



G-gen 又吉です。今回は Eventarcトリガーを利用して、Cloud Storage のファイルメタデータを BigQuery へ格納してみました。
概要
作成するもの
今回のアーキテクチャは以下のとおりです。

- ローカルから Cloud Strage にファイルをアップロード
- 1 を検知してEventarc トリガーが Cloud Functions を呼び出す
- Cloud Storage から受け取ったメタデータを BigQuery へ追加
Eventarcとは?
Eventarc とは、サーバーレスかつ標準化されたイベント配信により、Google Cloud を用いた イベントドリブンアーキテクチャ の構築が容易になるプロダクトです。
以下の記事で、 Eventarc の概要について説明しています。
Cloud Strage の準備
Cloud Storage トリガーとは
Cloud Storage トリガーを使用することで、Cloud Strorage にファイルのアップロードや更新、削除などのイベントをトリガーして Cloud Functions (第一世代) を呼び出すことができます。
Cloud Functions (第二世代) から、Cloud Storage トリガーは Eventarc トリガーの一部として実装されます。
今回は、Cloud Functions (第二世代) で実装していきたいと思います。
Cloud Storage サービス アカウントへの権限付与
Cloud Storage トリガー を実行するには、Cloud Storage サービス アカウントに Pub/Sub パブリッシャー(roles/pubsub.publisher)を含むロールが必要です。(参考)
以下に、Cloud Strage サービスエージェントへの権限付与手順を説明します。
- コンソールで、
Cloud Storage>バケット>設定へ移動 - [Cloud Storage サービス アカウント] のメールアドレスをコピー
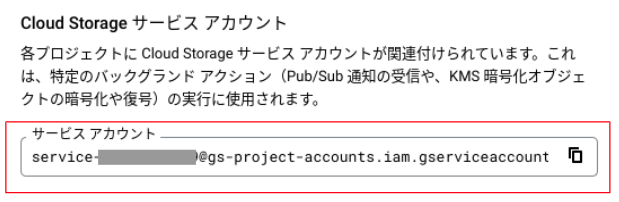
- コンソールで、
IAMと管理>IAMへ移動し、[追加]をクリック - [$Cloud Storage サービス アカウント]に対し、[Pub/Sub パブリッシャー]ロールを追加

ファイルアップロード用のバケットの作成
- コンソールで、
Cloud Storage>バケットへ移動し、[作成] をクリック - 任意のバケット名を入力
- ロケーションタイプに[Region]を選択し、[asia-northeast1(東京)]を選択
- その他はデフォルトのまま、[作成]をクリック
 上記のように、作成したバケットが表示されてればOKです。
上記のように、作成したバケットが表示されてればOKです。
BigQuery のテーブル作成
Cloud APIs を用いて、Google Cloud 上のリソースを API 経由で操作できます。
今回は、その中でも BigQuery API 使用して、Cloud Functions からBigQuery 上のテーブルにデータをINSERTしていきます。
BigQuery API でデータセットとテーブルの作成もできてしまいますが、今回は事前にスキーマを定義した空のテーブル作成までコンソールで行いたいと思います。
以下に、BigQuery テーブル作成手順を説明します。
- コンソールで、
