


G-gen又吉です。当記事では、Googleの生成AI、PaLM 2(言語基盤モデル)のモデルチューニングについて解説します。
はじめに
Generative AI support on Vertex AI
先日 Vertex AI でも Generative AI がサポートされました。Generative AI モデル (生成 AI モデル、または基盤モデル) の裏側は PaLM 2 が利用されており、多言語、推論、コーディング機能が強化された最先端の大規模言語モデル (LLM) です。
Vertex AI の Generative AI サポートについての詳細は以下の記事をご参照下さい。
基盤モデル
Vertex AI では、デフォルトでいくつかの基盤モデルが提供されています。これらの基盤モデルは、一般的なユースケースに対応するような設計になっております。
2023 年 8 月現在、以下の基盤モデルが提供されています。
| No | モデル名 | 説明 | モデルチューニングサポート |
|---|---|---|---|
| 1 | text-bison | 自然言語の指示に従うような微調整された基盤モデルです。要約 / 分類 / 感情分析 / エンティティ抽出 / アイデア出し など汎用的な用途で利用できます。 | ◯ |
| 2 | textembedding-gecko | テキスト入力のベクトル化、つまりエンべディングを返します。 | - |
| 3 | chat-bison | 会話のユースケース用にファインチューニング (微調整) された基盤モデルです。 | - |
| 4 | code-bison | 自然言語に基づいたコード生成用に微調整された基盤モデルです。 | ◯ |
| 5 | codechat-bison | コード関連の質問に役立つチャットボット用に微調整された基盤モデル | ◯ |
| 6 | code-gecko | 記述されたコードのコンテキストに基づいてコード補完を提案するように微調整された基盤モデルです。 | - |
参考:Available models in Generative AI Studio
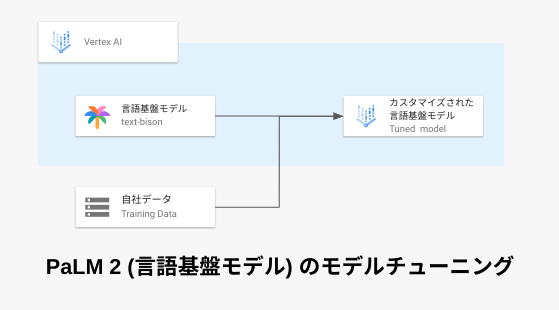
モデルチューニングとは
ユースケース
Vertex AI の基盤モデルは一般的なユースケースに合わせて微調整されておりますが、さらに特定のユースケースに対応させたい場合、基盤モデルに対しモデルチューニングを行いパフォーマンスを向上させることができます。
特定のユースケースとして、以下のような例が考えられます。
- 特定のフォーマットに整形して出力させたい場合
- 企業独自の製品カテゴリに分類したい場合
- 個人を特定できる情報 (PII) を削除したい場合
参考:Scenarios to use model tuning
仕組み
モデルチューニングは、タスクの例 (入力と予期される出力のペア) を含むトレーニングデータセットを基盤モデルに提供する必要があります。
モデルチューニングを実行すると、モデルは目的の動作を行うための追加のパラメーターを学習します。 そしてモデルチューニングの出力としては、新しく学習したパラメーターと元のモデルの組み合わせでできた新しいモデルです。
2023 年 8 月現在、モデルチューニングをサポートしている基盤モデルは以下となります。
- text-bison
- code-bison
- codechat-bison
参考:Tune language foundation models
トレーニングデータセット
サンプル数
モデルトレーニングに使用されるトレーニングデータセットには、モデルに実行させたいタスクに合わせた入出力のサンプルが含まれています。
トレーニングデータセットには最低 10 個のサンプルが必要であり、良い結果を得るには少なくとも 100 個のサンプルを含めることを推奨してます。
一般的に、より多くのサンプルを与えるほど、より良い結果が得られるとされています。
参考:Prepare your model tuning dataset
トレーニングデータセット形式
モデル調整データセットは、 JSON Lines (JSONL) 形式である必要があります。
各行は、input_text でモデルへのプロンプトを含む入力フィールドと、output_text で予想するレスポンスの例を含む出力フィールドで構成されます。
以下はトレーニングデータセット例となります。
{"input_text": "質問: 北京には何人住んでいますか? 本文: 2,100 万人以上の住民を抱える北京は、世界で最も人口の多い首都であり、上海に次ぐ中国第 2 の都市です。中国北部に位置し、北京は、南東に隣接する天津を除き、大部分が河北省に囲まれており、これら 3 つの部門を合わせて京津市を形成しています。 巨大都市と中国の首都圏。", "output_text": "2,100 万人以上"}
{"input_text": "質問: ルイジアナ州には教区がいくつありますか? 本文: 米国ルイジアナ州は、米国の他の 48 州が郡に分割されているのと同じように、64 の教区に分割されています。 アラスカはいくつかの自治区に分かれています。", "output_text": "64"}
