


G-gen の杉村です。Cloud Run services や Cloud Run functions などでは、文字列を標準出力に出力することで、Cloud Logging にログを出力できます。その際に文字列を JSON で構造化して出力することで、Cloud Logging でログがパースされ、ログが閲覧しやすくなります。この仕組みについて解説します。

Google Cloud サービスと Cloud Logging
Cloud Run services や Cloud Run functions などでは、文字列を標準出力や標準エラー出力に出力するだけで、Cloud Logging にログを出力できます。
つまり、これらのサービス上で稼働するプログラムから Cloud Logging にログを出力したいときは、Cloud Logging の API リクエストを行ったり、エージェントプログラムをインストールする必要はなく、標準出力や標準エラー出力にテキストを出力するだけでよいことになります。この方法に対応しているサービスには、以下が挙げられます。
- Cloud Run(services、jobs、worker pools)
- Cloud Run functions
- App Engine
- Google Kubernetes Engine(GKE)
これらのサービスで標準出力や標準エラー出力にテキストを出力すると、ランタイムにプリインストールされている統合 Logging エージェント(integrated logging agent)により、テキストは自動的に Cloud Logging に送信されます。
構造化ロギング
前述の仕様を使い、Cloud Logging にログを送出するとき、単に文字列を出力することでも Cloud Logging ログエントリとして記録されますが、JSON 形式でログを構造化することで、複数行に渡るログを見やすく表示したり、severity(重要度)を明示したり、その他の要素を構造的にログエントリに含ませてクエリしやすくしたりすることができます。
JSON で構造化したログ出力方法
log_dict = {
"message": "exp 8-2: Output with another keys",
"my_key_1": "my_value_1",
"my_key_2": "my_value_2",
}
message_json = json.dumps(log_dict)
logging.warning(message_json)
検証
前提条件
当記事で後述する検証結果はすべて、以下の条件で実行されたものです。
- Cloud Run(services)
- ベースイメージは python:3.12-slim
検証1. 単純なテキスト
以下のようなソースコードで、単純な文字列を print 関数で標準出力に出力します。