BigQuery>SQLワークスペースへ移動 - ご自身のプロジェクトの[︙]から、[データセットを作成]をクリック
- [データセットID]と[データロケーション]を選択し、[データセットを作成]をクリック
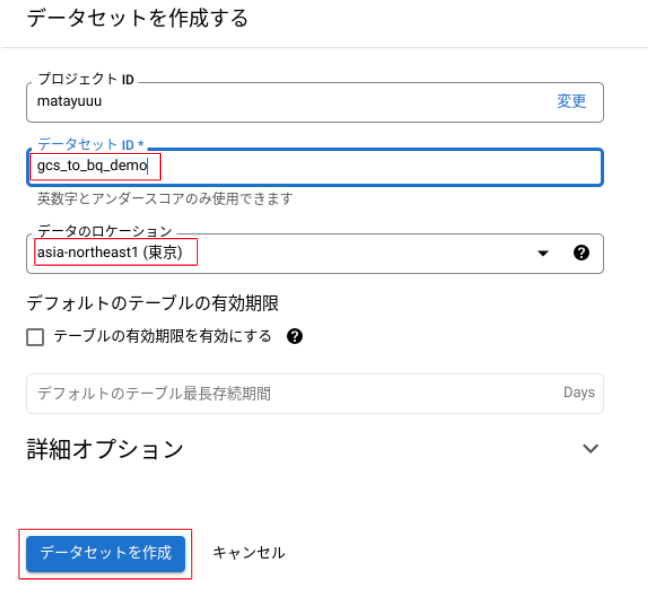
- 3 で作成したデータセットの[︙]から、[デーブルを作成]をクリック
- テーブル名とスキーマを入力したら[デーブルを作成]をクリック

Cloud Functions の作成
Eventarc トリガーから呼び出される Cloud Functions を作成します。
Cloud Functions の作成
以下に、Cloud Functions の作成手順を説明します。
- コンソールで、
Cloud Functionsへ移動し、[関数の作成] をクリック - [環境]は[第2世代]を選択し、[関数名]と[リージョン]を入力
- [EVENTARC トリガーを追加]を選択し、[イベントプロバイダ]、[イベント]、[バケット]、[サービスアカウント]を入力し[トリガーを保存]をクリック
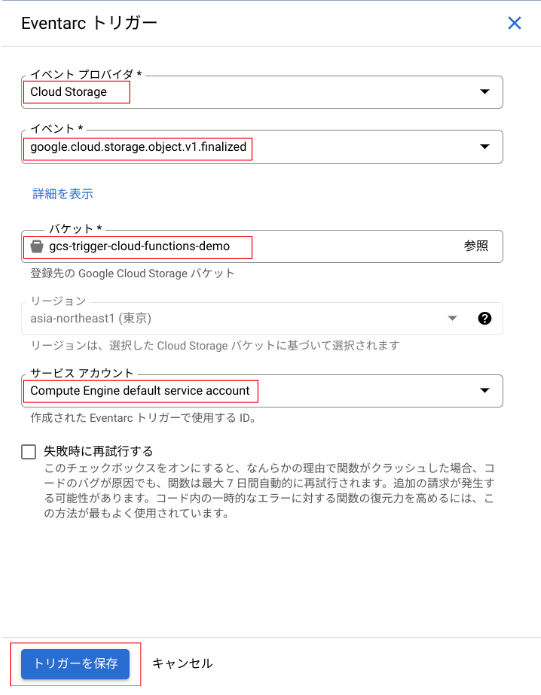
- [ランタイム環境変数]を設定
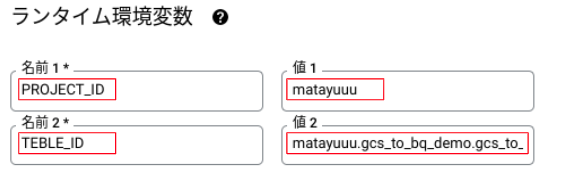
- [次へ]をクリック
- [ランタイム]に[Python 3.9]を選択し、[エントリポイント]はデフォルトのまま、main.py とrerequirements.txt のファイルをそれぞれ以下のコードに書き換え、[デプロイ]をクリック
main.py の内容
BigQuery にデータを格納するため BigQuery API と、関数実行時に任意のログ出力を実装するためCloud Logging API を使用しています。
import os import logging import google.cloud.logging import functions_framework from google.cloud import bigquery # ランタイム環境変数から[PROJECT_ID]と[TEBLE_ID]を取得 PROJECT_ID = os.environ.get('PROJECT_ID') TEBLE_ID = os.environ.get('TEBLE_ID') # Cloud Logging クライアントのインスタンス化 client = google.cloud.logging.Client() client.setup_logging() logger = logging.getLogger() logger.setLevel(logging.DEBUG) # エントリポイントに [ hello_gcs ] を設定 @functions_framework.cloud_event def hello_gcs(cloud_event): # cloud_event の[ID]と[TYPE]を取得 event_id = cloud_event["id"] event_type = cloud_event["type"] # cloud_event からファイルのメタデータを取得 data = cloud_event.data content_type = data["contentType"] bucket_name = data["bucket"] file_name = data["name"] created_date = data["timeCreated"].split('.')