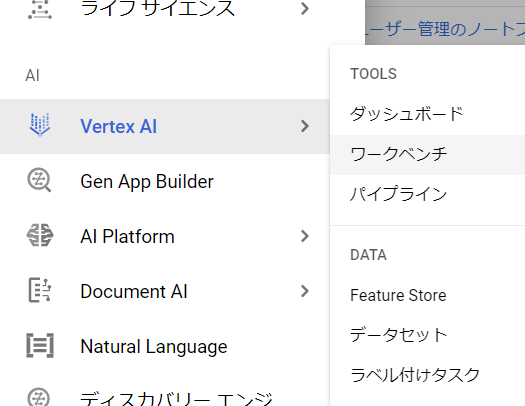
機械学習プラットフォームの選択
「ユーザー管理のノートブック」から「新しいノートブック」をクリックし、「Kaggle Python[BETA]」を選択します。
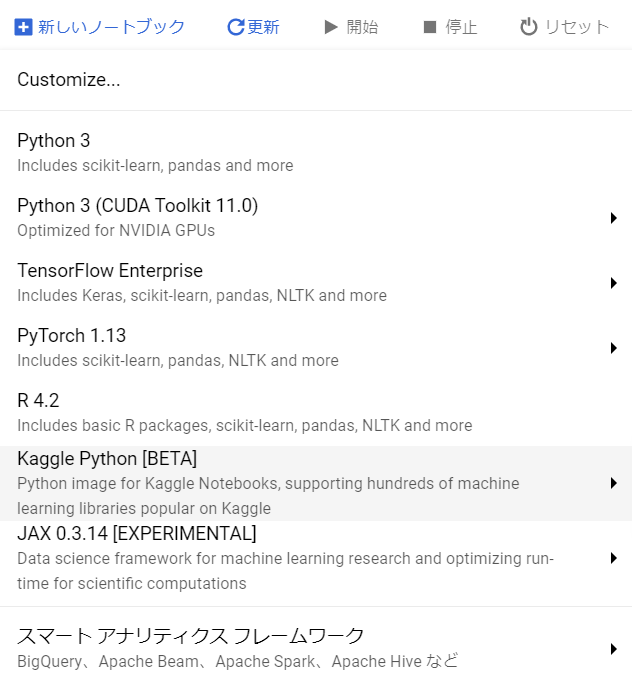
詳細設定画面の表示
ポップアップ左下の「詳細オプション」を選択します。
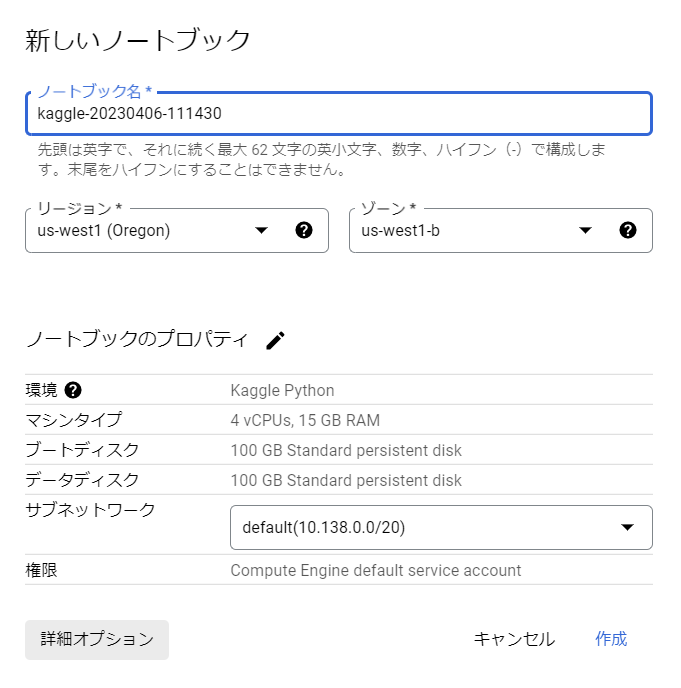
インスタンス名とリージョン/ゾーンの設定
インスタンス名とリージョン/ゾーンを入力します。もしGPU使用する場合は、GPUリソースを使用可能なリージョンとゾーンをGPUのリージョンとゾーンの可用性から確認して下さい。今回はCPUで実行します。

環境(機械学習プラットフォーム)の確認
環境が「Kaggle Python[BETA]」となっていることを確認します。

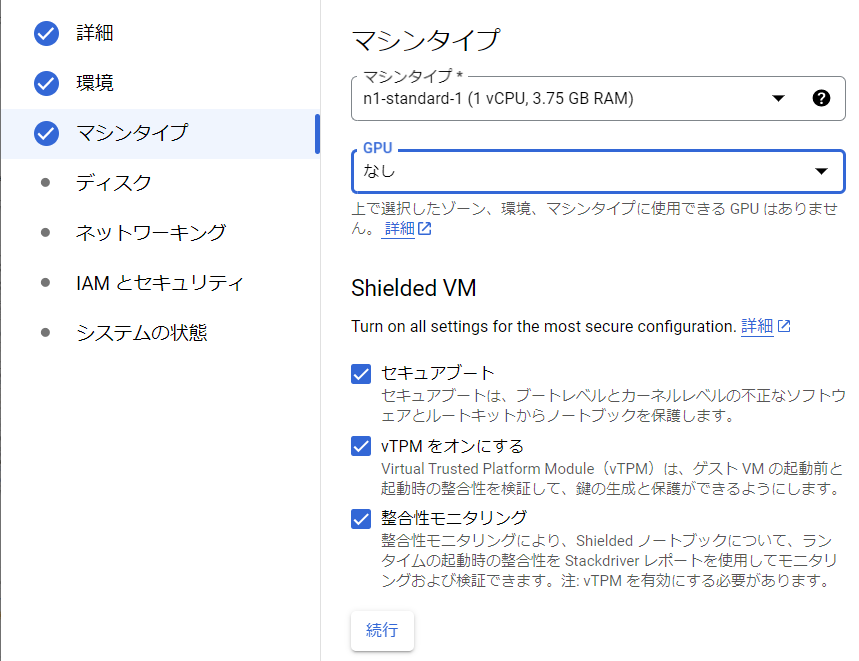
マシンタイプの選択
マシンタイプを選択します。今回はデータサイズが小規模なため「n1-standard-1」とします。マシンタイプはインスタンス生成後でも変更可能です。セキュアブートにもチェックを入れます。
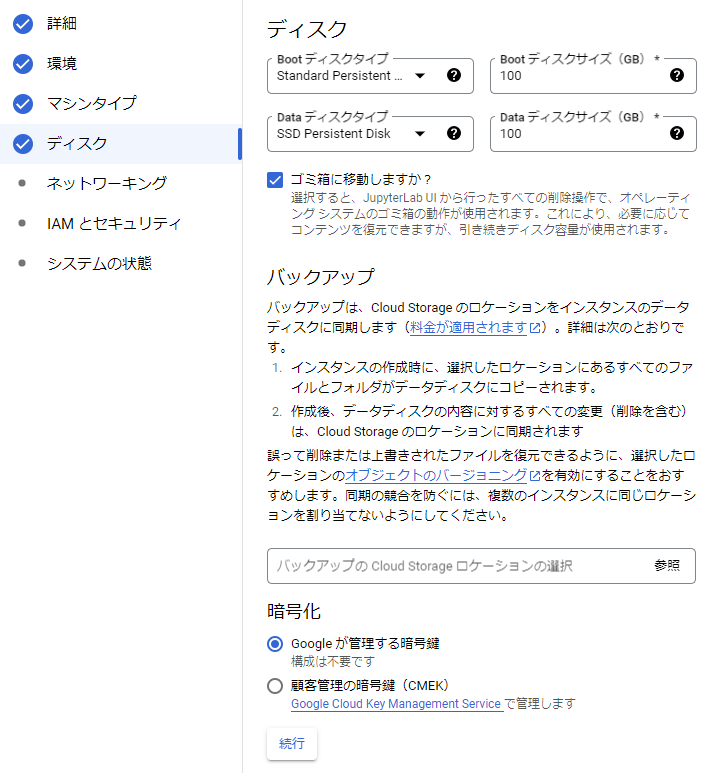
ディスクとバックアップの設定
ディスクのサイズやバックアップ有無などを設定します。 デフォルトのディスクタイプ(Standard)は安価ですが低速なHDDのため、DataディスクタイプだけでもSSD(もしくはより上位)に変更した方がディスクI/Oが改善されます。ストレージタイプ毎の性能はストレージオプションをご参照下さい。 コンペデータが100GB以上の場合は、ディスクサイズも増やしましょう。
また、「ゴミ箱に移動しますか?」にチェックを入れます。これにより、インスタンス削除と連動してディスクも削除されるため、不要ディスク残存によるコスト発生を防ぎます。
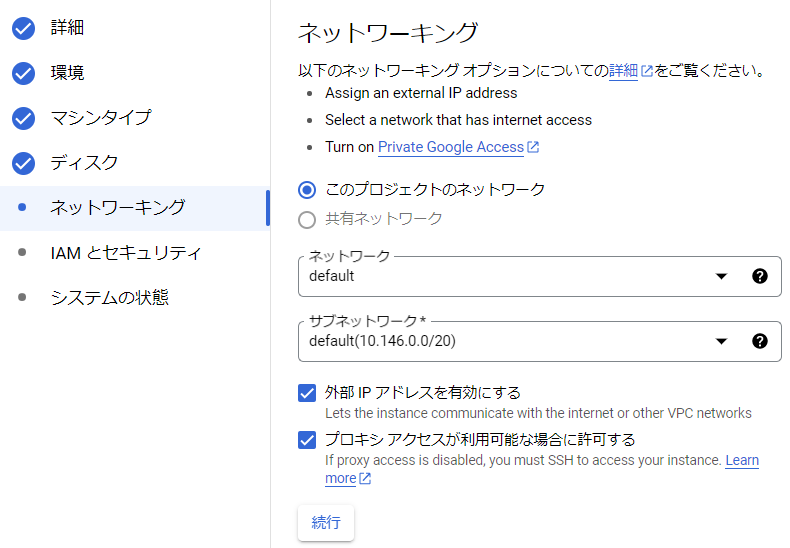
ネットワークの設定
ネットワークを設定します。
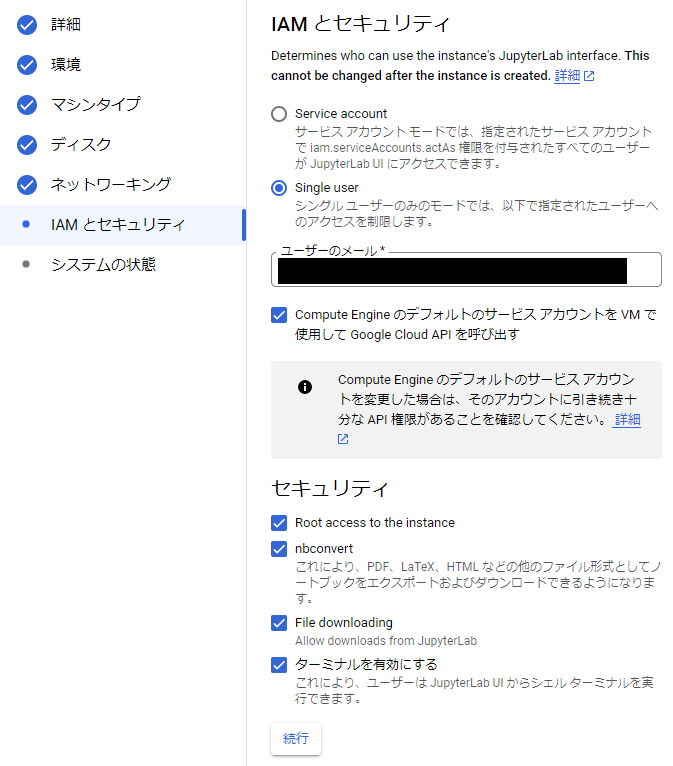
IAMとセキュリティの設定
