


G-gen の佐々木です。当記事では Google Cloud の機械学習ワークフローオーケストレーションツールである Vertex AI Pipelines を解説します。
- MLOps と ML パイプラインの必要性
- Vertex AI Pipelines
- パイプラインの定義
- パイプライン コンポーネント
- パイプライン テンプレート
- パイプラインの実行
- その他 Vertex AI ツールとの連携
- 料金

MLOps と ML パイプラインの必要性
MLOps(Machine Learning Operations)とは、サービスのデリバリー速度や信頼性の向上、関係者間のオーナーシップ構築を目的とする DevOps を、機械学習(ML)システムに適用する取り組み・手法です。
ML モデルは、データの収集、加工、トレーニングなどの過程を経て構築され、本番環境でサービングされます。この開発サイクルは通常のソフトウェア開発と異なり、以下のような特性があります。
- ML モデルの開発にはデータ加工の手法、アルゴリズム選択、パラメータ構成などの試行錯誤を伴う実験的な性質があり、モデルのトレーニングとテストは繰り返して行われる
- ML モデルが予測対象とする世界は絶えず変化し続けており、モデルの予測精度を維持するためには、変化をモニタリングし、必要に応じて新しいデータでモデルを再トレーニングする必要がある
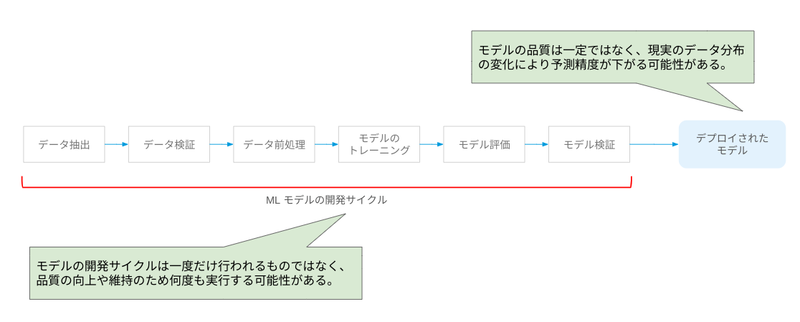
そのため、ML モデルの開発・運用においては DevOps の要素でもある CI/CD のほかに、MLOps 特有の要素である継続的なモデルのトレーニング(Continuous Training、CT)を実現する必要があります。
ML パイプラインは、ML モデルの開発サイクルの各要素を一連のステップとした、CT を実現するための再利用可能なパイプラインです。
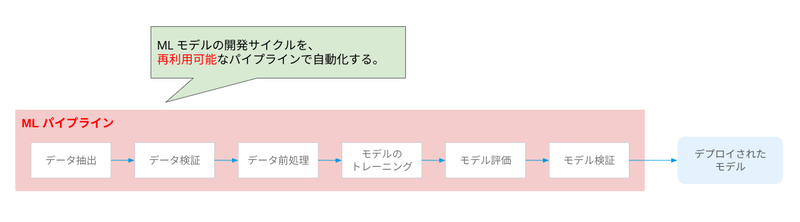
Vertex AI Pipelines
Vertex AI は Google Cloud における ML サービスの統合プラットフォームであり、ML ワークロードを展開するための様々なツールが提供されています。
Vertex AI Pipelines は Vertex AI で提供されるツールの1つであり、Google Cloud 上で複雑な ML ワークフローを実行するパイプラインを構築・実行することができます。
ML パイプラインの実行はサーバーレスな環境で実行されるため、ユーザー側でインフラストラクチャの管理やスケーリングの実装をする必要がありません。
また、他の Vertex AI ツールとの連携により、パイプラインのスケジュール実行や、パイプラインで生成されたアーティファクト(加工したデータやモデル、モデルの評価など)の管理・分析、開発したモデルのデプロイなどをシームレスに行うことができます。
- 参考 : Introduction to Vertex AI Pipelines
- 参考 : Architecture for MLOps using TensorFlow Extended, Vertex AI Pipelines, and Cloud Build
パイプラインの定義
2種類のインターフェース
Vertex AI Pipelines では、DAG(有向非巡回グラフ)としてワークフローを記述し、YAML 形式にコンパイルされたファイルを使用することで、定義された ML パイプラインを実行します。
このパイプラインを定義するための Python SDK インターフェースとして、Kubeflow Pipelines SDK(KFP) と TensorFlow Extended SDK(TFX)の2種類が提供されています。
TensorFlow Extended SDK はテラバイト単位の大規模な構造化データまたはテキストデータを処理する際に推奨されており、それ以外のユースケースではシンプルな記述で柔軟なタスクを処理できる Kubeflow Pipelines SDK の利用が推奨されています。
Kubeflow Pipelines SDK
