


G-gen の山崎です。2024年10月に利用可能になった、BigQuery の Pipe syntax(パイプ構文)の概要と使い方を紹介します。

概要
はじめに
当記事では、BigQuery の Pipe syntax(以下、パイプ構文)について、従来の SQL と比較しながら解説します。
パイプ構文は記事を執筆した2024年10月時点では利用申請が必要な Preview 版です。Preview 版のサービスや機能は、本番環境での利用は推奨されていません。Preview 版のサービスや機能を使うことに関しての注意点は、以下の記事を参照してください。
また、BigQuery の基本的な知識については、以下の記事を参照してください。
パイプ構文とは
パイプ構文は、BigQuery で利用可能なクエリの記述方式です。パイプ演算子(|>)で各操作をつなげることで、データの流れを明確にしながらクエリを作成、修正、デバッグができます。データの流れに沿ってコードを記述できるのが特徴であり、後述する従来の SQL の課題に対応したものといえます。
以下は、パイプ構文を用いて記述したクエリの例です。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id) |> WHERE sales_date >= '2024-04-01' |> AGGREGATE SUM(sales_amount) AS total_amount GROUP BY employee_id, employee_name |> WHERE total_amount > 10000 |> ORDER BY total_amount DESC |> LIMIT 2
パイプ構文を使用するクエリはオプティマイザーにより最適化され、従来の SQL で同等の処理をする場合と同じ処理コストで使用可能です。パフォーマンスや利用料金を最適化したい場合は、BigQuery のクエリ記述のベストプラクティスに沿うことが望ましいといえます。
- 参考 : Pipe syntax
パイプ構文の構文の詳細や使用可能な演算子は、以下の公式ドキュメントを参照してください。
- 参考 : Pipe query syntax
従来 SQL の課題
従来の SQL には、以下のような課題があります。
データ処理の順番と記述の順番が一致していない
従来の SQL の記述の順序は、データが処理される実際の順序と必ずしも一致しません。
例えば従来の SQL では、 SELECT 句、FROM 句、WHERE 句、GROUP BY 句の順で記述します。しかし実際の処理は、 FROM 句から始まります。複雑なクエリでは、この順序の不一致が、理解を難しくする場合があります。
サブクエリによるコードのネスト化
サブクエリは「副問合せ」とも呼ばれ、SQL の中に入れ子で SQL を記述することを指します。
従来の SQL で複雑なロジックを実現する場合、サブクエリが必要となるケースが多くあります。サブクエリを多用すると、コードがネスト化し、可読性が低下します。また、どのサブクエリがどの部分に影響するのかを把握するのが難しくなり、デバッグの難易度も上がり、保守性が低下します。
冗長な構文
従来の SQL では、同じ意味合いの操作を別々の句で表現する必要が出てくる場合があります。
例えば、データの絞り込みには WHERE 句と HAVING 句がありますが、適用されるタイミングや条件が異なるため、構文のルールを正しく理解して使用しないと、構文エラーや想定外の結果が取得されます。この冗長性は、SQL を複雑にし、学習コストを高める要因となっています。
パイプ構文のメリット
一方、パイプ構文には以下のメリットがあります。
柔軟性の向上
パイプ構文では句の順序に縛りがないため、SQL の記述に柔軟性が生まれます。
例えば、集計結果に対してさらに絞り込みを行う場合、従来の SQL ではサブクエリが必要となるケースがありますが、パイプ構文では |> WHERE を追加するだけで実現できます。これにより、クエリの構造をシンプルに保ちながら、複雑なロジックを表現することが可能になります。
可読性の向上
パイプ演算子を使ってデータの流れを明確に表現することで、クエリの可読性が向上します。
特に、複雑なクエリやネストしたサブクエリが多い場合、パイプ構文のメリットは際立ちます。開発者はクエリ全体の構造を容易に把握し、コードの意図を理解することができます。
デバッグ効率の向上
パイプ構文では、各パイプ演算子の結果を段階的に確認できるため、デバッグ効率が向上します。
エラーが発生した場合でも、原因を特定しやすく、迅速に修正することができます。
従来の SQL とパイプ構文の比較
具体例を元に、従来の SQL とパイプ構文の比較を行います。
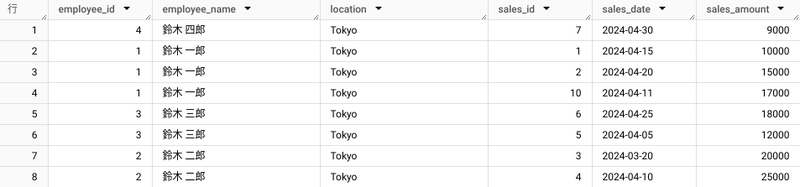
サンプルデータ
以下の employee_master テーブルと sales テーブルを例にとります。