IAMとセキュリティを設定します。セキュリティの「Root access to the instance」にもチェックを入れます。
システムの状態とReportingの設定
システムの状態を設定します。想定外の環境差異発生を防ぐため、「環境の自動アップグレード」はチェックを外したままにします。Reportingの設定は任意です。
最後に作成ボタンをクリックします。

VertexAI ワークベンチの確認
インスタンスの起動確認
インスタンスが作成・起動されるまで、数分待ちます。グリーンのチェックマークが出たら完了です。

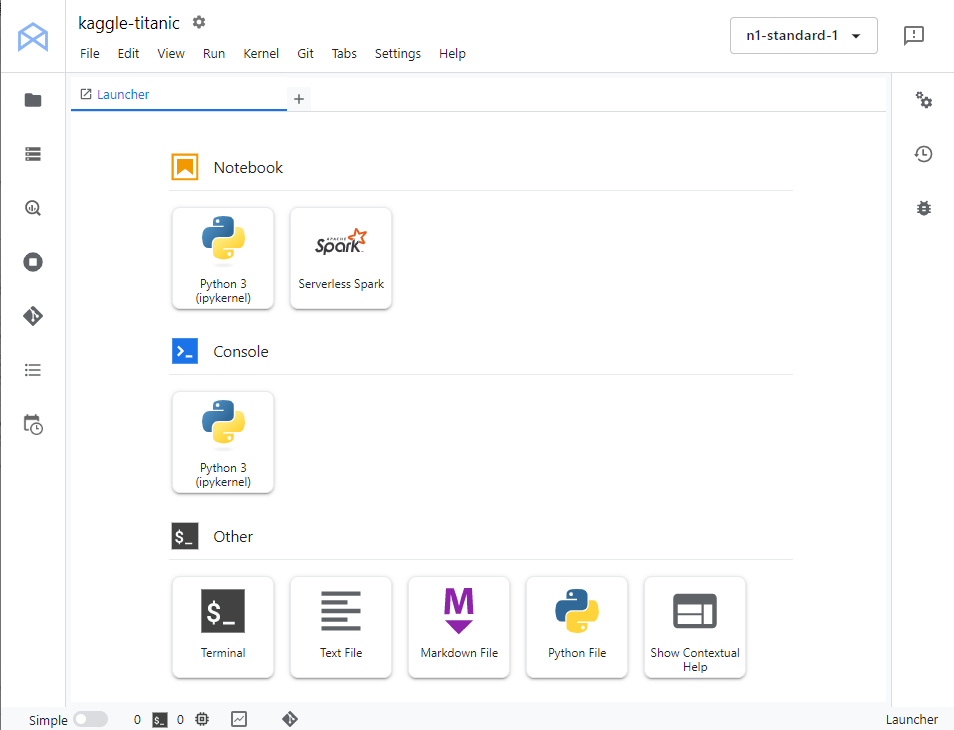
「JUPYTERLABを開く」リンクをクリックします。しばらくして、Jupyter Labの以下画面が表示されたら成功です。
Pythonと各パッケージのバージョン確認
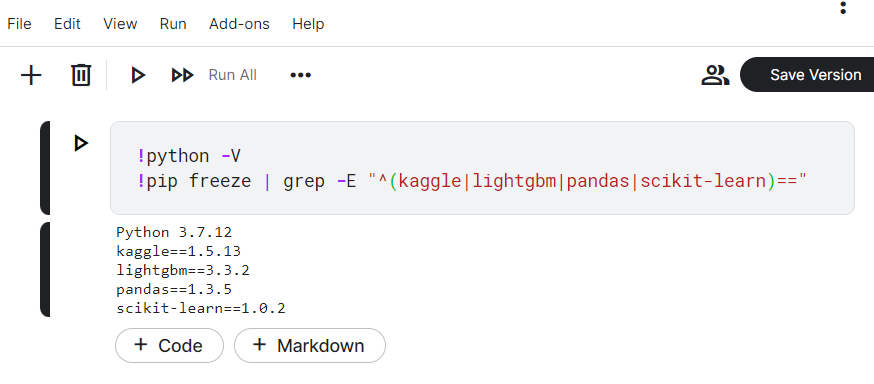
ターミナルを起動し、Pythonと各パッケージのバージョンを確認します。
$python -V Python 3.7.12 $ pip freeze | grep -E "^(kaggle|lightgbm|pandas|scikit-learn)==" kaggle==1.5.13 lightgbm==3.3.2 pandas==1.3.5 scikit-learn==1.0.2
同日にKaggle Notebooksで同じコマンドを実行した結果は以下となります。Pythonと各パッケージのバージョンが完全一致していることが確認できます。
Kaggle APIの認証設定
続いて、ワークベンチでKaggle APIを使用できるようにします。
事前準備で取得したkaggle.jsonファイルをワークベンチにアップロード後、以下コマンドでjsonファイルをコピーし、アクセス権限を変更します。
$ cp kaggle.json /root/.kaggle/ $ chmod 600 /root/.kaggle/kaggle.json
kaggleコマンドを稼働確認します。以下のようにバージョン情報が出力されれば成功です。
$ kaggle --version Kaggle API 1.5.13
もし、