Kubeflow Pipelines SDK は、任意のコンテナイメージや関数をパイプラインの要素(コンポーネント)として定義することができるインターフェースです。
TensorFlow や PyTorch、scikit-learn など、様々な ML フレームワークを使用した独自のコンポーネント(カスタム コンポーネント)を開発、管理することができます。
また、Google Cloud パイプライン コンポーネントとして、他の Google Cloud サービスを利用する事前定義済みコンポーネントをパイプライン定義に組み込むこともできます。
TensorFlow Extended SDK
TensorFlow Extended SDK は、スケーラブルかつ高いパフォーマンスを必要とするタスク向けの ML パイプラインを定義するインターフェースです。
TensorFlow、Keras を使用した開発に最適化されており、TensorFlow Data Validation(データ検証)や TensorFlow Transform(前処理)、TensorFlow Model Analysis(モデル評価)といった、典型的な ML タスクを実行する標準コンポーネントを利用することができます。
- 参考 : The TFX User Guide
パイプライン コンポーネント
コンポーネントの基本
Vertex AI Pipelines では、データの抽出や加工、モデルのトレーニングやデプロイなどの ML ワークフローの各ステップをコンポーネントとして定義し、それを組み合わせることでパイプラインを構成します。
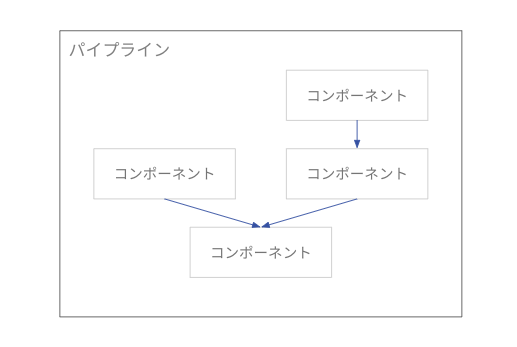
コンポーネントはデータセットやモデル、ハイパーパラメータなどの入力を受け取って処理を行い、その出力を次のコンポーネントの入力として渡すことができます。
Google Cloud パイプライン コンポーネント
概要
Google Cloud パイプライン コンポーネントは Google によって事前定義されたビルド済み Kubeflow Pipelines コンポーネントであり、Vertex AI の各種ツールや BigQuery、Dataflow といった他の Google Cloud サービスの操作をパイプラインに組み込むことができます。
Google Cloud パイプライン コンポーネントの例
以下は、Google Cloud パイプライン コンポーネントとして提供されている事前定義コンポーネントの一例です。
| コンポーネント | 説明 |
|---|---|
| BigqueryQueryJobOp | BigQuery でクエリを実行する。 |
| TabularDatasetCreateOp | Cloud Storage や BigQuery をデータソースとして、Vertex AI で使用できる表形式データセットを作成する。 |
| AutoMLTabularTrainingJobRunOp | AutoML で表形式データセットを使用したトレーニング ジョブを実行する。 |
| BigqueryCreateModelJobOp | BigQuery ML によるモデルの作成ジョブを実行する。 |
| CustomTrainingJobOp | Vertex AI のカスタム トレーニング ジョブを実行する。 |
| DataflowPythonJobOp | Apache Beam Python SDK で記述されたジョブを Dataflow で実行する。 |
| WaitGcpResourcesOp | Google Cloud リソースの実行が完了するまで待機する(2025年5月現在、Dataflow ジョブに対してのみ有効)。 |
| DataprocSparkBatchOp | Apache Spark のバッチジョブを Dataproc で実行する。 |
| ModelUploadOp | モデルを Vertex AI Model Registry にアップロードする。 |
| EndpointCreateOp | Vertex AI Endpoints のエンドポイントを作成する。 |