# 検証1 : シンプルな文字列の出力(非構造化) message="exp 1/2: hello, world" print(message)
出力結果を Cloud Logging のログエクスプローラーで閲覧すると、以下のようになります。
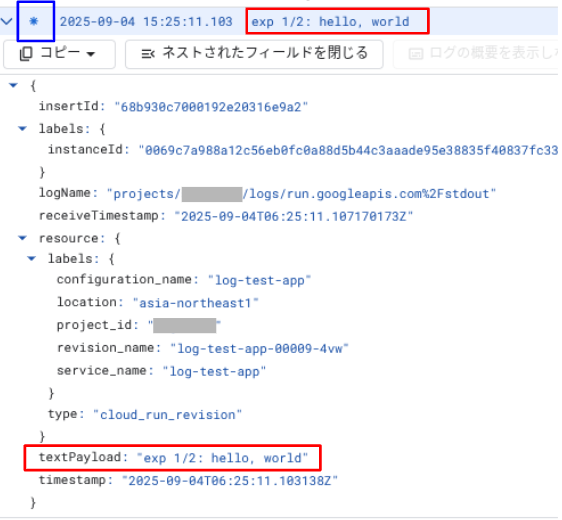
print 関数による出力内容は、ログエントリの textPayload として記録されています。またその内容は、ログエントリのプレビュー(画像上部の赤枠)として表示されています。
severity アイコン(画像の青枠)は DEFAULT(特に設定されていないことを意味する)が表示されています。ログエントリ内の要素としては、severity は存在していません。
検証2. JSON で構造化した出力
次に、以下のようなソースコードで、JSON で構造化した文字列を print 関数で標準出力に出力します。
# 検証2 : シンプルな文字列の出力(構造化) import json log_dict = { "message": message, "severity": "INFO", } message_json = json.dumps(log_dict) print(message_json)
ソースコードは先程の「検証1」に続けて書かれているので、message 変数の中身は、検証1と同様です。まずは message と severity というキーを持つ辞書型変数を作成し、それを json.dumps で JSON 型にしたものを print しています。
出力結果をログエクスプローラーで閲覧すると、以下のようになります。
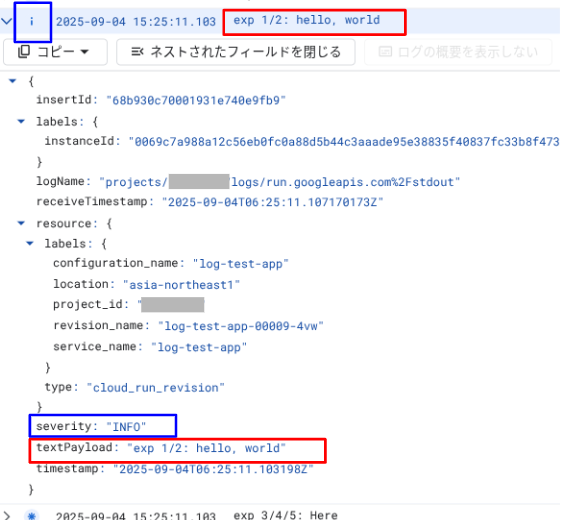
検証1との違いは、severity が反映されていることです。先程のログエントリには severity 要素が存在せず、アイコン表示は DEFAULT でしたが、今回はログエントリに severity が存在し、INFO が格納されています。またログエントリのプレビューの左端にあるマーク(画像上部の青枠)もそれに応じたアイコンになっています。
検証3. 複数行の出力
次に以下のようなソースコードで、複数行の文字列を、構造化せずに print 関数で標準出力に出力します。
# 検証3 : 改行がある文字列の出力(非構造化) message="""exp 3/4/5: Here are multiple lines""" print(message)
出力結果は、以下のようになります。
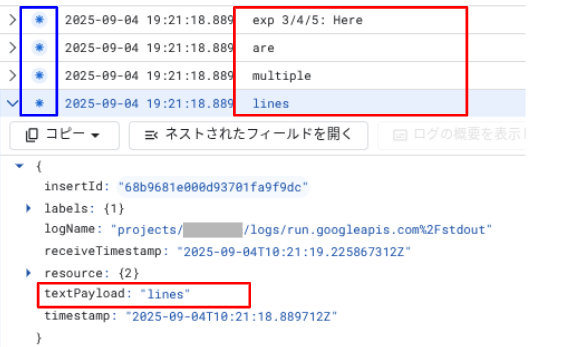
文字列の各行が、改行コード区切りで別々のログエントリとして解釈されてしまい、閲覧性が悪くなっています。
検証4. 複数行の出力を JSON で構造化
次に、以下のようなソースコードで、先程と同じ複数行の文字列を JSON で構造化して出力します。
