


G-gen の佐々木です。当記事では Google が提供する生成 AI モデル Gemini Pro と、Web UI 用の Python フレームワークである Gradio を使用した、シンプルなチャットボットの作り方を紹介します。

前提知識
Gemini Pro
Gemini Pro は、Google が提供する生成 AI モデル Gemini のバリエーションの1つであり、テキストや画像、動画などの複数の種類のデータを扱うことができるマルチモーダルな生成 AI モデルです。
詳細については以下の記事をご一読ください。
Gradio
Gradio は、Python で機械学習 Web アプリを容易に構築できるフレームワークです。
当記事では、Gradio の ChatInterface() を使用してチャットボットを作成しています。コードに以下の一行を記述するだけで、チャットボットに必要な機能を備えた UI を用意することができます。
gradio.ChatInterface(fn={関数名}).launch()

この UI 上でメッセージを送信(Submit)すると、ChatInterface() に引数として渡した関数にメッセージを渡すことができます。この関数内にメッセージを処理するロジックを記述するだけで、UI を備えたチャットボットを簡単に開発することができます。
参考:How to Create a Chatbot with Gradio
Gradio を使用して Gemini Pro のチャットボットを開発する
Python のバージョン
当記事の内容は、Python 3.12.0 で試しています。
$ python --version Python 3.12.0
requirements.txt
使用する外部ライブラリは以下の通りです。
google-cloud-aiplatform==1.42.1 gradio==4.19.2
main.py
使用するコードの全文を以下に記載します。
PROJECT_ID の値は、使用する Google Cloud プロジェクトの IDに置き換えてください。
import gradio as gr import vertexai from vertexai.generative_models import GenerativeModel, Content, Part # 環境変数の設定 PROJECT_ID = "myproject" # Google Cloud プロジェクトの ID LOCATION = "asia-northeast1" # Gemini モデルを使用するリージョン # Vertex AI API の初期化 vertexai.init(project=PROJECT_ID, location=LOCATION) # Gemini モデルとのチャットを行う関数 def gemini_chat(message, history, temperature, top_p, top_k, max_output_token): # Gemini モデルの初期化 generation_config = { "temperature": temperature, # 生成するテキストのランダム性を制御 "top_p": top_p, # 生成に使用するトークンの累積確率を制御 "top_k": top_k, # 生成に使用するトップkトークンを制御 "max_output_tokens": max_output_token, # 最大出力トークン数を指定 } gemini_model = GenerativeModel( model_name="gemini-1.0-pro", generation_config=generation_config ) # 会話履歴のリストを初期化 gemini_history = [] # 会話履歴のフォーマットを整形 for row in history: input_from_user = row[0] output_from_gemini = row[1] gemini_history.append(Content(role="user", parts=[Part.from_text(input_from_user)])) gemini_history.append(Content(role="model", parts=[Part.from_text(output_from_gemini)])) # Gemini モデルに会話履歴をインプット chat = gemini_model.start_chat(history=gemini_history) # Gemini モデルにプロンプトリクエストを送信 try: response = chat.send_message(message).text except IndexError as e: print(f"IndexError: {e}") return "Gemini からレスポンスが返されませんでした。