| ModelDeployOp | Vertex AI Endpoints のエンドポイントにモデルをデプロイする。 |
| ModelBatchPredictOp | 指定したモデルを使用して、Vertex AI Batch Predictions によるバッチ予測を行う。 |
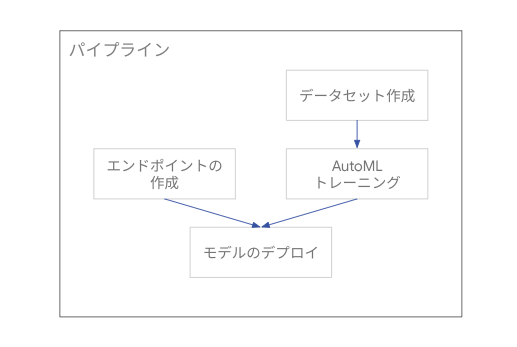
パイプラインの例
パイプライン定義は Jupyter Notebook 等の開発環境を使用して記述します。
以下は、Google Cloud パイプライン コンポーネントを使用する Kubeflow Pipelines SDK による ML パイプラインの例です。
このパイプラインでは、公開されているデータソースから画像データセットを作成し、AutoML で画像分類モデルのトレーニングを行ったあと、作成したモデルを Vertex AI Endpoints のエンドポイントにデプロイする一連のステップが定義されています。
# Kubeflow Pipelines SDK, Vertex AI Python SDK のインポート import kfp from google.cloud import aiplatform # Google Cloud パイプライン コンポーネントのインポート from google_cloud_pipeline_components.v1.dataset import ImageDatasetCreateOp from google_cloud_pipeline_components.v1.automl.training_job import AutoMLImageTrainingJobRunOp from google_cloud_pipeline_components.v1.endpoint import EndpointCreateOp, ModelDeployOp project_id = "myproject" pipeline_root_path = "gs://mybucket/pipeline-root/path/" # パイプライン定義の例 @kfp.dsl.pipeline( name="automl-image-training-v2", pipeline_root=pipeline_root_path) def pipeline(project_id: str): # データセットを作成するコンポーネント ds_op = ImageDatasetCreateOp( project=project_id, display_name="flowers", gcs_source="gs://cloud-samples-data/vision/automl_classification/flowers/all_data_v2.csv", import_schema_uri=aiplatform.schema.dataset.ioformat.image.single_label_classification, ) # AutoML によるトレーニングを実行するコンポーネント training_job_run_op = AutoMLImageTrainingJobRunOp( project=project_id, display_name="train-iris-automl-mbsdk-1", prediction_type="classification", model_type="CLOUD", dataset=ds_op.outputs["dataset"], model_display_name="iris-classification-model-mbsdk", training_fraction_split=0.6, validation_fraction_split=0.2, test_fraction_split=0.2, budget_milli_node_hours=8000, ) # Vertex AI Endpoints のエンドポイントを作成するコンポーネント create_endpoint_op = EndpointCreateOp( project=project_id, display_name = "create-endpoint", ) # エンドポイントにモデルをデプロイするコンポーネント