# 検証4 : 改行がある文字列の出力(構造化) log_dict = { "message": message, "severity": "WARNING", } message_json = json.dumps(log_dict) print(message_json)
ソースコードは先程の「検証1」に続けて書かれているので、message 変数の中身は、検証3のままです。
出力結果は、以下のようになります。
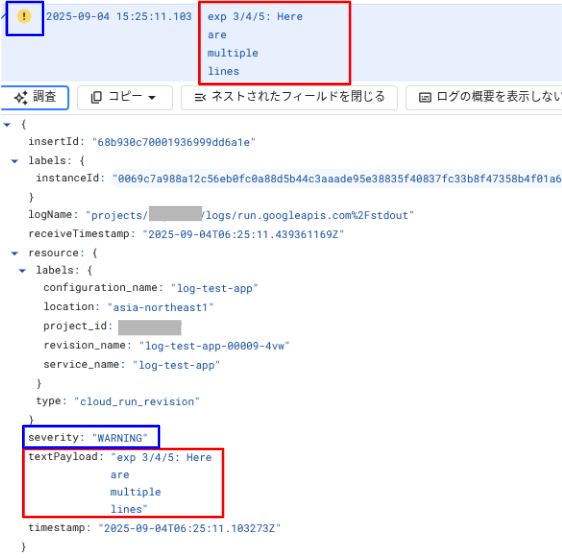
複数行の文字列は1個のログエントリとして適切に解釈され、textPayload に格納されています。
検証5. 辞書型変数を print 関数で出力
実験として、以下のようなソースコードで、検証4で構造化した辞書型変数を、JSON 化せずに print 関数に渡してみます。
# 検証5 : 改行がある文字列の出力(辞書型のまま) print(log_dict)
出力結果を Cloud Logging で閲覧すると、以下のようになります。
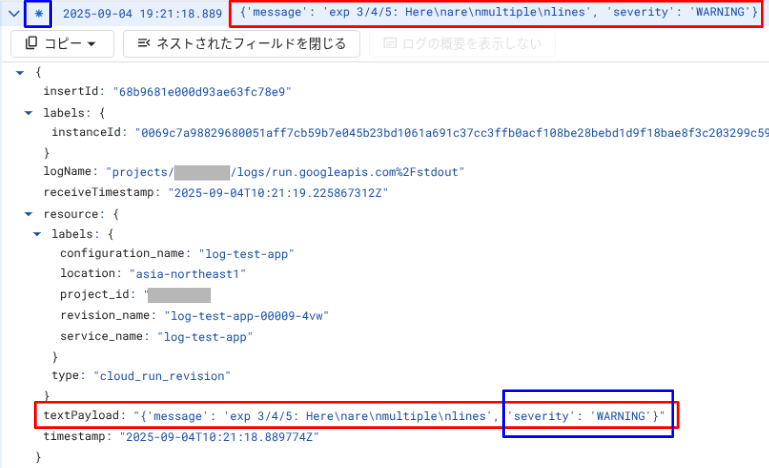
辞書型が文字列型にキャストされた結果は Cloud Logging には適切に解釈されず、severity もログエントリに反映されていません。このような出力の仕方は適切ではありません。
検証6. 様々な severity
以下のようなソースコードで、様々な severity のログエントリを出力して、ログエクスプローラーでの見え方を確認します。リスト severities の最後には、存在しない severity である MYSEVERITY を紛れ込ませてあります。
# 検証6 : 様々な Severity message = "exp 6: This is a message" severities = ["DEFAULT", "DEBUG", "INFO", "NOTICE", "WARNING", "ERROR", "CRITICAL", "ALERT", "EMERGENCY", "MYSEVERITY"] for severity in severities: log_dict = { "message": message + " with severity: " + severity, "severity": severity, } message_json = json.dumps(log_dict) print(message_json)
出力結果は、以下のようになります。
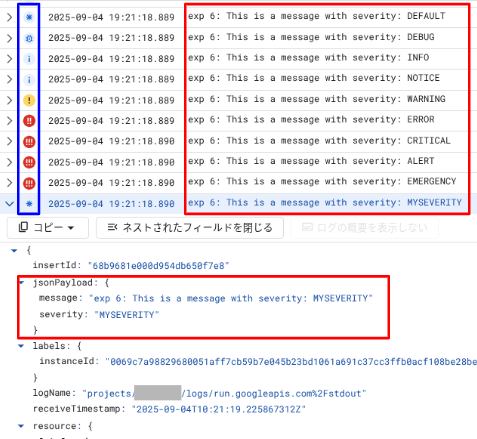
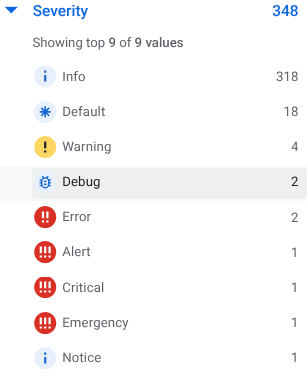
各ログエントリに設定された severity はグラフィカルにアイコンで表示されています。存在しない severity である MYSEVERITY は正しく解釈されず、当該ログエントリの severity 要素は存在せず、アイコンは DEFAULT になっていました。Cloud Logging で使用可能な severity は以下のとおりです。