もう一度質問を送信するか、文章を変えてみてください。" return response # UI に Generation Config を調整するスライダーを追加するためのリスト additional_inputs = [ gr.Slider(label="Temperature", minimum=0, maximum=1, step=0.1, value=0.4, interactive=True), gr.Slider(label="Top-P", minimum=0.1, maximum=1, step=0.1, value=1, interactive=True), gr.Slider(label="Top-K", minimum=1, maximum=40, step=1, value=32, interactive=True), gr.Slider(label="Max Output Token", minimum=1, maximum=8192, step=1, value=1024, interactive=True), ] if __name__ == "__main__": # gemini_chat 関数を使用するチャットボットインターフェイスを起動 gr.ChatInterface( fn=gemini_chat, additional_inputs=additional_inputs ).launch()
コードの解説
Gradio の ChatInterface に渡す関数の形式について
コード末尾の ChatInterface(fn={関数名}).launch() で Gradio のチャットボットを起動しています。
if __name__ == "__main__": gr.ChatInterface( fn=gemini_chat, additional_inputs=additional_inputs # ここは後ほど解説 ).launch()
ChatInterface() の引数 fn に渡す関数は、ユーザーが送信したメッセージと過去の会話履歴を引数として受け取るように実装します(以下の第1、第2引数が該当)。
def gemini_chat(message, history, temperature, top_p, top_k, max_output_token):
ユーザーが送信したメッセージは message に格納されます。
history には過去の会話履歴がリストとして渡されます。例えばユーザーが送信したメッセージを user_input_N、モデルからのレスポンスを model_response_N とすると、以下のような形式で履歴が格納されます。
history = [
[user_input_1, model_response_1],
[user_input_2, model_response_2],
[user_input_3, model_response_3]
]
参考:How to Create a Chatbot with Gradio - Defining a chat function
generation_config について
Gemini 使用時にいくつかのパラメータを渡すことで、生成される回答の精度を調整することができます。パラメータの詳細についてはドキュメントをご一読ください。
generation_config = {
"temperature": temperature, # 生成するテキストのランダム性を制御
"top_p": top_p, # 生成に使用するトークンの累積確率を制御
"top_k": top_k, # 生成に使用するトップkトークンを制御
"max_output_tokens": max_output_token, # 最大出力トークン数を指定
}
当記事では、以下のようにしてチャットボットの UI 上にスライダーを配置し、メッセージ送信前に各種パラメータを手動で調整できるようにしています。
# UI に Generation Config を調整するスライダーを追加するためのリスト additional_inputs = [ gr.Slider(label="Temperature", minimum=0, maximum=1, step=0.1, value=0.4, interactive=True), gr.Slider(label="Top-P", minimum=0.1, maximum=1, step=0.1, value=1, interactive=True), gr.Slider(label="Top-K", minimum=1, maximum=40, step=1, value=32, interactive=True), gr.Slider(label="Max Output Token", minimum=1, maximum=8192, step=1, value=1024, interactive=True), ] if __name__ == "__main__": # gemini_chat 関数を使用するチャットボットインターフェイスを起動 gr.ChatInterface( fn=gemini_chat, additional_inputs=additional_inputs ).launch()
このように手動でパラメータの調整ができる機能をつける場合、メッセージ送信のたびにモデルの初期化を行う必要があります。レスポンスの速度などを気にする場合は、パラメータを固定化して Gemini モデルの初期化処理はグローバルスコープに記述します。
Gemini における会話履歴の形式について
Gemini を利用する場合、過去の会話履歴は Content オブジェクトとしてモデルに渡します。
