


G-gen の佐々木です。当記事では、Google Cloud(旧称 GCP)のマネージド ETL サービスである Dataflow を解説します。

概要
Dataflow とは
Dataflow は Google Cloud のインフラストラクチャ上でマネージドな Apache Beam 実行環境を提供するサービスです。Java や Python の SDK でパイプラインを記述することで、データをバッチ処理やストリーミング処理することができます。
Dataflow では Apache Beam SDK を使用してデータ処理のパイプライン(データの読み込みから変換、書き込みまでの一連の処理)をコードで記述します。それを Dataflow ジョブ として Google Cloud にデプロイするだけで、処理内容に応じて必要なぶんのコンピューティングリソースが自動でプロビジョニングされます。
したがって、ユーザーはパイプラインを実行するためのインフラストラクチャをほとんど意識することなく、パイプラインの設計のみに集中することができます。
- 参考 : Dataflow の概要
Apache Beam とは
Apache Beam はバッチ処理、ストリーミング処理の両方を定義することができるオープンソースのプログラミングモデル で、大規模なデータ分散処理パイプラインを単純化して定義することができます。
- 参考 : Apache Beam
Apache Beam では、パイプラインの実行時に ランナー (Runner) として実行環境を指定します。Dataflow は Apache Beam パイプラインの実行環境「Dataflow ランナー」として動作するためのサービス であり、Apache Beam パイプライン自体は Google Cloud 以外の環境 (Dataflow ランナー以外のランナー) でも実行することができます。

ユースケース
Dataflow のユースケース
Apache Beam ではバッチ処理とストリーミング処理の双方が利用できるため、Dataflow のユースケースは多岐にわたります。
単純なデータのバッチ/ストリーミング変換処理だけではなく、Vertex AI 上の機械学習モデルにデータをストリーミングすることで、リアルタイムの予測分析や異常検知を行うこともできます。
- 参考 : Dataflow - ユースケース
例1 : リアルタイムのデータ取り込み
Dataflow では典型的なユースケースとして、メッセージングサービスである Pub/Sub と組み合わせたリアルタイムのデータ取り込み処理があります。
以下の図は、Pub/Sub と Dataflow を使用した クリックストリーム 分析の例です。
アプリケーション上でのエンドユーザーのアクションを Pub/Sub に送信し、Dataflow でデータのチェックや集計などを行ったあと、各種データストアに書き込みます。
Pub/Sub ではバックエンドに対する 最低 1回(at-least-once)の配信が保証されており、データの再配信が行われる場合があるため、データ重複が発生する可能性があります。Dataflow は Pub/Sub からデータを受け取るとき、Pub/Sub のメッセージに含まれるメッセージ ID を使用してデータの重複削除を行います。

- 参考 : Pub/Sub を使用したストリーミング
例2 : データストア間のデータ移行
Dataflow では、各種データベースから BigQuery や Cloud Spanner などにデータを移行するためのテンプレートが提供されており、数クリックでデータ移行パイプラインを構築することができます。

また、Datastream を Dataflow のデータソースとして使用することで、データベースの変更を検知し、それをリアルタイムで BigQuery などのデータストアに同期することができます。

開発
SDK
Apache Beam では、以下の言語の SDK が提供されています。
インストール手順等は以下の Google Cloud 公式ドキュメントをご参照ください。
パイプライン構成
Apache Beam のパイプラインは以下のような要素から構成されます。
| 要素名 | 説明 |
|---|---|
| Pipeline | Apache Beam によるデータ変換処理の開始から終了、つまり入力データの読み取りから変換、出力データの書き込みまでの一連の処理をカプセル化した概念です。 |
| PCollection | パイプラインで使用されるデータセットを抽象化するオブジェクトであり、パイプラインの各ステップにおける入力、出力となります。 |
| PTransform | 実際のデータ変換処理を表します。1 つ以上の PCollection を入力とし、その各要素に対して処理を実行した後、1 つ以上の PCollection を出力します。 |
| I/O transforms | Apache Beam の I/O コネクタ を使用して、外部ソースからパイプラインへのデータ読み込み、パイプラインから外部シンクへのデータの書き込みを行います。様々なデータ形式を読み書きすることができ、必要に応じて カスタムの I/O コネクタ を開発して使用することもできます。 |