OSError: Could not find kaggle.json. Make sure it's located in /root/.kaggle. Or use the environment method.
というメッセージが出た場合は、jsonファイルの名前か配置ディレクトリが間違っている可能性がありますので、ご確認下さい。
LightGBMによるタイタニックコンペの学習・予測
データの準備
いよいよ、タイタニックコンペの学習・予測を行います。このコンペでは、タイタニック号の乗客情報から、乗客が生存したかどうかを予測する2値分類タスクです。データサイズが小さく、Kaggle初心者向けのコンペです。
始めに、タイタニックコンペのデータセットをダウンロード&解凍します。lsコマンドで3つのCSVファイルが出力されれば成功です。
$ kaggle competitions download -c titanic $ unzip titanic.zip $ ls *.csv gender_submission.csv test.csv train.csv
パッケージのインポート
以降では、notebookを起動してPythonプログラムを実装していきます。まずは使用するパッケージをインポートします。
import numpy as np import pandas as pd import lightgbm as lgb from sklearn.model_selection import train_test_split
学習データの読み込み
カラム毎のデータ型を定義し、学習データを読み込みます。
features_dtype = {'PassengerId': int, 'Pclass': 'category', 'Sex': 'category',
'Age': np.float16, 'SibSp': np.uint8, 'Parch': np.uint8,
'Fare': np.float32, 'Cabin': 'category', 'Embarked': 'category'}
target_dtype = {'Survived': bool}
train_dtype = {**features_dtype, **target_dtype}