チャットボットのユーザーが送信したメッセージは role="user"、Gemini からのレスポンスは role="model" として Content オブジェクトを作成します。
gemini_history.append(Content(role='user', parts=[Part.from_text(input_from_user)])) gemini_history.append(Content(role='model', parts=[Part.from_text(output_from_gemini)]))
Gemini モデルとのチャットを開始する際に Content オブジェクトのリストを渡すことで、過去の会話履歴を用いたやり取りを行うことができます。
chat = gemini_model.start_chat(history=gemini_history)
動作確認
ローカルでチャットボットを実行する
main.py を実行してローカルでチャットボットを起動します。
デフォルトではローカルホスト(127.0.0.1)のポート 7860 でチャットボットが起動されるため、ブラウザからアクセスします。
$ python main.py Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
Gradio では gradio コマンドを使用することで、ホットリロードを使用してチャットボットを実行することもできます。
$ gradio main.py
チャットボットを使用する
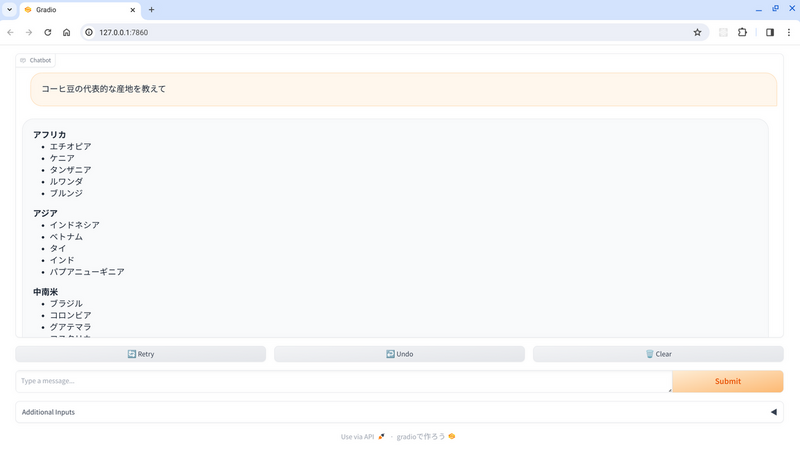
チャットボットの UI から適当なメッセージを送信してみます。
送信したメッセージの後に、Gemini Pro モデルからのレスポンスが表示されます。
チャットボットを外部に共有する
Gradio では期限付きの外部公開 URL を発行することもできます。
この機能は、launch() の引数に share=True を渡すことで利用できます。
gr.ChatInterface(
fn=gemini_chat,
additional_inputs=additional_inputs
).launch(share=True)
発行された public URL にアクセスすると、インターネットからローカルで実行しているチャットボットにアクセスすることができます。
$ python main.py Running on local URL: http://127.0.0.1:7860 Running on public URL: https://52b37dd2b7cf213999.gradio.live This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
Safety Attributes の調整
ResponseValidationError
作成したチャットボットとやり取りしていると、以下のようにエラーが発生してレスポンスが表示されない可能性があります。
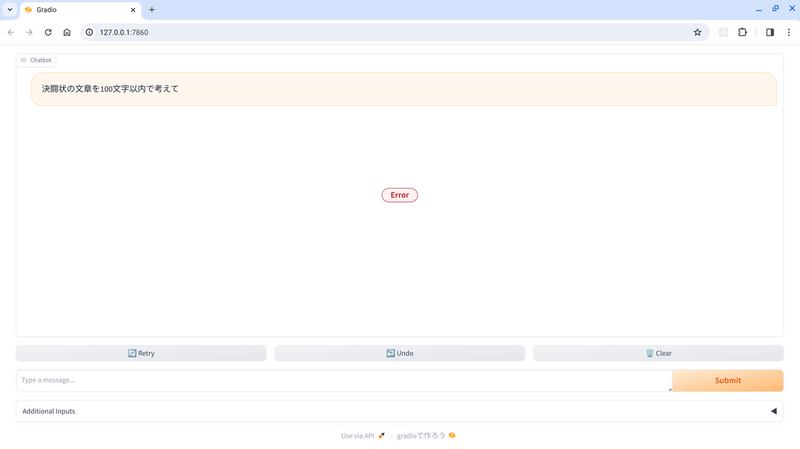
このスクリーンショットはエラーを再現するための極端なメッセージ例ですが、チャットボットと普通にしりとりをしているだけであっても同じエラーに遭遇する可能性があります。
チャットボットのログには以下のように ResponseValidationError が出力されています。
これは、Gemini からのレスポンスに対していくつかの基準(後述)で検証が行われた結果、不適切な内容が含まれている可能性があると判断され、レスポンスがブロックされたことを示しています。
vertexai.generative_models._generative_models.ResponseValidationError: The model response did not completed successfully. Finish reason: 3. Finish message: . Safety ratings: [category: HARM_CATEGORY_HATE_SPEECH probability: NEGLIGIBLE , category: HARM_CATEGORY_DANGEROUS_CONTENT probability: NEGLIGIBLE , category: HARM_CATEGORY_HARASSMENT probability: MEDIUM blocked: true , category: HARM_CATEGORY_SEXUALLY_EXPLICIT probability: NEGLIGIBLE ]. To protect the integrity of the chat session, the request and response were not added to chat history. To skip the response validation, specify `model.start_chat(response_validation=False)`. Note that letting blocked or otherwise incomplete responses into chat history might lead to future interactions being blocked by the service.
