


G-gen の又吉です。当記事では、Goolge Cloud の Vertex AI でサポートされている生成 AI 機能(総称 Generative AI on Vertex AI)を解説します。
- 概要
- Vertex AI Studio
- Gen AI SDK
- Vertex AI Model Garden
- 生成 AI モデルへのリクエスト
- アクセス制御
- 料金
- Google のスタンス
- Gemini 系プロダクト

概要
Generative AI on Vertex AI とは
Vertex AI は、Google Cloud の統合された機械学習プラットフォームです。Vertex AI では、生成 AI に関する諸機能もサポートされています。Gemini をはじめとする生成 AI モデルを API 経由で呼び出せたり、Web UI で簡単に AI モデルの機能を試せる Vertex AI Studio、Claude や Llama などサードパーティのモデルを購入して呼び出せる Vertex AI Model Garden などがあります。これらの生成 AI 機能は、総称して Generative AI on Vertex AI(Vertex AI の生成 AI)と呼ばれます。
- 参考 : Vertex AI の生成 AI の概要

Vertex AI の生成 AI 関連以外の機能については、以下の記事もご参照下さい。
生成 AI とは
生成 AI(Generative AI) とは、テキストや画像、動画などのコンテンツを生成するのに特化した AI(人工知能)の総称であり、大規模言語モデル(LLM)などのテクノロジーに基づいています。単なるテキスト生成に留まらず、ソースコードや音声、画像、動画なども生成できます。
Google が提供するコンシューマ向け生成 AI の代表的なサービスとして、Gemini アプリがあります。
- 参考 : Gemini アプリ
上記の Gemini アプリは PC 向けおよびモバイル端末向けのアプリケーションであり、API が公開されておりません。開発者が自社のアプリケーションに生成 AI を組み込んだり、独自の業界知識に基づいたファインチューニングを行うためには、エンタープライズに特化して Google Cloud 経由で提供されている Generative AI on Vertex AI を利用します。
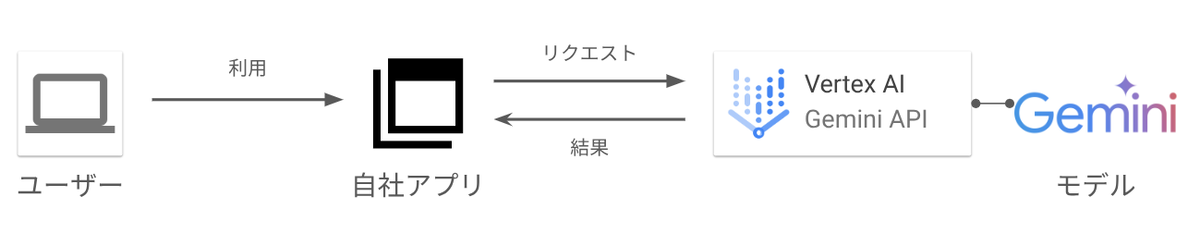
Vertex AI で利用可能な生成 AI モデルの代表は、Gemini です。2025年7月現在、Gemini には Gemini 2.5 Pro、Gemini 2.5 Flash などが存在します。Gemini は数々のベンチマークで高得点を記録する、非常に優れた生成 AI モデルです。
Vertex AI Studio
Vertex AI Studio は、Google Cloud の Web コンソール画面から、基盤モデルのプロンプトやパラメータ値を迅速にテストしてプロンプト設計をスムーズに行うことができる機能です。気軽に Gemini などのモデルの性能を試験することができます。