model_deploy_op = ModelDeployOp( model=training_job_run_op.outputs["model"], endpoint=create_endpoint_op.outputs['endpoint'], automatic_resources_min_replica_count=1, automatic_resources_max_replica_count=1, )
パイプライン定義は、以下のように YAML 形式にコンパイルし、Vertex AI Pipelines で実行可能な状態にします。
from kfp import compiler compiler.Compiler().compile( pipeline_func=pipeline, # 定義したパイプライン package_path='image_classif_pipeline.yaml' )
YAML ファイルにはパイプラインの実行に必要な情報がすべて含まれます。以下はこの例で作成できる YAML ファイルの一部抜粋です。
# PIPELINE DEFINITION # Name: automl-image-training-v2 # Inputs: # project_id: str components: comp-automl-image-training-job: executorLabel: exec-automl-image-training-job inputDefinitions: artifacts: base_model: artifactType: schemaTitle: google.VertexModel schemaVersion: 0.0.1 description: Only permitted for Image Classification models. If it is specified, the new model will be trained based on the `base` model. Otherwise, the new model will be trained from scratch. The `base` model must be in the same Project and Location as the new Model to train, and have the same model_type. isOptional: true dataset: artifactType: schemaTitle: google.VertexDataset schemaVersion: 0.0.1 description: The dataset within the same Project from which data will be used to train the Model. The Dataset must use schema compatible with Model being trained, and what is compatible should be described in the used TrainingPipeline's [training_task_definition] [google.cloud.aiplatform.v1beta1.TrainingPipeline.training_task_definition]. For tabular Datasets, all their data is exported to training, to pick and choose from. # 以下省略
- 参考 : Build a pipeline
カスタムコンポーネント
Kubeflow Pipelines SDK では、ユーザーが記述した処理をカスタムコンポーネントとしてパイプラインに組み込むことができます。
以下の例では、入力された2つの数値を加算するコンポーネントと、入力された数値をログに出力するコンポーネントの2つを作成し、それらを順に実行するパイプラインを定義しています。