注意点
モデルチューニングには、以下 2 つの注意点がございます。
1 つ目に、基盤モデルをチューニングしたからと言って、一般的な知識が向上する保証はありません。
2 つ目に、チューニングされた基盤モデルは必ずしもコンテキストを考慮するとは限りません。したがって、関連するコンテキストがある場合は、明示的にプロンプト コンテキストを入力するようにしましょう。例えば、「あなたは小学校の教員です」などのペルソナを設定する等。
参考:Design chat prompts - Context (optional)
モデルチューニングジョブの実行
概要
トレーニングデータセットが準備できたら、Cloud Storage バケットへアップロードします。ジョブの実行時に新規バケットを作成することもできますし、既存バケットに予めファイルを保存し参照することもできます。
モデルチューニングが完了したら、チューニングされたモデルは Vertex AI エンドポイントに自動的にデプロイ されます。また、Generative AI Studio で操作することもできます。
サンプルコード
モデルチューニングジョブの作成は、Google Cloud コンソール、API、または Vertex AI SDK for Python を使用して作成できます。
以下は REST API の pipelineJobs メソッドを使用した例です。
TUNING_LOCATION={モデルチューニングが行われるリージョン}
PROJECT_ID={プロジェクト ID}
DISPLAY_NAME={PipelineJob の表示名}
GCS_OUTPUT_DIRECTORY={チューニングされたモデルを出力するバケットの URI}
MODEL_DISPLAY_NAME={PipelineJob によって作成されたモデルの表示名}
DATASET_URI={モデルチューニングデータセットを格納しているバケットの URI}
TRAIN_STEP={モデル調整のために実行するステップの数}
LEANING_RATE={学習率の値 (推奨は 1.0)}
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
https://${TUNING_LOCATION}-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/${TUNING_LOCATION}/pipelineJobs?pipelineJobId=tune-large-model-$(date +"%Y%m%d%H%M%S") -d \
$'{
"displayName": "'${DISPLAY_NAME}'",
"runtimeConfig": {
"gcsOutputDirectory": "'${GCS_OUTPUT_DIRECTORY}'",
"parameterValues": {
"location": "us-central1",
"project": "'${PROJECT_ID}'",
"large_model_reference": "text-bison@001",
"model_display_name": "'${MODEL_DISPLAY_NAME}'",
"train_steps": '${TRAIN_STEP}',
"dataset_uri": "'${DATASET_URI}'",
"learning_rate": '${LEANING_RATE}'
}
},
"templateUri": "https://us-kfp.pkg.dev/ml-pipeline/large-language-model-pipelines/tune-large-model/v3.0.0"
}'
サポートされてるリージョン
2023 年 8 月現在、以下のリージョンがサポートされています。
| No | リージョン | 使用リソース | バッチサイズ |
|---|---|---|---|
| 1 | us-central1 | [Restricted image training Nvidia A100 80GB GPUs per region] × [8 の倍数] | 8 |
| 2 | europe-west4 | [Restricted image training TPU V3 pod cores per region] × [64 の倍数] | 24 |
また、利用するリージョンによって、使用リソースが異なります。
特に、GPU や TPU が含まれるため、事前に割り当てが十分あることを確認する必要があります。十分な割り当てがない場合は、クォータ制限の引き上げをリクエストしてください。
参考:Request a higher quota limit
参考:Tune language foundation models - Quota
トレインステップ
トレインステップを計算する前に、エポック (epoch) という概念を知っておく必要があります。
エポックとは、トレーニングデータセット全体を 1 回処理することをいいます。