[0] # DATETIME型に合わせるため形成 updated_date = data["updated"].split('.')[0] # DATETIME型に合わせるため形成 # gcs_fanalized_list に cloud_event の[ID]と[TYPE]、各メタデータを格納 gcs_fanalized_list = [event_id, event_type, content_type, bucket_name, file_name, created_date, updated_date] insert_bq(gcs_fanalized_list) # BigQuery のデーブルにデータをINSERTする関数 def insert_bq(gcs_fanalized_list): # BigQuery クライアントのインスタンス化 client = bigquery.Client(project=PROJECT_ID) table = client.get_table(TEBLE_ID) # 行情報をリスト型で、さらに列情報を辞書型で記述 rows_to_insert = [ { "event_id": gcs_fanalized_list[0], \ "event_type": gcs_fanalized_list[1], \ "content_type": gcs_fanalized_list[2], \ "bucket_name": gcs_fanalized_list[3], \ "file_name": gcs_fanalized_list[4], \ "created_date": gcs_fanalized_list[5], \ "updated_date": gcs_fanalized_list[6] } ] # 1行 7列 # client.insert_rows() の戻り値は、INSERTエラーがあればエラー情報を、INSERTエラーがなければ何もなし errors = client.insert_rows(table, rows_to_insert) if errors == []: # エラーがない場合はログに[success]と表示させる logger.debug("success") else: # エラーがある場合はエラー内容を表示させる logger.debug(errors)
requirements.txt の内容
コード内で使用するライブラリを記載します。
functions-framework==3.* google-cloud-logging==3.2.2 google-cloud-bigquery==3.3.2
今回 Eventarc トリガーのイベントとして[google.cloud.storage.object.v1.finalized]を選択しました。こちらは、新しいオブジェクトが作成されるか、既存のオブジェクトが上書きされ、そのオブジェクトの新しい世代が作成されるとイベントが実行されます。
他にもいくつかのイベントタイプがサポートされています。
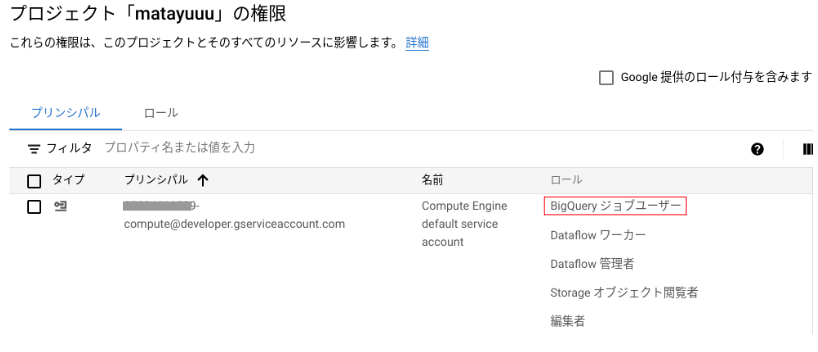
Cloud Functions サービスアカウントへの権限付与
合わせて、Cloud Functions から BigQuery にジョブが実行できるようCloud Functions サービスアカウントにBigQuery ジョブユーザー(roles/bigquery.jobUser)権限を付与していきます。