Vertex AI Studio では、Gemini のみならず、画像生成モデルである Imagen や、動画生成モデルである Veo を試用することもできます。
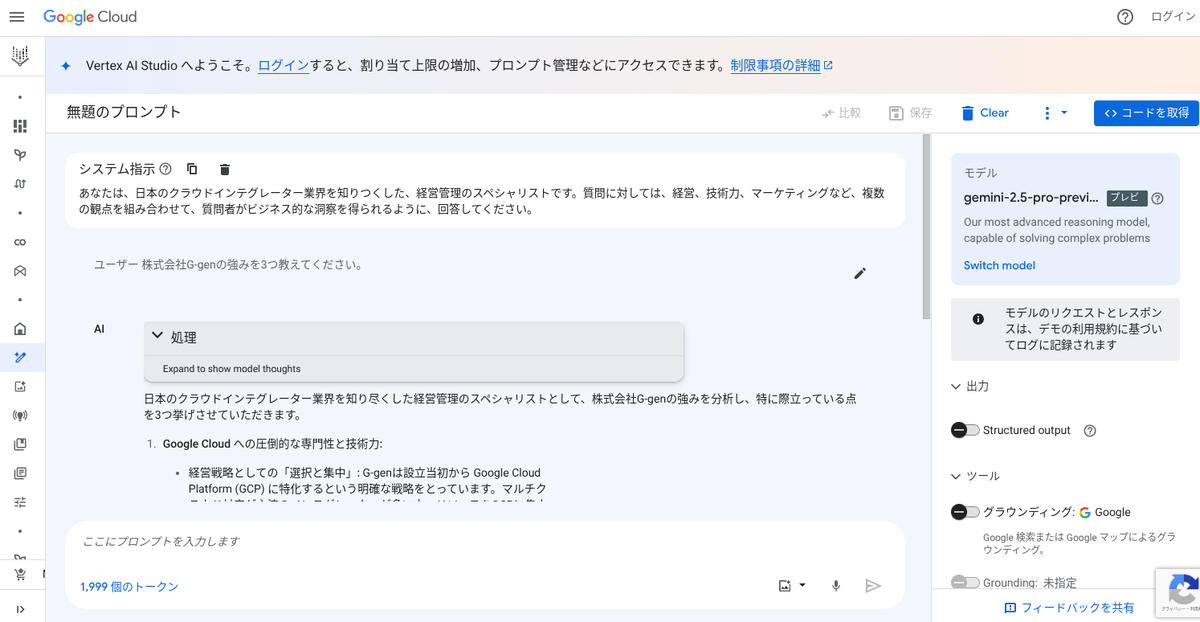
この画面からは、コンソール画面で入力したプロンプトとパラメータ値が含まれた形で、Vertex AI SDK for Python などで記述されたサンプルコードや、curl で実行できる REST API のサンプルコードが表示されます。これらのサンプルコードを開発に活かすことができます。
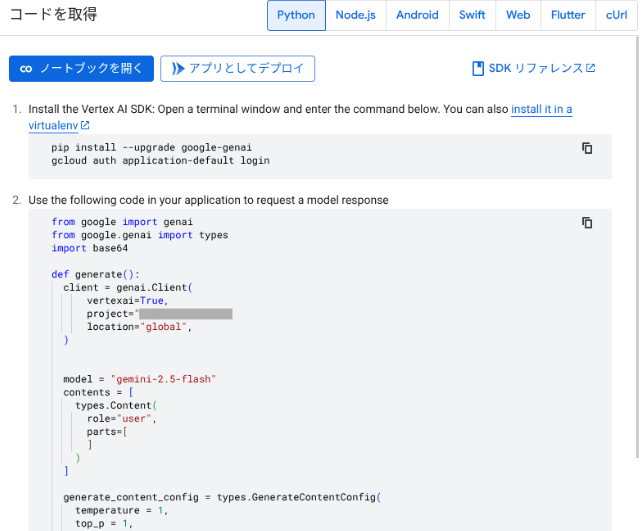
Vertex AI Studio の利用手順については、以下の記事も参照してください。
Gen AI SDK
Vertex AI 経由で Gemini 等のモデルを呼び出すには、各プログラミング言語用に提供されている Google Gen AI SDK を利用します。この SDK により、開発者は容易に Vertex AI 経由で生成 AI モデルを独自のアプリケーションに組み込むことができます。
Gen AI SDK は、Python、Go、Node.js、Java などの言語に対して提供されています。
- 参考 : Google Gen AI SDK
Google Gen AI SDK を用いて、呼び出し先の Google Cloud プロジェクトやモデル名を指定することで、生成 AI モデルにリクエストを送信することができます。この SDK は個人や小規模開発者向けの生成 AI プラットフォームである Google AI Studio とも共通しています。
なお、以前は Vertex AI 経由で生成 AI モデルを呼び出す際に Vertex AI SDK が使われていましたが、Vertex AI SDK 経由での生成 AI モデルは2026年6月に廃止予定です。以前から Vertex AI SDK を使っている場合、Google Gen AI SDK に移行する必要があります。以下のドキュメントを参照してください。
Vertex AI Model Garden
Vertex AI Model Garden は、機械学習モデルのマーケットプレイスです。さまざまなサードパーティベンダーから公開される機械学習モデルと API のアセットを購入して、Vertex AI 経由で呼び出せるようにすることができます。
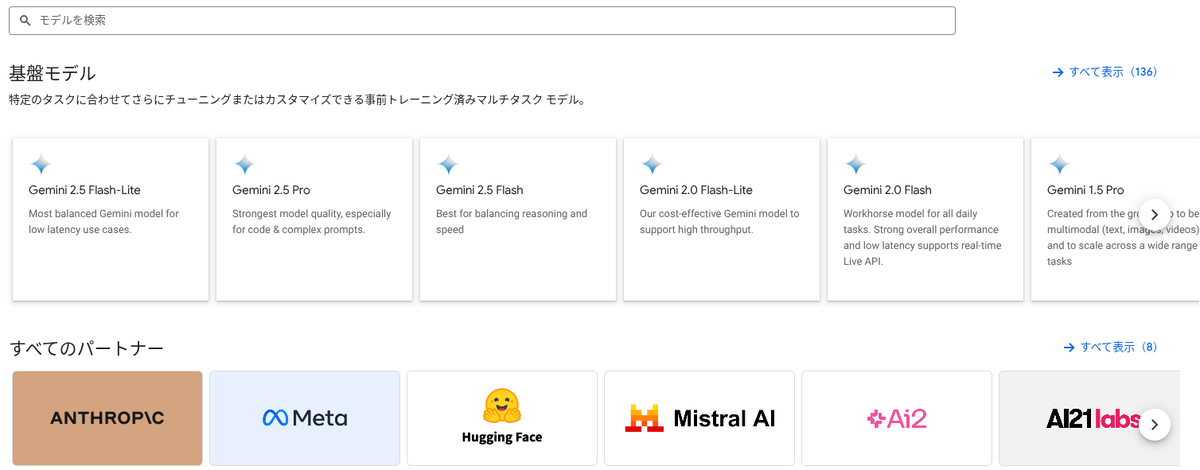
Model Garden で利用できるモデルカテゴリは以下のとおりです。
| No | モデルカテゴリ | 説明 |
|---|---|---|
| 1 | 基盤モデル | Vertex AI Studio、Vertex AI API、Vertex AI SDK などを使用して、特定のタスクに合わせて調整またはカスタマイズできる、事前トレーニングされた基盤モデル |
| 2 | ファインチューニング可能なモデル | カスタムノートブックまたはパイプラインを使用して微調整できるモデル |
| 3 | タスク固有のソリューション | すぐに使用可能な事前構築済みモデル |
生成 AI モデルへのリクエスト
プロンプト
プロンプトとは、簡単に言うと言語モデルに送信するリクエストのことです。