データの取得要件
以下の要件のデータを取得します。
東京拠点に所属し、2024年4月1日以降の売上高合計が10,000以上の従業員のうち、 売上高合計が上位2位に入る従業員の ID、氏名、売上高合計を取得する。
従来の SQL の場合
従来の SQL では、以下のクエリで要件にあうデータを取得することができます。
SELECT e.employee_id, e.employee_name, SUM(s.sales_amount) AS total_sales FROM `myproject.mydataset.employee_master` AS e INNER JOIN `myproject.mydataset.sales` AS s ON e.employee_id = s.employee_id WHERE e.location = 'Tokyo' AND s.sales_date >= '2024-04-01' GROUP BY e.employee_id, e.employee_name HAVING SUM(s.sales_amount) >= 10000 ORDER BY total_sales DESC LIMIT 2;

従来型の SQL では、まず FROM 句や JOIN 句、WHERE 句が最初に処理され、その後、集計関数や GROUP BY 句の処理を行い、HAVING 句でその結果をフィルタし、 ORDER BY 句で結果をソート、LIMIT 句で表示数を絞る、という処理順になっており、記述の順番と処理の順番が一致していません。
パイプ構文の場合
パイプ構文によるクエリ全文
一方のパイプ構文では、先ほどと同じクエリを以下のように記述します。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id) |> WHERE sales_date >= '2024-04-01' |> AGGREGATE SUM(sales_amount) AS total_amount GROUP BY employee_id, employee_name |> WHERE total_amount > 10000 |> ORDER BY total_amount DESC |> LIMIT 2
パイプ構文は処理の順番と記述の順番が一致しているため、処理の流れを考えながら、順番に記述していくことができます。
employee_master テーブルを取得
はじめに、employee_master テーブルの全体を取得します。
FROM `myproject.mydataset.employee_master`

東京拠点のみのレコードでフィルタ
location = 'Tokyo' でフィルタします。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo'

sales テーブルと結合
sales テーブルと employee_id を内部結合(INNER JOIN)します。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id)
2024年4月1日以降のレコードでフィルタ
sales_date >= '2024-04-01' でフィルタを行います。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id) |> WHERE sales_date >= '2024-04-01'

従業員の単位で売上を集約
employee_id 列と employee_name 列で sales 列を集計します。
パイプ構文で、集計を行う場合は、AGGREGATE パイプ演算子を使用します。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id) |> WHERE sales_date >= '2024-04-01' |> AGGREGATE SUM(sales_amount) AS total_amount GROUP BY employee_id, employee_name

売上高合計が10,000の従業員でフィルタ
total_amount > 10000 でフィルタを行います。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id) |> WHERE sales_date >= '2024-04-01' |> AGGREGATE SUM(sales_amount) AS total_amount GROUP BY employee_id, employee_name |> WHERE total_amount > 10000

売上高合計で降順にソート
total_amount 列で降順に並び替えます。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id) |> WHERE sales_date >= '2024-04-01' |> AGGREGATE SUM(sales_amount) AS total_amount GROUP BY employee_id, employee_name |> WHERE total_amount > 10000 |> ORDER BY total_amount DESC

上位2位のデータのみにフィルタ
limit 2 で、表示する行数のフィルタを行います。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id) |> WHERE sales_date >= '2024-04-01' |> AGGREGATE SUM(sales_amount) AS total_amount GROUP BY employee_id, employee_name |> WHERE total_amount > 10000 |> ORDER BY total_amount DESC |> LIMIT 2
従来の SQL と同じ結果がパイプ構文でも取得できました。
山崎 曜(記事一覧)
クラウドソリューション部
元は日系大手SIerにて金融の決済領域のお客様に対して、PM/APエンジニアとして、要件定義〜保守運用まで全工程に従事。
Google Cloud 全 11 資格保有。
フルスタックな人材を目指し、日々邁進。