


G-gen の佐々木です。当記事では、Gemini Pro に長文のリクエストを送信した際に発生することがある ResponseValidationError について解説します。

当記事で使用する環境
当記事では、以下の記事で作成した Gradio の UI を使用するチャットボットの画面を用いて説明を進めます。
このチャットボットは、ユーザーが入力した文章を加工せずに Gemini Pro の API に送信し、レスポンスをそのまま UI 上に表示するものとなっているため、Gemini Pro が入出力するメッセージの内容は Google Cloud コンソールや CLI などで Gemini Pro を利用する場合と同じものになります。
また当記事では、モデルは Gemini 1.5 Pro を使用しています。
事象
チャットボットに長文メッセージを処理させるため、先ほど引用した記事 の本文をすべて英訳するようにリクエストを送信します。
リクエスト送信後、チャット欄には以下のようなメッセージがレスポンスとして表示されます。これはあらかじめボットに設定しておいたエラーメッセージであり、ResponseValidationError が返ってきたときに表示するようにしてあります。

エラーログを確認すると、以下のように、実際に ResponseValidationError が発生していることがわかります。
ResponseValidationError: The model response did not completed successfully. Finish reason: 2. Finish message: . Safety ratings: [category: HARM_CATEGORY_HATE_SPEECH probability: NEGLIGIBLE probability_score: 0.147210672 severity: HARM_SEVERITY_NEGLIGIBLE severity_score: 0.0915427357 , category: HARM_CATEGORY_DANGEROUS_CONTENT probability: NEGLIGIBLE probability_score: 0.100023173 severity: HARM_SEVERITY_NEGLIGIBLE severity_score: 0.187433839 , category: HARM_CATEGORY_HARASSMENT probability: NEGLIGIBLE probability_score: 0.236804441 severity: HARM_SEVERITY_NEGLIGIBLE severity_score: 0.0960960239 , category: HARM_CATEGORY_SEXUALLY_EXPLICIT probability: NEGLIGIBLE probability_score: 0.147182867 severity: HARM_SEVERITY_NEGLIGIBLE severity_score: 0.121138074 ]. To protect the integrity of the chat session, the request and response were not added to chat history. To skip the response validation, specify `model.start_chat(response_validation=False)`. Note that letting blocked or otherwise incomplete responses into chat history might lead to future interactions being blocked by the service.
原因と解決方法
原因
ここで発生した ResponseValidationError は、Gemini Pro からのレスポンスのトークン数が、 リクエストを送信するときに指定した maxOutputTokens パラメータの値を超過していることに起因します。
maxOutputTokens は、生成 AI モデルがレスポンスとして生成できるトークンの最大数です。1トークンは約4文字、100トークンは約60~80語とされています(参考)。
原因の詳細
当記事で例として使用しているチャットボットの解説記事では、Gemini モデルが不適切なコンテンツを生成し、それがブロックされたため ResponseValidationError が発生していました。
もちろん、今回送信したリクエストでも同様の原因でエラーが発生する可能性があります。しかし、以下に抜粋したエラーログを見てみると、レスポンスの内容が不適切なものである確率を評価する各 category の probability が、いずれも「NEGLIGIBLE」になっており、レスポンスの内容が問題ないと判断されていることがわかります(参考)。
Safety ratings: [category: HARM_CATEGORY_HATE_SPEECH probability: NEGLIGIBLE probability_score: 0.147210672 severity: HARM_SEVERITY_NEGLIGIBLE severity_score: 0.0915427357 , category: HARM_CATEGORY_DANGEROUS_CONTENT probability: NEGLIGIBLE probability_score: 0.100023173 severity: HARM_SEVERITY_NEGLIGIBLE severity_score: 0.187433839 , category: HARM_CATEGORY_HARASSMENT probability: NEGLIGIBLE probability_score: 0.236804441 severity: HARM_SEVERITY_NEGLIGIBLE severity_score: 0.0960960239 , category: HARM_CATEGORY_SEXUALLY_EXPLICIT probability: NEGLIGIBLE probability_score: 0.147182867 severity: HARM_SEVERITY_NEGLIGIBLE severity_score: 0.121138074 ].
クライアントライブラリの FinishReason クラス を確認すると、Finish reason の値によってエラーの原因が分類されているようです。
レスポンスに不適切な内容が含まれていた場合、Finish reason の値は 3(SAFETY (3))となります。
# クライアントライブラリから引用 class FinishReason(proto.Enum): r"""The reason why the model stopped generating tokens. If empty, the model has not stopped generating the tokens. Values: FINISH_REASON_UNSPECIFIED (0): The finish reason is unspecified. STOP (1): Natural stop point of the model or provided stop sequence. MAX_TOKENS (2): The maximum number of tokens as specified in the request was reached. SAFETY (3): The token generation was stopped as the response was flagged for safety reasons. NOTE: When streaming the Candidate.content will be empty if content filters blocked the output. RECITATION (4): The token generation was stopped as the response was flagged for unauthorized citations. OTHER (5): All other reasons that stopped the token generation BLOCKLIST (6): The token generation was stopped as the response was flagged for the terms which are included from the terminology blocklist. PROHIBITED_CONTENT (7): The token generation was stopped as the response was flagged for the prohibited contents. SPII (8): The token generation was stopped as the response was flagged for Sensitive Personally Identifiable Information (SPII) contents. """
今回のエラーメッセージの2行目を見てみると、Finish reason の値は 2(MAX_TOKENS (2))となっています。したがって、Gemini Pro が扱うことのできるトークン数に起因したエラーであることがわかります。
ResponseValidationError: The model response did not completed successfully.
Finish reason: 2.
解決方法
Gemini Pro に対してリクエストを送信する際に指定する maxOutputTokens パラメータの値を増加させることで、当該事象を解決できる可能性があります(参考)。
モデルごとに設定できる maxOutputTokens の値はドキュメントのモデル一覧を参照してください。今回使用している Gemini 1.5 Pro では 8,192 が最大値となっています。
当記事で使用しているチャットボットでは、いくつかのパラメータを動的に調整してリクエストを送信できるようにしてあるので、先ほどエラーが発生したリクエストと同じ内容を maxOutputTokens を 8,192 にしてから送信してみます。
リクエスト内容によっては maxOutputTokens が最大値であっても超過してしまう可能性があるため、これでもエラーが発生する可能性がありますが、今回は問題なくレスポンスとして記事の英訳が表示されました。
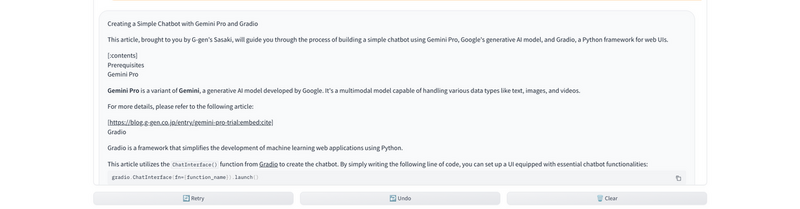
maxOutputTokens の最大値はモデル側で制限されているため、根本的な解決が難しくなっています。今回のような事象に対しては「リクエストの内容を変えてください」等のメッセージをチャットボットに表示するように例外処理を実装しておくのが無難な対処となるでしょう。
佐々木 駿太 (記事一覧)
G-gen 最北端、北海道在住のクラウドソリューション部エンジニア
2022年6月に G-gen にジョイン。Google Cloud Partner Top Engineer に選出(2024 / 2025 Fellow / 2026)。好きな Google Cloud プロダクトは Cloud Run。
趣味はコーヒー、小説(SF、ミステリ)、カラオケなど。
Follow @sasashun0805