train = pd.read_csv('train.csv', index_col='PassengerId',
usecols=list(train_dtype), dtype=train_dtype)
label = train.pop('Survived')
train.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 891 non-null category
1 Sex 891 non-null category
2 Age 714 non-null float16
3 SibSp 891 non-null uint8
4 Parch 891 non-null uint8
5 Fare 891 non-null float32
6 Cabin 204 non-null category
7 Embarked 889 non-null category
dtypes: category(4), float16(1), float32(1), uint8(2)
memory usage: 23.9 KB
学習データの分割
学習データを、学習用と検証用データに8:2で分割します。
splits = train_test_split(train, label, random_state=0, test_size=0.2, stratify=label) X_train, X_valid, y_train, y_valid = splits len(X_train), len(X_valid)
(712, 179)
学習開始
LightGBMの学習パラメータを設定し、学習を開始します。
cls = lgb.LGBMClassifier(objective='binary', learning_rate=0.5, class_weight=label.value_counts().to_dict()) cls.fit(X_train, y_train, eval_set=[(X_valid, y_valid)], callbacks=[lgb.early_stopping(20)])
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[5] valid_0's binary_logloss: 0.469881
LGBMClassifier(class_weight={False: 549, True: 342}, learning_rate=0.5,
objective='binary')
スコアの確認
スコアを確認しましょう。上記パラメータでは、学習データで0.869、検証データで0.832となりました。
cls.score(X_train, y_train), cls.score(X_valid, y_valid)
(0.8693820224719101, 0.8324022346368715)
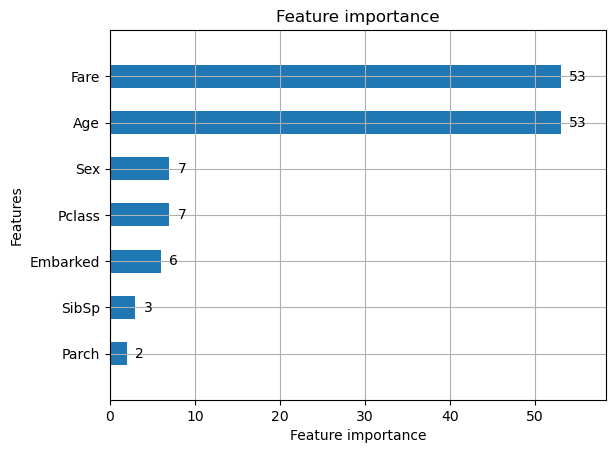
特徴量の寄与率の確認
どの特徴量が予測に重要なのか、寄与率をグラフ化します。Fare(乗船料金)とAge(年齢)が同率で重要なことが分かります。
lgb.plot_importance(cls, height=0.5)
Tree構造の可視化
LightGBMは決定木を用いた手法のため、データの値からどのように予測しているかを分岐グラフで可視化することができます。
graph = lgb.create_tree_digraph(cls, orientation='vertical', filename='graph', format='svg') graph.render() graph

テストデータ(未学習のデータ)によるモデルの検証
最後に、テストデータから予測結果を生成し、submission.csvファイルに出力します。
predict = pd.read_csv('gender_submission.csv', index_col='PassengerId') test = pd.read_csv('test.csv', index_col='PassengerId', usecols=list(features_dtype), dtype=features_dtype) predict['Survived'] = cls.predict(test).astype(np.uint8) predict.to_csv('submission.csv')
ターミナルを起動し、以下コマンドで予測結果を提出します。