上記の基本的な構成要素の詳細、およびその他の構成要素については以下のドキュメントを参照してください。
- 参考 1:Apache Beam Programming Guide(Apache Beam ドキュメント)
- 参考 2:Apache Beam のプログラミング モデル(Google Cloud ドキュメント)
Python SDK で記述したパイプラインの例
パイプラインの例として、Python 用の Apache Beam SDK で記述したシンプルな例を以下に示します。
この例では、3 人の人物の名前、年齢、身長を入力データとし、年齢と身長の平均をそれぞれ算出して出力するパイプラインが記述されています。
import logging import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions # Dataflow ランナーで実行するためのパラメータ pipeline_args = [ #'--runner=DirectRunner' # ローカルで実行する場合 # Dataflow ランナーで実行(以下は Dataflow 用のパラメータ) '--runner=DataflowRunner', '--project=myproject', '--region=asia-northeast1', '--subnetwork=regions/asia-northeast1/subnetworks/mysubnet', '--temp_location=gs://mybucket/tmp/' ] def run(): # パイプラインの作成 with beam.Pipeline( options=PipelineOptions(pipeline_args) ) as pipeline: # PCollection を作成 inputdata = ( pipeline | 'Create' >> beam.Create([ {'name': 'Ichiro', 'age': 32, 'height': 172}, {'name': 'Jiro', 'age': 27, 'height': 168}, {'name': 'Saburo', 'age': 25, 'height': 179} ]) ) # 平均年齢を算出する mean_age = ( inputdata | 'Extract age' >> beam.Map(lambda x: x['age']) | 'Get mean age' >> beam.combiners.Mean.Globally() | 'Get KeyValue age' >> beam.Map(lambda x: ('mean age', x)) ) # 平均身長を算出する mean_height = ( inputdata | 'Extract height' >> beam.Map(lambda x: x['height']) | 'Get mean height' >> beam.combiners.Mean.Globally() | 'Get KeyValue height' >> beam.Map(lambda x: ('mean height', x)) ) # 平均年齢と平均身長を出力する outputdata = ( (mean_age, mean_height) | 'Flatten data' >> beam.Flatten() | 'Output' >> beam.Map(lambda x: logging.info(f'{x[0]} = {x[1]}')) ) if __name__ == '__main__': run()
このコードを実行すると Dataflow ジョブが作成され、ワーカーとなる Compute Engine VM が起動した後、パイプラインに記述された処理がそれぞれ ステップ として実行されます。一度限りのバッチジョブのため、処理が完了すると VM は削除されます。
このように、コンソールや CLI で直接 Dataflow ジョブを作成して実行するのではなく、Dataflow ランナーを実行環境として指定したコードを実行 するとジョブが作成されます。
以下の図は Dataflow のコンソールから確認することができるジョブのグラフです。

コンソールからステップごとのログを確認できます。
「Output」ステップで平均年齢と平均身長をログ出力するように記述していたため、以下のログが確認できます。

Dataflow テンプレート
Dataflow では、ユーザーが Apache Beam SDK で記述したパイプラインを Dataflow ジョブとしてただ実行するだけでなく、テンプレートとしてパッケージ化することができます。
テンプレートは Google Cloud コンソールや CLI、REST API を使用して Dataflow ジョブとしてデプロイします。
- 参考 : Dataflow テンプレート
テンプレートを使用することで、パイプライン開発とデプロイのプロセスが分離され、権限を持つユーザーであれば開発者が用意したパイプラインを必要なときにデプロイすることができるほか、テンプレート利用者がテンプレート側に設定されたパラメータを渡して実行することができます。
たとえば、テンプレート利用者が任意の入力ファイルやデータ出力先を指定してからパイプラインを実行できるようにテンプレートを作成できます。