from kfp import dsl pipeline_root_path = "gs://mybucket/pipeline-root/path/" # 入力された2つの数値を加算するカスタムコンポーネント @dsl.component( base_image='python:3.12', # コンポーネントを実行するコンテナイメージ packages_to_install=['google-cloud-storage'] # 必要に応じてライブラリを追加できる(この例では使用しない) ) def add_numbers( num1: float, # 入力パラメータ1 num2: float # 入力パラメータ2 ) -> float: # 2つの数値を加算する print(f"Adding {num1} and {num2}") result = num1 + num2 print(f"Result: {result}") return result # 計算結果を出力として返す # 入力された数値を出力するカスタムコンポーネント @dsl.component( base_image='python:3.12' ) def print_result( result_value: float # 入力パラメータ ): # 受け取った数値を表示する print(f"The final result is: {result_value}") # パイプライン定義 @dsl.pipeline( name='custom-component-pipeline-sample', description='A simple pipeline using custom components.', pipeline_root=pipeline_root_path ) def my_custom_pipeline( input1: float = 10.5, # パイプラインの入力パラメータ (デフォルト値) input2: float = 5.2 ): # ステップ 1: add_numbers コンポーネントを実行 add_task = add_numbers(num1=input1, num2=input2) # ステップ 2: print_result コンポーネントを実行 # 前のステップ (add_task) の出力を、次のステップの入力として渡す print_task = print_result(result_value=add_task.output)
パイプライン テンプレート
Kubeflow Pipelines SDK で定義されたパイプラインは、パイプライン テンプレートとして Artifact Registry リポジトリにアップロードすることができます。
アップロードしたテンプレートは複数のユーザー、パイプラインが再利用することができます。
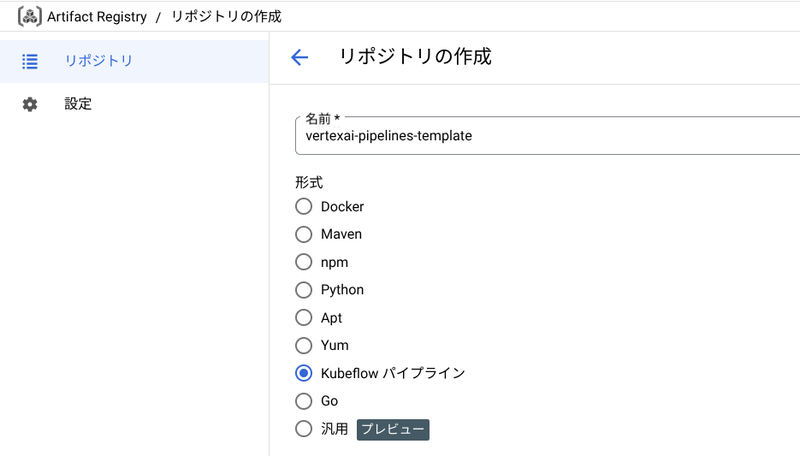
以下のコードでは、Google Cloud パイプライン コンポーネントの例で作成した YAML ファイルを、パイプライン テンプレートとしてアップロードしています。
from kfp.registry import RegistryClient # テンプレートのアップロード先リポジトリの指定 client = RegistryClient(host=f"https://asia-northeast1-kfp.pkg.dev/myproject/vertexai-pipelines-template") # テンプレートのアップロード templateName, versionName = client.upload_pipeline( file_name="image_classif_pipeline.yaml", tags=["v1", "latest"], extra_headers={"description":"This is an example pipeline template."})
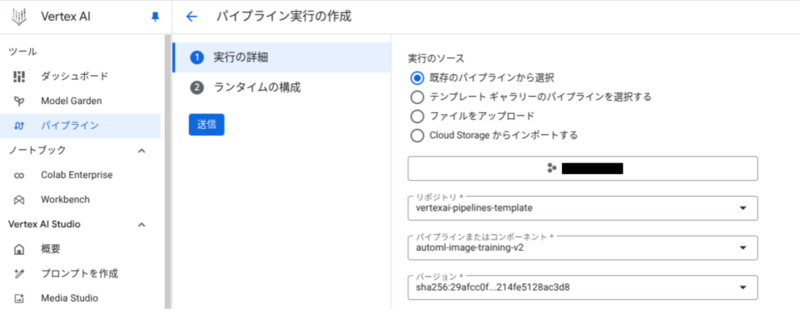
リポジトリにアップロードしたテンプレートは、パイプラインの実行時に指定することができます。
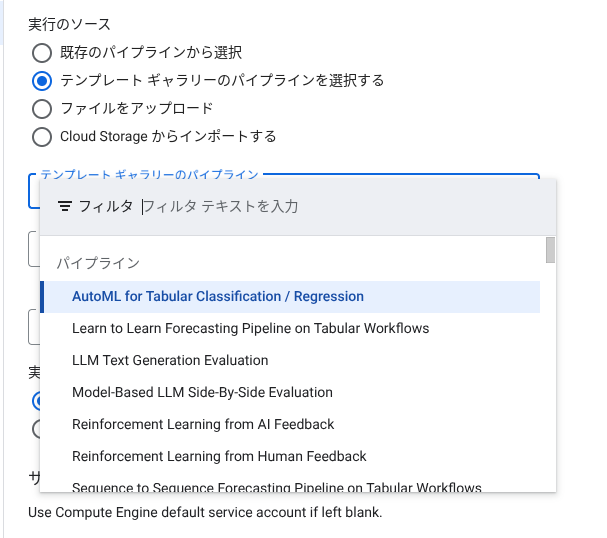