検証7. 追加の JSON キー
以下のソースコードでは、JSON の中に message キーのほか、my_key_1、my_key_2 という独自のキーも含ませています。
# 検証7 : message と追加のキー log_dict = { "message": "exp 7: This is the main message text.", "severity": "WARNING", "my_key_1": "my_value_1", "my_key_2": "my_value_2", } message_json = json.dumps(log_dict) print(message_json)
出力結果は以下のようになりました。
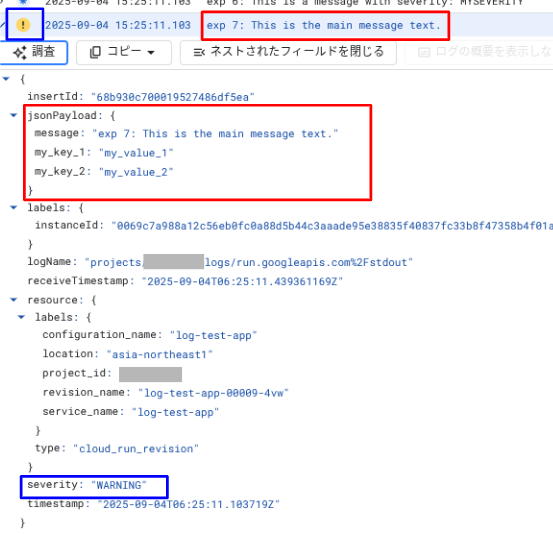
ここまでの検証では、message キーで渡された文字列は、ログエントリでは textPayload 要素として解釈されていました。しかし今回のようにカスタムキーが1個でも含まれると、message キーも含めたすべてのキーが、ログエントリの jsonPayload 要素の中に格納されます。そのようなときも、message は画像上部赤枠のプレビューで表示されています。また severity キーだけは jsonPayload から除外されて、ログエントリの最上位要素である severity として格納されます。
このように独自のキーを含ませることで、ログエントリを構造化でき、ログの閲覧のしやすさや検索性を向上できます。
検証8. Cloud Logging クライアントライブラリと Python ロガーの併用
以下では、Python の標準ライブラリである logger と、Cloud Logging のクライアントライブラリを使って、実用的な使い方を紹介します。
# 検証8 : Python のロガーを使用 import logging import os import google.cloud.logging client = google.cloud.logging.Client() client.setup_logging(log_level=logging.DEBUG) # Cloud Run 環境でなければ(ローカル環境であれば)ハンドラを追加、ログが画面出力される if not os.getenv('K_SERVICE'): handler = logging.StreamHandler() formatter = logging.Formatter('[%(asctime)s][%(name)s][%(levelname)s] %(message)s') handler.setFormatter(formatter) logging.getLogger().addHandler(handler) message = "exp 8-1: Output with logger." logging.info(message_json)
上記のソースコードでは、client.setup_logging() によって Cloud Logging ハンドラを Python ルートロガーに接続しています。これにより、以下のような挙動になります。