Dataflow のテンプレートには以下の 3種類があります。
| テンプレートの種類 | 説明 |
|---|---|
| Google 提供のテンプレート | ユーザーがパイプラインを開発する代わりに、一般的なシナリオ用に事前定義されたテンプレートを使用できます(Google 提供のテンプレート一覧)。 |
| クラシックテンプレート | ユーザーが開発したパイプラインを Cloud Storage にステージングして Dataflow から利用します。 |
| Flex テンプレート | 開発したパイプラインを Docker イメージとしてパッケージ化し、Container Registry/Artifact Registry に格納します。 クラシックテンプレートと比較して処理内容を柔軟に変更することができ、入力パラメータに基づいて動的に I/O コネクタを選択したり、パイプライン作成中に入力パラメータの検証などの前処理を行ったりできます。 |
構成要素
Dataflow ワーカー
Dataflow ジョブは、パイプラインのデプロイ時にプロビジョニングされる Compute Engine VM インスタンスで実行されます。この VM を Dataflow ワーカー と呼びます。ワーカー上ではコンテナ化された Apache Beam SDK プロセスが起動されます。
ワーカー VM に使用されるマシンタイプや、起動するワーカーの台数などはデプロイ時に パイプラインオプション で指定することができます。
- 参考 : Dataflow ワーカー
リージョンエンドポイント
ジョブごとに リージョンエンドポイント (Regional endpoints) を指定します。ジョブの作成時にリージョンを指定すると、そのリージョンのエンドポイント経由で Dataflow ジョブのメタデータが保存されたり、自動スケーリング等の Dataflow ワーカーの動作もこのリージョンから制御されます。
リージョンエンドポイントを作成するリージョンは Dataflow ワーカーを作成するリージョンと別にすることができますが、コンプライアンス上の理由から特定リージョン内にデータを閉じたい場合や、リージョン間のネットワークレイテンシによるパフォーマンス影響を抑えるには、ワーカーと同一リージョンを指定することが推奨されます。

- 参考 : リージョン エンドポイント
Dataflow GPU
Dataflow ワーカーは GPU を使用することができます。GPU を使うと、特定の計算や画像処理、機械学習タスクを CPU よりも高速に実行することができます。
GPU は、後述する Dataflow Runner v2 を使用するパイプラインでのみサポートされています。
カスタムコンテナ
デフォルトの設定では、Dataflow ワーカーは Apache Beam イメージ を使用するコンテナを起動して処理を実行します。
カスタムコンテナを使用することで実行環境をカスタマイズし、起動時間を短縮したり、外部ライブラリなどの依存関係をプリインストールしたりできます。
GPU 同様、カスタムコンテナも Dataflow Runner v2 を使用するパイプラインでのみサポートされています。
周辺機能
Dataflow SQL
Dataflow SQL は、SQL を Apache Beam パイプラインに変換して Dataflow ジョブとして実行できる仕組みです。
Dataflow SQL のクエリは Dataflow コンソールの SQL ワークスペース や gcloud コマンドなどから作成し、そのままパイプラインへの変換、実行を行うことができます。
- 参考 : Dataflow SQL を使用する
例として、公式ドキュメント のサンプルを実行してみます。
以下のコマンドでは、一般公開されている Pub/Sub トピック taxirides-realtime から 1分ごとにデータを pull し、1 分間のタクシーの乗客数を計算して BigQuery テーブルに書き込む Dataflow ジョブが作成されます。
$ gcloud dataflow sql query \ --job-name=dataflow-sql-quickstart \ --region=asia-northeast1 \ --subnetwork=regions/asia-northeast1/subnetworks/mysubnet \ --bigquery-dataset=taxirides \ --bigquery-table=passengers_per_minute \ 'SELECT TUMBLE_START("INTERVAL 60 SECOND") as period_start, SUM(passenger_count) AS pickup_count, FROM pubsub.topic.`pubsub-public-data`.`taxirides-realtime` WHERE ride_status = "pickup" GROUP BY TUMBLE(event_timestamp, "INTERVAL 60 SECOND")'
コマンドを実行すると Dataflow ジョブが作成され、処理が開始されます。

BigQuery のテーブルを確認すると、1分ごとのタクシー乗客数のデータが記録されています。このサンプルのジョブはストリーミング処理のため、ジョブを停止するまで動作し続けます。実際に試す場合はジョブの止め忘れに気をつけましょう。