プロンプトには、質問だけでなく、コンテキストや指示、例などを含めることができ、モデルはプロンプトを受け取ると、テキストやソースコード、画像等を生成しユーザーにレスポンスします。
特に、大規模言語モデルは膨大な量のテキストデータから単語間のパターンと関係を学習しており、プロンプトの設計がうまくできればモデルの精度を向上させることができます。
プロンプトをより良くするためには、「目的」「指示」「出力形式」を明記したり、「システム指示(system instruction)」を用います。またモデルの振る舞いを「役割(ペルソナ)」として示したり、出力の例を数個提示する Few-shot prompting などの技術が知られています。
以下のドキュメントでは、より良いプロンプトを設計するための戦略が紹介されています。
- 参考 : プロンプトの概要
- 参考 : プロンプト戦略の概要
- 参考 : カスタム Gem 作成のヒント
公式ドキュメントにプロンプトのサンプルが提供されているので、まずはこちらのサンプルからニーズにあうプロンプトがあるか探してみることをおすすめします。
- 参考 : 生成 AI のプロンプト サンプル
パラメータ
モデルに送信するリクエストには、モデルのレスポンスを制御するパラメータを含めることができます。代表的なパラメータ値を以下に記載します。
| No | パラメータ値 | 概要 |
|---|---|---|
| 1 | Max output tokens | モデルが生成できるトークンの最大数です。参考値として、1 トークンは約 4 文字、100 トークンは約 60 ~ 80 英単語に相当。 |
| 2 | Top-K | モデルが最適なトークンを選択する際、最も確率の高い上位 K 個のトークンがサンプリングされます。 |
| 3 | Top-P | 確率の高い順にトークンを並べ、確率の合計が上位 P の値に等しくなるまでフィルタリングされます。Top-P は 0.0 ~ 1.0 の値をとります。 |
| 4 | Temperature | Temperature は、トークン選択のランダム性を制御し、0.0 ~ 1.0 の値を取ります。Temperature が低い (0.0 に近い) と、確率の高いトークン、つまり、より真実または正しいレスポンスが生成されます。逆に Temperature が高い (1.0 に近い) と、より多様な結果や予期しない結果を得ることができます。 |
モデルに送信されるリクエストに対して、最適なトークンを選択するステップは以下のとおりです。
- Top-K により最も高い確率を持つ上位 K 個のトークンがサンプリング
- Top-K でサンプリングされた K 個のトークンから、Top-P に基づいてフィルタリング
- Top-P でフィルタリングされたトークンから、Temperature に基づいて最終的にトークンが選択される
例えば、アイディア出しを行いたい場合、予期しない結果を得たいため Top-K と Top-P、Temperature を上げてみるといいでしょう。
参考:パラメータ値を試す
アクセス制御
Vertex AI 経由で生成 AI 機能を使用するには、呼び出し元の Google アカウントまたは Google グループ、あるいはサービスアカウント等に、適切な権限が付与されている必要があります。