このエラーメッセージでは、HARM_CATEGORY_HARASSMENT というカテゴリで MEDIUM、つまり中程度に不適切な可能性があるレスポンスがあったことがわかります。
Safety Attributes とは
Safety Attributes とは、Gemini モデルが不適切なコンテンツを生成することを防ぐための評価カテゴリであり、このカテゴリに照らし合わせて不適切な可能性があると判断されたコンテンツは、ユーザーに返される前にブロックされます。
Safety Attributes には以下のようなカテゴリがあります。
| Safety Attributes のカテゴリ | 説明 |
|---|---|
| Hate Speech (HARM_CATEGORY_HATE_SPEECH) |
特定の属性に対するヘイトスピーチに関するもの。 |
| Harassment (HARM_CATEGORY_HARASSMENT) |
別の個人に対する嫌がらせに関するもの。 |
| Sexually Explicit (HARM_CATEGORY_SEXUALLY_EXPLICIT) |
露骨な性的表現に関するもの。 |
| Dangerous Content (HARM_CATEGORY_DANGEROUS_CONTENT) |
有害な商品、サービス、活動に関するもの。 |
Gemini API を使用する場合、API リクエストに Safety Settings としてブロックの閾値を設定することで、Safety Attributes のカテゴリごとにフィルターの強さを調整することができます。
何も設定していない場合は、デフォルトで BLOCK_MEDIUM_AND_ABOVE が設定されます。
| 閾値 | 説明 |
|---|---|
| BLOCK_NONE | レスポンスに対して Safety Attributes のフィルタを適用しない(常にレスポンスを表示する)。 |
| BLOCK_ONLY_HIGH | 不適切である可能性が高いレスポンスのみブロックする。 |
| BLOCK_MEDIUM_AND_ABOVE | デフォルトの閾値。不適切である可能性が中程度以上のレスポンスをブロックする。 |
| BLOCK_LOW_AND_ABOVE | 不適切である可能性が少程度であってもレスポンスをブロックする。 |
| HARM_BLOCK_THRESHOLD_UNSPECIFIED | デフォルトの閾値を使用する。 |
コードの修正
Gemini モデルに対して Safety Settings を含むリクエストを送信するようにコードを修正します。
まず、vertexai.generative_models からの import 文に HarmCategory、HarmBlockThreshold、ResponseValidationError を追記します。
from vertexai.generative_models import GenerativeModel, Content, Part, HarmCategory, HarmBlockThreshold, ResponseValidationError
Safety Attributes のカテゴリごとにフィルターの強さを設定します。当記事では一律 BLOCK_ONLY_HIGH に設定します。
ここで設定できるカテゴリの種類は先ほど説明した4つに加え、不特定カテゴリ(HARM_CATEGORY_UNSPECIFIED)が存在します。
# 緩めの Safety Settings
SAFETY_SETTINGS = {
HarmCategory.HARM_CATEGORY_UNSPECIFIED: HarmBlockThreshold.BLOCK_ONLY_HIGH,
HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH,
HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH,
HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH,
HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH,
}
send_message で Gemini にメッセージを送る際に、safety_settings 引数を渡すように修正します。
また、BLOCK_ONLY_HIGH にフィルターを緩めた後でも、不適切な可能性が高いと判定されたレスポンスは引き続きエラーが発生してしまうため、ResponseValidationError について例外処理を実装し、フィルタに引っかかってしまった場合のユーザーへのメッセージを返すようにします。
# Gemini モデルとのチャットを行う関数 def gemini_chat(message, history): 〜〜〜省略〜〜〜 # Gemini モデルにプロンプトリクエストを送信 try: response = chat.send_message( message, safety_settings=SAFETY_SETTINGS # 引数に Safety Attributes の設定を追加 ).text except ResponseValidationError as e: # フィルタに引っかかった場合のエラー処理 print(f"ResponseValidationError: {e}") return "Gemini から不適切なレスポンスが返されたため、メッセージを表示できません。もう一度質問を送信するか、文章を変えてみてください。" except IndexError as e: print(f"IndexError: {e}") return "Gemini からレスポンスが返されませんでした。もう一度質問を送信するか、文章を変えてみてください。" return response
修正後の main.py 全文
Safety Attributes の設定を加えたコードの全文を以下に記載します。