Dataflow Prime
Dataflow Prime は「Dataflow のサーバーレス版」とも言うべき仕組みです。サーバーレスなプラットフォーム上で Apache Beam パイプラインを実行することができます。
Dataflow Prime ではワーカーのリソース最適化に役立つ機能が提供されており、たとえば先述の水平自動スケーリングに加え、垂直方向の自動スケーリング を利用することができます。Dataflow ワーカーで使用可能なメモリは、パイプライン実行時に必要に応じて自動で調整され、メモリ不足エラー(OOM)によるジョブの失敗を防止し、パイプラインのリソース効率を最適化することができます。
- 参考 : Dataflow Prime を使用する
Dataflow ML
Dataflow ML では Dataflow ジョブ内で機械学習 (AI/ML) モデルによる推論を実行することができます。
Apache Beam の RunInference API を使用して機械学習モデルをパイプラインに追加することでこれを実現します。以下は、Pub/Sub で受信したデータを Dataflow のパイプライン内で処理し、機械学習モデルに送信して推論を行わせたあと、その結果を BigQuery に書き込むストリーミング処理の例です。

- 参考 : Dataflow ML について
ノートブックでの開発
Dataflow ではパイプラインの開発、実行、解析を JupyterLab ノートブック上でインタラクティブに行うことができます。
Apache Beam ノートブックは Vertex AI Workbench ユーザー管理ノートブック として提供されており、JupyterLab ノートブックと Apache Beam インタラクティブランナー がプリインストールされています。
パイプライン最適化の仕組み
Dataflow Runner v2
Dataflow Runner v2 は Dataflow ランナー (Apache Beam 実行環境) の新しいバージョンで、今後 Dataflow に実装される新機能は Dataflow Runner v2 でのみ使用することができます。
従来のランナーを使用することもできますが、Dataflow Runner v2 は高パフォーマンス、低コストで利用できる傾向があるため、基本的にはこちらを使用すると良いでしょう。SDK によっては Dataflow Runner v2 で使用できない機能があるなど、いくつかの 制限事項 があります。
自動スケーリング
水平自動スケーリング
Dataflow ジョブで水平自動スケーリングを有効化することで、ワーカー VM をジョブの実行に必要な数だけ自動的にスケールアウト/スケールインするようにできます。
また、ストリーミング処理を実行するワーカーは、ジョブの実行中に手動でスケーリングすることも可能です。
- 参考 : 水平自動スケジューリング
動的スレッドスケーリング
Dataflow では、パイプラインの実行時に複数のワーカーに処理を分散します。ワーカーは複数のスレッドを起動してタスクを並列実行します。
動的スレッドスケーリング (Dynamic Thread Scaling) を有効化すると、Dataflow は各ワーカーのリソース使用率に基づき、ワーカーで実行するスレッドの数を自動的に最適化します。
スレッド数の自動スケーリングはワーカーごとに行われ、ワーカーのメモリ使用率が 50% 未満かつ CPU 使用率が 65% 未満の場合はスレッド数を増やし、ワーカーのメモリ使用率が 70% を超えた場合にスレッド数を減らします。
動的作業再調整
動的作業再調整 (Dynamic work rebalancing) 機能を使用すると、Dataflow はワーカーごとのタスク割り当ての不均衡や、終了に時間がかかるタスクが割り当たっているワーカー、タスクが早期に終了するワーカーを自動的に検出し、余裕のあるワーカーに対して動的にタスクを割り当てることでジョブ全体の処理時間を短縮します。

- 参考 : 動的作業再調整
Dataflow Shuffle / Streaming Engine
Dataflow Shuffle と Streaming Engine は、それぞれ Dataflow ワーカー間のデータ移動(シャッフル)処理をワーカー外にオフロードする機能です。バッチ処理では Dataflow Shuffle、ストリーミング処理では Streaming Engine と呼ばれます。
パイプラインの中で GroupByKey のようなデータのグループ化処理を行う場合、特定のキーを持つすべてのデータを 1 つのワーカーに集める必要があります。この場合、それぞれのワーカー同士がメッシュ状にデータの移動が行うため、ワーカーの負荷や通信のオーバーヘッドが発生します。また、特定のワーカーで障害が発生した場合にデータが失われてしまい、ジョブ全体が失敗してしまう可能性があります。
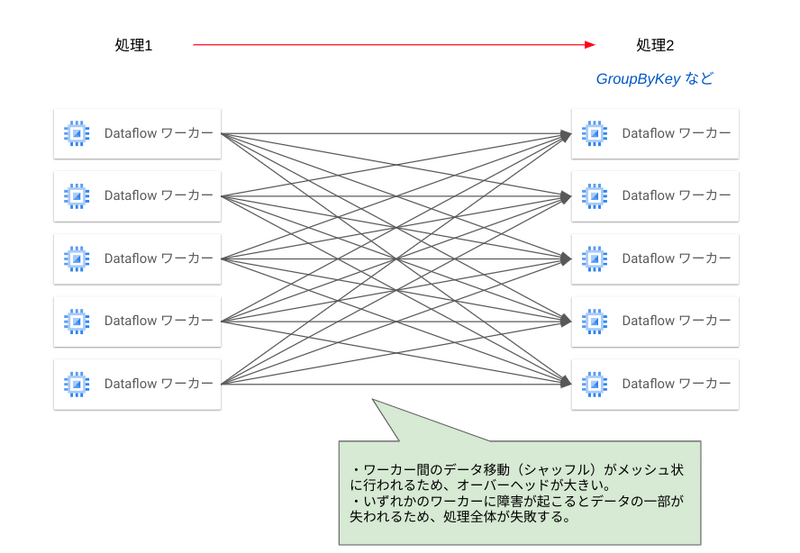
Dataflow Shuffle および Streaming Engine では、処理の中間状態をワーカー外に保存し、次の処理ではここからデータを読み出します。
これにより、ワーカー間でメッシュ状の通信を行うことなくデータの移動を行うことができます。そして特定のワーカーで障害が発生した場合でも、正常なワーカーが中間に保存されているデータを再度読み出すことでジョブを続行できます。