- コンソールで、
IAMと管理>IAMへ移動し、[追加]をクリック - [$Cloud Functions のサービスアカウント]に対し、[BigQuery ジョブユーザー]ロールを追加
筆者は今回、Cloud Functions のデフォルトのサービスアカウント(Compute Engine default service account)に権限を付与しました。
動作確認
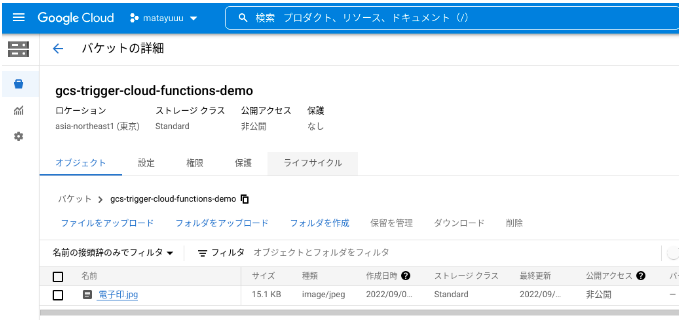
Cloud Storage にファイルをアップロードして、BigQuery のテーブルにファイルのメタデータが挿入されるか確認します。
ローカルにある「電子印.jpg」というファイルを、先程作成したバケットにアップロードしました。
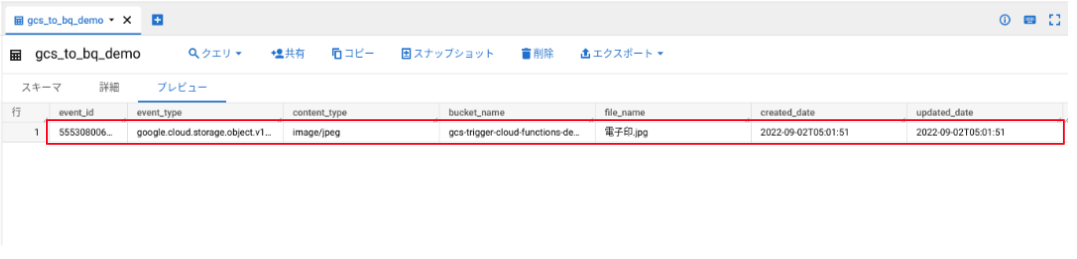
 BigQuery 上のテーブルを確認すると、1行目にデータが追加されていることを確認できました。
BigQuery 上のテーブルを確認すると、1行目にデータが追加されていることを確認できました。
Cloud Logging でログを確認してみると、テーブルへのINSERTが成功した時に出力する[success]が記載されてました。

また、複数のファイルを同時にアップロードした場合の挙動も確認するため、3つのファイルを同時に Cloud Storage にアップロードしました。
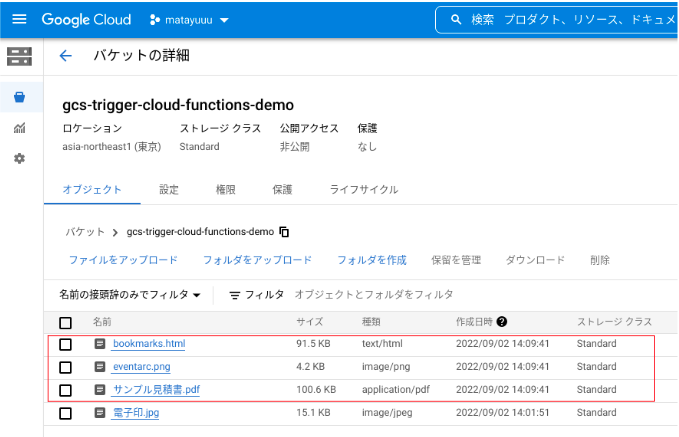
BigQuery 上のテーブルを確認すると、2-4行目に新しいデータが追加されていることを確認できました。
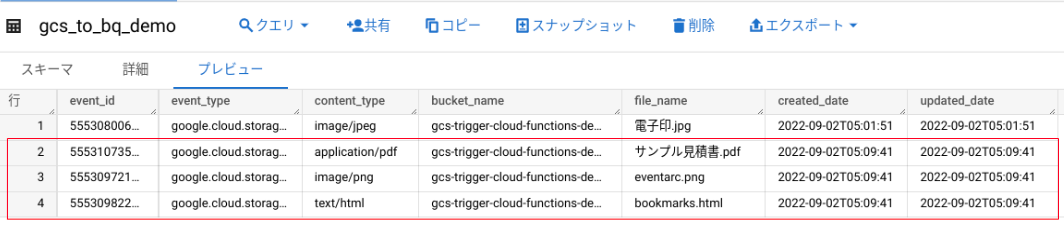
こちらもログを確認してみると、同じく、テーブルへのINSERTが成功したことが確認できます。
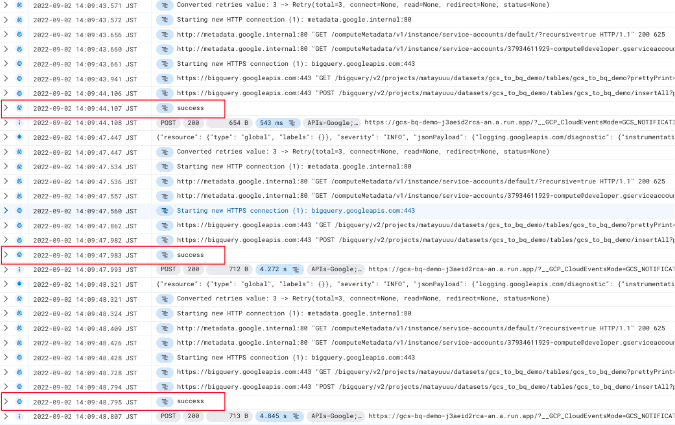
ファイルを同時にアップロードした場合でも、1ファイル 1 関数 が実行されていたことがわかります。
Cloud Functions は関数の呼び出し回数でも課金が発生するため (毎月最初の200万回は無料) 、ファイル数が大きく増える際には Eventarc トリガーを使わず別のアーキテクチャを検討するのも良いかもしれません。
Eventarc トリガーを用いることで、Cloud Storageのイベントを検知して Cloud Functions を実行できたり、また Cloud SDK により Cloud APIs をコールすることで BigQuery と Cloud Logging を操作できました。
今後も積極的に Eventarc × Cloud APIs でイベントドリブンアーキテクチャを試していきたいです。
又吉 佑樹(記事一覧)
クラウドソリューション部
はいさい、沖縄出身のクラウドエンジニア!
セールスからエンジニアへ転身。Google Cloud 全 11 資格保有。Google Cloud Champion Innovator (AI/ML)。Google Cloud Partner Top Engineer 2024。Google Cloud 公式ユーザー会 Jagu'e'r でエバンジェリストとして活動中。好きな分野は AI/ML。
Follow @matayuuuu