また、テンプレート ギャラリーには Google が作成したパイプライン テンプレートが用意されており、一般的なユースケースのパイプラインをそのまま実行したり、独自のパイプラインに組み込んで利用したりできます。
- 参考 : Create, upload, and use a pipeline template
- 参考 : Use a prebuilt template from the Template Gallery
パイプラインの実行
手動実行
パイプラインは Vertex AI SDK for Python や Google Cloud コンソールを使用して実行することができます。
以下のコードは、Google Cloud パイプライン コンポーネントの例で作成したパイプラインを、Jupyter Notebook から実行しています。
import google.cloud.aiplatform as aip aip.init( project="myproject", location="asia-northeast1", ) # 実行するパイプラインの設定 job = aip.PipelineJob( display_name="automl-image-training-v2", template_path="image_classif_pipeline.yaml", # コンパイルした YAML ファイル pipeline_root=pipeline_root_path, parameter_values={ 'project_id': project_id } ) # パイプラインの実行 job.submit()
パイプラインの実行は Google Cloud コンソールからモニタリングすることができます。
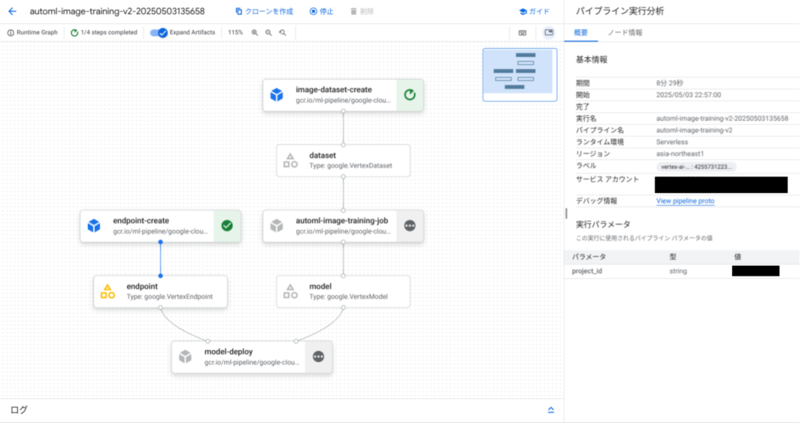
scheduler API によるスケジュール実行
scheduler API を使用することで、ML パイプラインの実行をスケジューリングすることができます。
これにより、モデルの再トレーニングを定期的に実行し、ドリフトによるモデルの品質低下などの問題に対処することができます。
パイプラインのスケジュール実行は、 Vertex AI SDK for Python や Google Cloud コンソールを使用して設定できます。
モデルの品質低下をトリガーとした実行
Vertex AI Model Monitoring を使用すると、Vertex AI Endpoints 等で運用中のモデルに対してモニタリングを行うことができます。
モニタリングの例として、予測の際に入力された特徴データや、予測の結果をベースラインのデータ分布と比較し、分布の変化(ドリフト)があった場合にアラート通知を行うことができます。
分布の変化が閾値を超えた場合、Cloud Logging にログとして出力されます。これを Pub/Sub、Cloud Run Functions に連携することで、ドリフトによるモデルの品質低下をトリガーとしたパイプラインの実行を実現することができます。
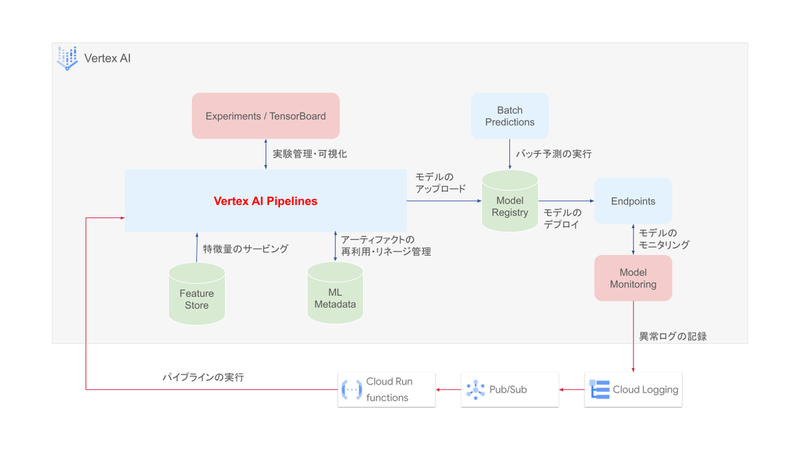
その他 Vertex AI ツールとの連携
Vertex AI で提供されている各種ツールは、Vertex AI Pipelines と連携し、ML パイプラインを中心とする MLOps の実現に役立てることができます。
Vertex AI の各ツールが Vertex AI Pipelines とどのように連携されるかを以下に示します。
| ツール | 説明 |
|---|---|
| Vertex AI Feature Store | ML モデルのトレーニングや予測で使用する特徴データを一元管理するツール。 BigQuery をデータソースとする特徴データを ML パイプラインやデプロイ済みのモデルに対して効率的にサービングすることができる。 |
| Vertex ML Metadata | ML パイプラインで入力されたパラメータや出力されたアーティファクト、指標などを記録することができる。 パイプラインの実行ごとの分析や、アーティファクトのリネージの追跡のほか、記録されたパラメータを使用してパイプラインを再実行したい場合などに使用できる。 |