以下の事前定義されたロールを付与することで、Vertex AI で Generative AI 機能へのアクセスを許可できます。
- Vertex AI 管理者(
roles/aiplatform.admin) - Vertex AI ユーザー(
roles/aiplatform.user)
参考:アクセス制御
料金
概要
Vertex AI での生成 AI の課金体系は、入力や出力のボリュームに応じた従量課金です。入出力のボリュームは、モデルにより文字数、またはトークンという単位で計測されます。
例として、2025年7月現在、Gemini 2.5 Pro の課金体系は以下です(20万以下のコンテキストウインドウの入力の場合)。入力した画像、動画、テキストの量と、出力された生成コンテンツの量に応じた従量課金となります。入出力のサイズは、トークンと呼ばれる単位でカウントされます。
| 課金軸 | 料金単価 |
|---|---|
| 入力トークン | $1.25 / 100万トークン |
| 出力トークン (テキスト) | $10 / 100万トークン |
モデルによって料金単価や計測方法が異なるため、詳細は以下の公式ページを参照してください。
Google のスタンス
責任ある AI
Gemini 等の Google が公開するモデルは、Google の AI 原則に従って設計されています。
- 参考 : Our AI Principles
しかしながら、生成 AI の生成は非決定論的であり、誤った情報や不適切なコンテンツを生成してしまう可能性はゼロではありません。開発者はこれらのリスクを考慮しつつ、安全かつ責任を持ってテスト・デプロイを行うことが重要です。
安全フィルタ
Vertex AI 経由での Gemini モデル等の呼び出し時には、安全フィルタのしきい値を設定することで、基盤モデルから有害なレスポンスが返ってくる可能性を調整できます。
ヘイトスピーチ、嫌がらせ、性的に露骨な表現、危険なコンテンツなどに対してフィルタを設定し、フィルタの強度も指定可能です。
- 参考 : 安全フィルタを構成する
データガバナンス
Google Cloud 経由で提供される生成 AI モデルでは、入出力データは保護されます。サービス規約上、Google はユーザーのデータを利用して、AI/ML モデルを再トレーニングしたり、ファインチューニングすることはありません。
- 参考 : 生成 AI とデータ ガバナンス
なお、Google は AI/ML Privacy Commitment を業界で初めて公表した企業です。
Gemini 系プロダクト
Google Cloud 等で提供される Gemini 系プロダクトの一覧については、以下の記事も参照してください。
又吉 佑樹(記事一覧)
クラウドソリューション部
はいさい、沖縄出身のクラウドエンジニア!
セールスからエンジニアへ転身。Google Cloud 全 11 資格保有。Google Cloud Champion Innovator (AI/ML)。Google Cloud Partner Top Engineer 2024。Google Cloud 公式ユーザー会 Jagu'e'r でエバンジェリスト。好きな分野は生成 AI。
Follow @matayuuuu