基盤モデルのような大規模言語モデル (LLM) は、ディープラーニングモデルの一種です。
ディープラーニングモデルは、パラメータ数が多く、トレーニング時にエポック数を増やし学習させることで精度を向上させます。しかしエポック数が多すぎると過学習になる恐れがあるので、 多すぎず少なすぎないエポック数を指定する必要があります。
train_steps オプションでは、トレーニングデータセットのサンプル数と、モデルチューニングが行われるリージョンのバッチサイズによってエポック数を定義できます。
例えば、トレーニングデータセットに 240 個のサンプルがある場合、
us-central1 ではバッチサイズが 8 なのでデータセット全体を 1 回処理 (1 エポック) するのに 240 / 8 = 30 ステップ かかります。一方で、europe-west4 ではバッチサイズが 24 なのでデータセット全体を 1 回処理 (1 エポック) するのに 240 / 24 = 10 ステップ かかります。
参考:GitHub - llm-pipeline-examples
料金
モデルチューニングの料金は、モデルチューニングで使用した Vertex AI のカスタムトレーニングで使用したリソース料金に依存します。
例えば、us-central1 で、Nvidia A100 80GB GPUs を 8 つ使用し、トレーニング時間に 1 時間費やしたと仮定すると以下のような計算式になります。
4.517292 [USD/hour] × 8 × 1 [hour] ≒ 36 [USD]
トレーニングにかかる時間は、トレーニングデータセットの量とエポック数によって変動します。
参考:Vertex AI pricing - Custom-trained models
チューニングされたモデルの呼び出し
チューニングされたモデルは Vertex AI エンドポイントデプロイされており、Generative AI Studio で選択することもできます。
以下は、Vertex AI SDK for Python の TextGenerationModel を使用してチューニングされたモデルを読み込んでいます。
import vertexai from vertexai.preview.language_models import TextGenerationModel TUNED_MODEL_NAME = {チューニングされたモデル名 : [projects/PROJECT_ID/locations/LOCATION/models/MODEL_ID] 形式} model = TextGenerationModel.get_tuned_model(TUNED_MODEL_NAME)
調整されたモデルの MODEL_ID は、 Vertex AI Model Registry 内で確認できます。
トラブルシューティング
モデルチューニングジョブを実行すると、以下のエラーのように 500 のエラーコードと Internal error encountered. のエラーメッセージが返される場合の対処法を紹介します。
{
"error": {
"code": 500,
"message": "Internal error encountered.",
"status": "INTERNAL"
}
}
以下の cURL コマンドを実行して、空の Vertex AI データセットを作成することで先述のエラーは回避できます。
DATASET_NAME={Vertex AI データセットの表示名}
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://${TUNING_LOCATION}-aiplatform.googleapis.com/ui/projects/${PROJECT_ID}/locations/${TUNING_LOCATION}/datasets \
-d '{
"display_name": "'${DATASET_NAME}'",
"metadata_schema_uri": "gs://google-cloud-aiplatform/schema/dataset/metadata/image_1.0.0.yaml",
"saved_queries": [{"display_name": "saved_query_name", "problem_type": "IMAGE_CLASSIFICATION_MULTI_LABEL"}]
}'
コマンドが完了したら、約 5 分置いてモデルチューニングを再実行します。
又吉 佑樹(記事一覧)
クラウドソリューション部
はいさい、沖縄出身のクラウドエンジニア!
セールスからエンジニアへ転身。Google Cloud 全 11 資格保有。Google Cloud Champion Innovator (AI/ML)。Google Cloud Partner Top Engineer 2024。Google Cloud 公式ユーザー会 Jagu'e'r でエバンジェリスト。好きな分野は生成 AI。
Follow @matayuuuu