Flexible Resource Scheduling(FlexRS)
Flexible Resource Scheduling (FlexRS) は「遅延したスケジューリング」と「プリエンプティブル VM インスタンス」の活用により バッチ処理のコストを削減する機能 です。FlexRS を使用するジョブは FlexRS ジョブ といいます。
Flex ワーカー(FlexRS で使用される Dataflow ワーカー)として、プリエンプティブル VM と通常の VM の組み合わせが使用され、通常の Dataflow ワーカーよりもリソース使用料が安く設定されています。
FlexRS ジョブではリソース使用量が安い代わりに「遅延したスケジューリング」により、ジョブの作成後すぐに実行されず、Google Cloud が所有するリソースに余裕があるタイミングで実行されます(作成から 6時間以内には実行される)。したがって、時間の制約が厳しくないジョブを実行する際に有効な機能となります。
FlexRS ジョブは開始される前に 早期検証 が行われ、Dataflow ジョブの実行パラメータ、IAM ロール、ネットワーク構成などの設定が事前に検証され、潜在的なエラーがあれば報告されます。
FlexRS を使用するには Dataflow Shuffle が有効化されている必要があります。
モニタリング
Dataflow モニタリングインターフェースは、ウェブベースのパフォーマンスモニタリング用の画面です。Google Cloud コンソールから閲覧できます。
Dataflow モニタリングインターフェースでは以下のような項目が表示されます。
- 現在実行中のジョブを含む、過去 30日間に実行された Dataflow ジョブのリスト
- 各パイプラインの図(ジョブグラフ)
- 自動スケーリング、スループット、リソース使用率などの指標(参考)
- ジョブ実行中に発生したエラーや警告
- ジョブのパフォーマンス向上、コスト削減などに関する推奨事項
詳細は以下のドキュメントもご参照ください。
セキュリティ
データの暗号化
Dataflow では、データパイプライン全体で処理中のデータ、保存されるデータの両方に対して、デフォルトで暗号化が行われています。デフォルトの暗号化は Google が管理する暗号鍵によって行われます。
また、Google 管理の暗号鍵の代わりに Cloud Key Management Service(KMS)による顧客管理の暗号鍵(CMEK)や Cloud HSM を使用することもできます。
- 参考 : 顧客管理の暗号鍵を使用する
プライベート IP アドレスの使用
Dataflow では ワーカー VM のパブリック IP を無効にし、すべてのネットワーク通信にプライベート IP アドレスを使用するように指定することができます。パブリック IP を無効化する場合、ワーカーがリージョンエンドポイントにアクセスするために、ワーカー VM が使用するサブネットで 限定公開の Google アクセス を有効化する必要があります。
- 参考 : 外部 IP アドレスをオフにする
ネットワークタグの使用
通常の Compute Engine VM 同様に、Dataflow ワーカー VM にはネットワークタグを付与し、ファイアウォールルールでトラフィックの制限を行うことができます。
Dataflow ジョブで Dataflow Shuffle または Streaming Engine を使用しない場合(シャッフル処理を VM 外にオフロードしない場合)、VM 間でデータのやり取りを行うために Dataflow 用のファイアウォールルール で TCP ポート 12345 と 12346 の通信を許可する必要があります。
料金
Dataflow の最新の料金については以下のドキュメントを参照してください。
- 参考:Dataflow の料金
Dataflow の料金
Dataflow の料金はジョブごとに秒単位で発生します。 Dataflow ワーカー VM のリソース料金を基本として、GPU、Dataflow Shuffle を使用する場合に追加で料金が発生します。
東京リージョン(asia-northeast1)で利用する場合の料金は以下のようになります。