$ kaggle competitions submit -f submission.csv -m "first submission" titanic 100%|███████████████████████████████████████████████| 2.77k/2.77k [00:01<00:00, 1.46kB/s] Successfully submitted to Titanic - Machine Learning from Disaster
1分ほど待ち、以下コマンドで予測結果のスコアを確認します。今回のスコアは0.784となりました。
$ kaggle competitions submissions titanic fileName date description status publicScore privateScore -------------- ------------------- ---------------- -------- ----------- ------------ submission.csv 2023-04-10 02:40:58 first submission complete 0.78468
予測精度の向上に関する考察
ここまではシンプルな実装に留めましたが、更に
- より高度な特徴量の生成
- 交差検証(cross validation)
- LightGBMのパラメータチューニング
- 深層学習の適用
などを行うことで、予測精度を向上できると思われます。
事後作業
最後に、ワークベンチの管理画面に戻り、インスタンスを削除して下さい。
さいごに
本日は、「VertexAIのワークベンチ上にKaggle環境をサクッと構築する手順」を解説させていただきました。
今回はワークベンチのみを使用しましたが、他にも
- Cloud Source Repositories : notebookや予測結果をバージョン管理
- Vertex AI Dataset : データセットを保管・可視化
- Vertex AI Feature Store : 生成した特徴量を保存・再利用
などのサービスを組み合わせることで、より充実したKaggle環境になると思われます。
藤根 成暢
みずほリサーチ&テクノロジーズ
先端技術研究部に所属。Pythonによるデータ分析やAI開発、Google Cloudの技術検証などを担当。保有資格はACE、PDE。