| Vertex AI Experiments | ML モデル開発における実験プロセスを追跡・比較するための実験管理のためのツール。 試行錯誤的に実行される ML パイプラインを追跡・記録することで、最適なモデルを作り出すパイプラインを特定するための分析を行うことができる。 |
| Vertex AI TensorBoard | 実験プロセスで記録された各指標を可視化するためのツール。 ML モデルのトレーニング時に記録される損失や精度などの評価指標や、モデルの重み、バイアスなどパラメータの変化をリアルタイムに可視化することができる。 |
| Vertex AI Model Registry | ML パイプラインで構築したモデルをバージョン管理するリポジトリとして使用する。 リポジトリで管理されているモデルはバッチ予測に直接使用したり、Vertex AI Endpoints にデプロイしたりできる。 |
| Vertex AI Batch Predictions | トレーニング済みのモデルを使用して、非同期のバッチ予測を実行することができる。 |
| Vertex AI Endpoints | モデルをエンドポイントにデプロイし、オンライン(リアルタイム)予測を実行できるようにする。 エンドポイントはパイプラインから直接作成することができる。 |
| Vertex AI Model Monitoring | 運用中のモデルに対するモニタリングを実行するツール。モデルのトレーニング時のデータ分布をベースラインとし、入力されたデータの分布や予測結果の分布が異なるドリフトを検出できる。 Cloud Logging、Pub/Sub と連携することでモデルの品質低下のアラートを発行することができる。 |
料金
料金の基本
Vertex AI Pipelines では、メインの課金要素として、各コンポーネントから使用するリソースの使用量に応じた料金が発生します。また、ML パイプラインの実行ごとに $0.03 の実行料金が発生します。
例えば、パイプラインのコンポーネントとして AutoML のトレーニングを実行した場合は AutoML の料金が発生します。Vertex AI 以外のサービスでも、BigQuery や Dataflow のジョブをコンポーネントから実行した場合は、ジョブ実行に伴う料金が発生します。
このように、パイプラインの実行に伴う料金は Vertex AI 以外の複数のサービスに対して発生する可能性があり、Cloud Billing からパイプライン全体の料金を把握するのが若干難しいことに注意が必要です。
- 参考 : Vertex AI pricing
billing ID を使用したコスト分析
Vertex AI Pipelines は、パイプライン実行時に一意の billing ID を生成します。この ID をコンポーネントから使用される Google Cloud リソースのラベルとして紐づけることができます。
ラベルが付与されたリソースの利用料金は、Cloud Billing の課金レポートでフィルタして確認することができます。
また、Cloud Billing から請求情報を BigQuery にエクスポートし、billing ID を使用してクエリを実行することで、パイプライン実行ごとの料金を確認することができます。
ラベルは、Google Cloud パイプライン コンポーネントから作成されたリソース(Dataflow リソースを除く)に対して自動で付与されます。Dataflow リソースや、カスタムコンポーネントから作成されたリソースに対しては、ラベルを紐づけるための記述をコンポーネント定義に含める必要があります。
佐々木 駿太 (記事一覧)
G-gen 最北端、北海道在住のクラウドソリューション部エンジニア
2022年6月に G-gen にジョイン。Google Cloud Partner Top Engineer に選出(2024 / 2025 Fellow / 2026)。好きな Google Cloud プロダクトは Cloud Run。
趣味はコーヒー、小説(SF、ミステリ)、カラオケなど。
Follow @sasashun0805