import gradio as gr import vertexai from vertexai.generative_models import GenerativeModel, Content, Part, HarmCategory, HarmBlockThreshold, ResponseValidationError # 環境変数の設定 PROJECT_ID = "myproject" # Google Cloud プロジェクトの ID LOCATION = "asia-northeast1" # Gemini モデルを使用するリージョン # 緩めの Safety Settings SAFETY_SETTINGS = { HarmCategory.HARM_CATEGORY_UNSPECIFIED: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_ONLY_HIGH, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_ONLY_HIGH, } # Vertex AI API の初期化 vertexai.init(project=PROJECT_ID, location=LOCATION) # Gemini モデルとのチャットを行う関数 def gemini_chat(message, history, temperature, top_p, top_k, max_output_token): # Gemini モデルの初期化 generation_config = { "temperature": temperature, # 生成するテキストのランダム性を制御 "top_p": top_p, # 生成に使用するトークンの累積確率を制御 "top_k": top_k, # 生成に使用するトップkトークンを制御 "max_output_tokens": max_output_token, # 最大出力トークン数を指定 } gemini_model = GenerativeModel( model_name="gemini-1.0-pro", generation_config=generation_config ) # 会話履歴のリストを初期化 gemini_history = [] # 会話履歴のフォーマットを整形 for row in history: input_from_user = row[0] output_from_gemini = row[1] gemini_history.append(Content(role="user", parts=[Part.from_text(input_from_user)])) gemini_history.append(Content(role="model", parts=[Part.from_text(output_from_gemini)])) # Gemini モデルに会話履歴をインプット chat = gemini_model.start_chat(history=gemini_history) # Gemini モデルにプロンプトリクエストを送信 try: response = chat.send_message( message, safety_settings=SAFETY_SETTINGS # 引数に safety attributes の設定を追加 ).text except ResponseValidationError as e: # フィルタに引っかかった場合のエラー処理 print(f"ResponseValidationError: {e}") return "Gemini から不適切なレスポンスが返されたため、メッセージを表示できません。もう一度質問を送信するか、文章を変えてみてください。" except IndexError as e: print(f"IndexError: {e}") return "Gemini からレスポンスが返されませんでした。もう一度質問を送信するか、文章を変えてみてください。" return response # UI に Generation Config を調整するスライダーを追加するためのリスト additional_inputs = [ gr.Slider(label="Temperature", minimum=0, maximum=1, step=0.1, value=0.4, interactive=True), gr.Slider(label="Top-P", minimum=0.1, maximum=1, step=0.1, value=1, interactive=True), gr.Slider(label="Top-K", minimum=1, maximum=40, step=1, value=32, interactive=True), gr.Slider(label="Max Output Token", minimum=1, maximum=8192, step=1, value=1024, interactive=True), ] if __name__ == "__main__": # gemini_chat 関数を使用するチャットボットインターフェイスを起動 gr.ChatInterface( fn=gemini_chat, additional_inputs=additional_inputs ).launch()
動作確認
エラーが発生したメッセージを再度送信してみると、正常なレスポンスが返ってきました。

また、より不適切な可能性が高いレスポンスにはフィルターが機能することも試してみます。例外処理に設定したエラーメッセージが返ってくることが確認できます。

エラーログを確認すると、HARM_CATEGORY_HARASSMENT カテゴリで HIGH、つまり高確率で不適切な内容のレスポンスがブロックされたことがわかります。
ResponseValidationError: The model response did not completed successfully. Finish reason: 3. Finish message: . Safety ratings: [category: HARM_CATEGORY_HATE_SPEECH probability: NEGLIGIBLE , category: HARM_CATEGORY_DANGEROUS_CONTENT probability: NEGLIGIBLE , category: HARM_CATEGORY_HARASSMENT probability: HIGH blocked: true , category: HARM_CATEGORY_SEXUALLY_EXPLICIT probability: NEGLIGIBLE ]. To protect the integrity of the chat session, the request and response were not added to chat history. To skip the response validation, specify `model.start_chat(response_validation=False)`. Note that letting blocked or otherwise incomplete responses into chat history might lead to future interactions being blocked by the service.