| ジョブの種類 | vCPU(1 vCPU、1 時間あたり) | メモリ(1 GB、1時間あたり) | シャッフル時に処理されたデータ(GB 単位) ※Dataflow Shuffle、Streaming Engine 使用時 |
|---|---|---|---|
| バッチ | $0.0728 | $0.0046241 | $0.0143 |
| FlexRS | $0.0437 | $0.0027745 | $0.0143 |
| ストリーミング | $0.0897 | $0.0046241 | $0.0234 |
バッチ処理で Dataflow Shuffle を使用する場合、上記の シャッフル時に処理されたデータ の料金はデータ量に応じて割引されます。シャッフル処理されたデータの最初の 250 GB までは 75%、次の 4,870 GB~5,120 GB は 50%、シャッフル時の処理料金が割引されます。5,120 GB 以降は上記の表の料金がそのまま適用されます。
例として、合計 10,240 GB(10 TB)のデータをシャッフル処理した場合、課金対象のデータ量は 7,617.5 GB(= 250 GB × 25% + 4,870 GB × 50% + 5,120 GB)となります。
ワーカー VM が使用するストレージ、GPU の料金は以下のようになっており、ジョブの種類ごとの違いはありません。
| ストレージ - 標準永続ディスク(1 GB 1時間あたり) | ストレージ - SSD 永続ディスク(1 GB 1時間あたり) | NVIDIA® Tesla® K80 GPU(1 GPU 1 時間あたり) | NVIDIA® Tesla® P100 GPU(1 GPU 1 時間あたり) | NVIDIA® Tesla® V100 GPU(1 GPU 1 時間あたり) | NVIDIA® Tesla® T4 GPU(1 GPU 1 時間あたり) | NVIDIA® Tesla® P4 GPU(1 GPU 1 時間あたり) |
|---|---|---|---|---|---|---|
| $0.0000702 | $0.0003874 | 東京リージョンで使用不可 | 東京リージョンで使用不可 | 東京リージョンで使用不可 | $0.4440 | 東京リージョンで使用不可 |
Dataflow Prime の料金
Dataflow Prime は課金単位が異なり、Dataflow Processing Unit(DPU) という概念によって料金が決定されます。ジョブのリソース使用状況から DPU 使用量が測定され、リソース消費量に比例して DPU 使用量が多くなります。
1 DPU は 「1 vCPU、メモリ 4 GB、250 GB の永続ディスク を使用するワーカー VM が 1時間処理を行った場合に使用されるリソース」に相当します。
Dataflow Prime を東京リージョン(asia-northeast1)で使用する場合の料金は以下のようになります。
| ジョブの種類 | 1 DPU、1 時間あたりの料金 |
|---|---|
| バッチ | $0.091 |
| ストリーミング | $0.105 |
Dataflow Prime では使用する DPU 数を直接指定することができないため、コスト節約にはメモリ消費量の削減、シャッフルの際に処理されるデータ量の削減などをパイプラインの実装時に工夫する必要があります。先述した Dataflow モニタリングインターフェースはこれらの最適化に役立つ情報を提供してくれます。
佐々木 駿太 (記事一覧)
クラウドソリューション部 クラウドエンジニアリング1課
北海道在住
大学院まで社会心理学を専攻し、AI に興味を持ち IT 業界へ。2022年6月に G-gen にジョイン。Google Cloud Partner Top Engineer に選出(2024 / 2025 Fellow / 2026)。好きな Google Cloud プロダクトは Cloud Run。
趣味はコーヒー、小説(SF、ミステリ)、カラオケなど。最近は法律の勉強にも目覚め、2級知的財産管理技能士を取得。
Follow @sasashun0805