- ロガー(ここでは
logging)に JSON 形式でなく単純な文字列を渡すだけで、適切に Cloud Logging ログエントリに出力される(複数行の文字列のハンドリングなど) - ロガーで指定したログレベルが Cloud Logging のログエントリの severity に反映される
- ログを出力したファイル、関数、ソースコードの行数がログエントリに自動的に出力される
以下は、検証8-1として出力した結果です。
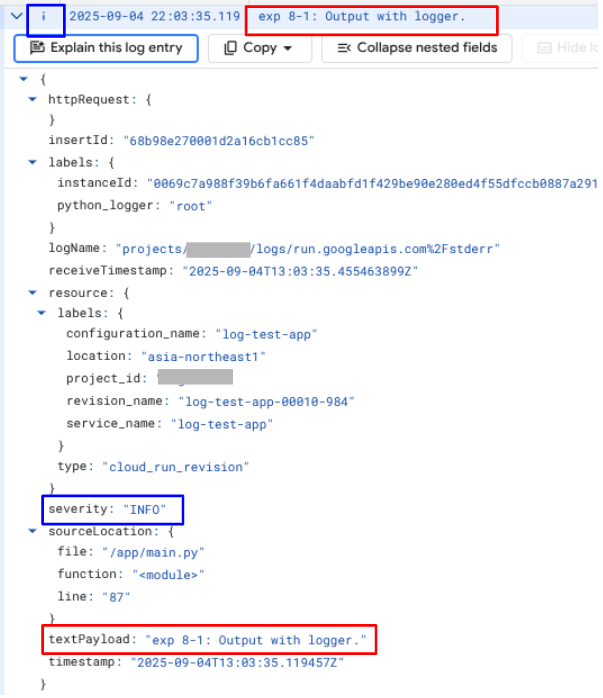
上記のように、検証8-1では、logging に渡した引数は単純な文字列型でありながら、severity が反映されています。また、sourceLocation がログエントリに自動的に追加されており、ログが出力されたファイル名、関数、行数などがわかるようになっています。
なお、if not os.getenv('K_SERVICE'): からの行では、環境変数 K_SERVICE を確認しています。この環境変数は、Cloud Run service ランタイム上では自動的にサービス名が代入されます。環境変数が存在しない場合はローカル環境での実行とみなし、画面に見やすい形でログを出力するようにしています。環境変数 K_SERVICE を確認せずに無条件に StreamHandler (標準出力にログを出力するハンドラ)を追加していまうと、Cloud Run 環境で実行された場合にも標準出力にログが出力されてしまうことから、先程の Cloud Logging 用のハンドラとあわせて、2行のログエントリが重複して Cloud Logging に記録されてしまいます。
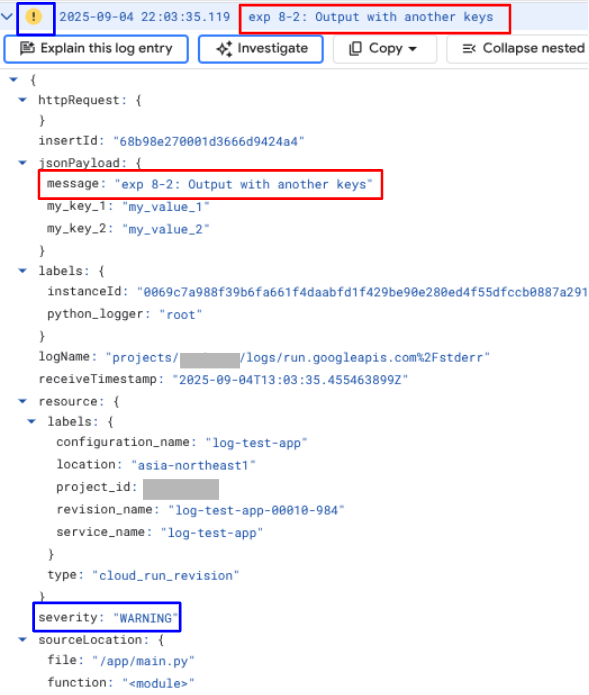
続いて以下は、検証8-2のソースコードと出力結果です。
log_dict = {
"message": "exp 8-2: Output with another keys",
"my_key_1": "my_value_1",
"my_key_2": "my_value_2",
}
message_json = json.dumps(log_dict)
logging.warning(message_json)
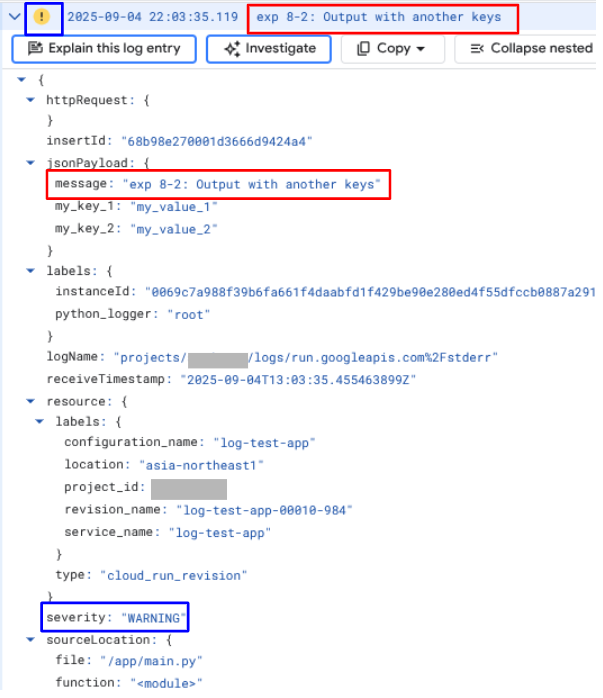
検証8-2では、logging に渡した引数は JSON です。jsonPayload にカスタムキーを含めた要素が入っています。
最後に、以下のような検証8-3も実行します。