BLOCK_NONE に設定した場合の動作について
ブロックの閾値を BLOCK_NONE に設定した場合、つまりフィルターを無効化した場合であっても、有害になり得る質問へのレスポンスがそもそも生成されないケースもあります。


Google Cloud 上にチャットボットをデプロイする
Cloud Run を使用する
ここまでで作成したチャットボットを Google Cloud 上にデプロイしてみます。
当記事ではデプロイ先のサービスとして、サーバーレス コンテナ コンピューティングサービスである Cloud Run を使用します。
Cloud Run の詳細については以下の記事をご一読ください。
コードの修正
main.py 末尾の launch() の引数を、以下のように修正します。
if __name__ == "__main__": # gemini_chat 関数を使用するチャットボットインターフェイスを起動 gr.ChatInterface( fn=gemini_chat, additional_inputs=additional_inputs ).launch(server_name="0.0.0.0", server_port=8080)
Dockerfile の作成
Cloud Run へのデプロイには Docker イメージを用意する必要があるため、Docker Hub のサンプルを元に、簡単な Dockerfile を作成します。
FROM python:3.12-slim WORKDIR /usr/src/app COPY requirements.txt ./ RUN pip install --no-cache-dir -r requirements.txt COPY . . CMD [ "python", "./main.py" ]
Cloud Run にデプロイ
Dockerfile を作成したディレクトリで以下のコマンドを実行し、コンテナイメージのビルドと Cloud Run へのデプロイを同時に行います。
# Cloud Run サービスをデプロイ $ gcloud run deploy gradio-gemini --source . \ --region=asia-northeast1 \ --allow-unauthenticated
ビルドされたコンテナイメージは、指定したリージョンに自動で作成される「cloud-run-source-deploy」という名前の Artifact Registory リポジトリに格納されます。
動作確認
Cloud Run のデプロイが完了すると、Service URL として Cloud Run のエンドポイントが出力されているので、ブラウザからアクセスします。
# デプロイ完了後のコマンド出力例 $ gcloud run deploy gradio-gemini --source . \ --region=asia-northeast1 \ --allow-unauthenticated This command is equivalent to running `gcloud builds submit --pack image=[IMAGE] .` and `gcloud run deploy gradio-gemini --image [IMAGE]` Building using Buildpacks and deploying container to Cloud Run service [gradio-gemini] in project [myproject] region [asia-northeast1] ✓ Building and deploying new service... Done. ✓ Uploading sources... ✓ Building Container... Logs are available at [https://console.cloud.google.com/cloud-build/builds/d72a1c89-4e73-41ea-86b9-467976adfcb0?project=xxxxxxxxxxxx]. ✓ Creating Revision... ✓ Routing traffic... ✓ Setting IAM Policy... Done. Service [gradio-gemini] revision [gradio-gemini-00001-rkr] has been deployed and is serving 100 percent of traffic. Service URL: https://gradio-gemini-ai4xxxxxxx-an.a.run.app
Cloud Run 上のチャットボットにアクセスすることができました。
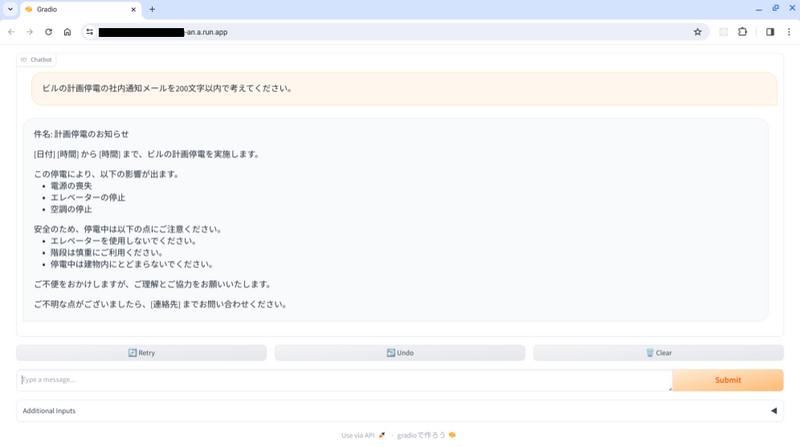
Cloud Run のアクセス元制御について
Cloud Run にデプロイしたチャットボットのアクセス元制御を行いたい場合、Cloud Run の前段にロードバランサーを配置し、Identity Aware Proxy(IAP)による IAM 認証や Cloud Armor による IP アドレスの制限を実装します。
詳細な手順については以下の記事を参照してください。
佐々木 駿太 (記事一覧)
G-gen最北端、北海道在住のクラウドソリューション部エンジニア
2022年6月にG-genにジョイン。Google Cloud Partner Top Engineer 2024に選出。好きなGoogle CloudプロダクトはCloud Run。
趣味はコーヒー、小説(SF、ミステリ)、カラオケなど。
Follow @sasashun0805