message = "exp 8-3: This is a message with extra fields" extra_fields = { "my_key_1": "my_value_1", "my_key_2": "my_value_2", } logging.error(message, extra={"json_fields": extra_fields})
ロガー(ここでは logging)に第1引数として文字列を与え、extra として辞書型で json_fields をキーとしてカスタムフィールドを与えると、以下のような結果になります。
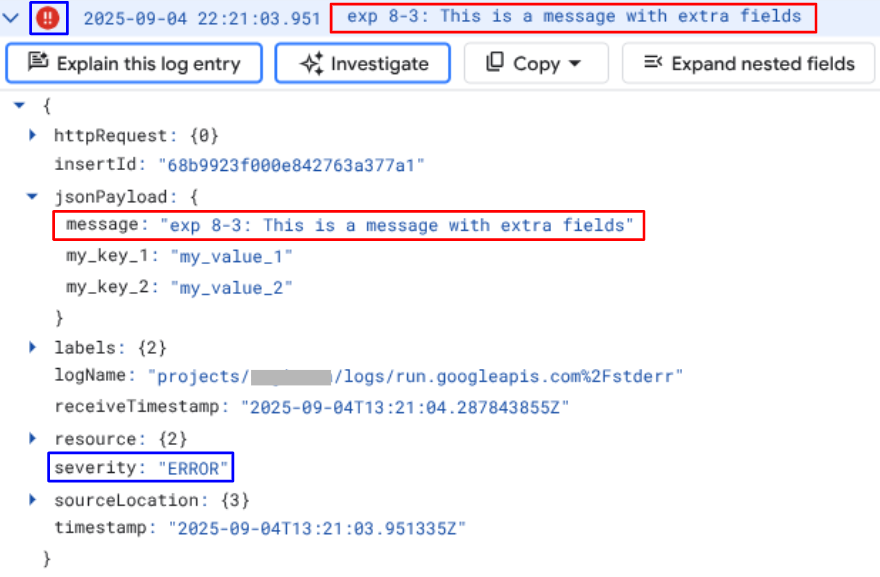
このようにして、ログの主たるメッセージを文字列で指定し、それ以外の付加的な情報を extra として辞書型で与えることができます。
検証9 : Python 標準ロガーのみの使用
以下のソースコードは、Python 標準の logging ライブラリのみを使用しています。カスタムフォーマッタを定義してハンドラにセットすることで、ロガーにテキストを渡すだけで出力が JSON 形式になり、Cloud Logging で適切に解釈されるようになります。
# 検証9 : カスタムフォーマッターを作成して JSON 化する import json import logging class FormatToJson(logging.Formatter): def format(self, log): return json.dumps({ "message": log.getMessage(), "severity": log.levelname, "app": log.name, }) formatter = FormatToJson(datefmt="%Y-%m-%dT%H:%M:%S%z") handler = logging.StreamHandler() handler.setFormatter(formatter) logger = logging.getLogger(__name__) logger.setLevel(logging.INFO) logger.addHandler(handler) logger.info("exp 9: This is a message with a custom formatter.")
この方法では、Cloud Logging ログエントリは以下のようになります。
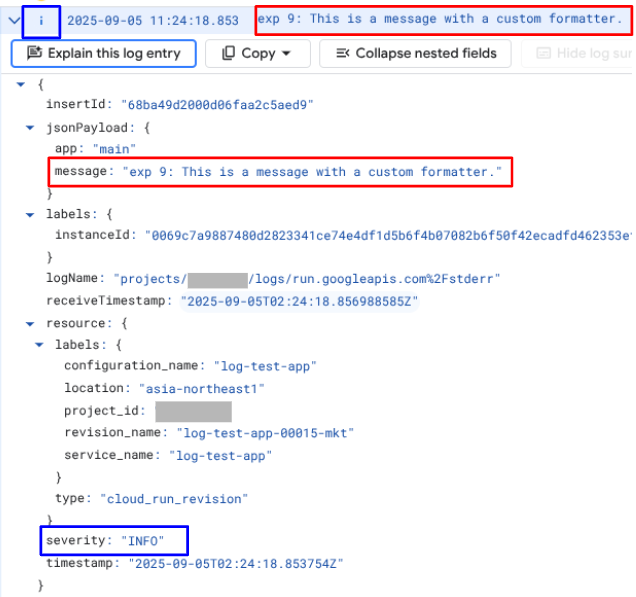
Cloud Logging クライアントライブラリを使用しないため軽量ではありますが、フォーマッタで定義されていないキーを追加できないほか、自動的にソースコードの行数がログに出力されることはありません。
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it