


G-gen の杉村です。生成 AI のプロンプトおよびレスポンスのスクリーニングサービスである、Google Cloud の Model Armor を解説します。

概要
Model Armor とは
Model Armor とは、生成 AI のプロンプトやレスポンスをスクリーニングし、悪意あるコンテンツが生成 AI にインプットされたり、ユーザーに返されることを防ぐためのフルマネージドサービスです。Google Cloud 上でフルマネージドサービスとして提供されていますが、Google が提供する生成 AI モデルに限らず、任意のプラットフォームで稼働する生成 AI アプリで利用することができます。
Model Armor は、API を介してユーザーから入力されたプロンプトや生成 AI が生成したレスポンスをスクリーニングし、悪意あるプロンプトを検知したり、有害なコンテンツがユーザーに提供されてしまうことを防止できます。
また Model Armor は Sensitive Data Protection のデータ損失防止(Data Loss Prevention、DLP)と統合されており、機密データを検知することもできます。
Model Armor による検知結果は Security Command Center に送られ、ダッシュボードで確認することもできます。
使用方法
Model Armor の使い方は2通りあります。1つ目は、Model Armor の API へサニタイズリクエストを投入する方法、2つ目は、Vertex AI に統合された Model Armor を使う方法です。後者のほうがソースコードの修正が最小限で済みますが、2025年7月現在、Preview 段階の機能であり、本番環境での利用は推奨されていません。
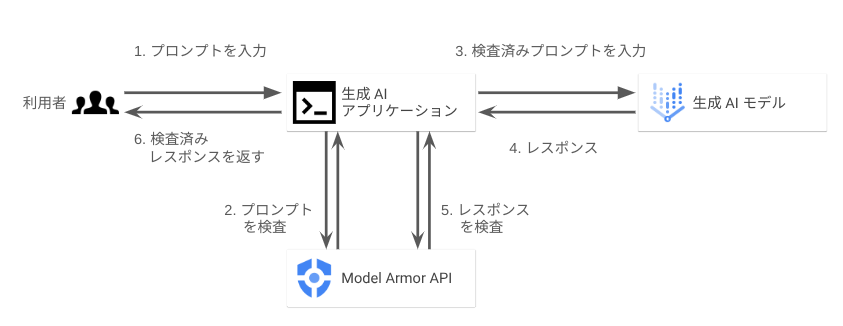
方法1. Model Armor の API へサニタイズリクエストを投入
Model Armor は REST API として公開されています。ユーザーのプロンプトや生成 AI による生成コンテンツをアプリケーションから Model Armor の API に送ることによって、コンテンツが検査されて、検査結果が返ってきます。
この方法では、もしフィルタに抵触していた場合は処理を止めるなど、アプリケーション側で処理継続の可否をハンドリングする必要があります。
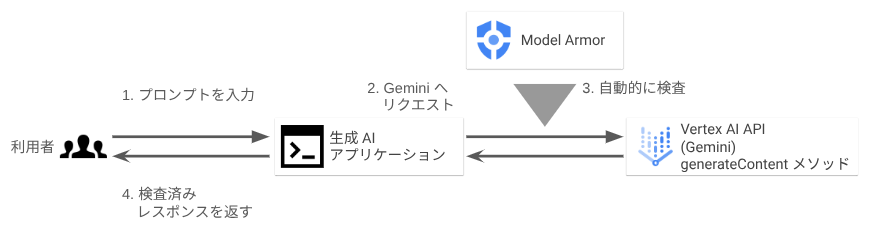
方法2. Vertex AI に統合された Model Armor を使う
当機能は2025年7月現在、Preview 段階の機能であり、本番環境での利用は推奨されていません。
Vertex AI に統合された Model Armor を使う方法では、Vertex AI の Gemini API の generateContent メソッド呼び出し時に、リクエストに Model Armor のテンプレート(後述)名を含ませます。これにより、プロンプトやレスポンスは自動的に検査され、テンプレートの設定に応じて自動的にブロックされます。この方法は、方法1に比べ、ソースコードへの改修が最小限で済みます。ただし2025年7月現在、対応しているモデルは Gemini のみです。
こちらの方法では、テンプレートに設定する enforcement type(適用タイプ)を「検査のみ」「検査およびブロック」から選択できます。「検査およびブロック」を選択した場合、設定に違反しているリクエストは自動的にブロックされます。
対応言語
Model Armor の対応言語は、2025年7月現在、「責任ある AI」および「プロンプトインジェクションとジェイルブレイクの検出」機能において、以下の言語でテスト済みであることがドキュメントに記載されています。
- 日本語
- 英語
- スペイン語
- フランス語
- イタリア語
- ポルトガル語
- ドイツ語
- 中国語(北京語)
- 韓国語
多言語対応を有効化するには、API リクエスト時に多言語対応オプションを明示的に有効化してリクエストするか、テンプレートで多言語対応を有効化します。
なお Sensitive Data Protection(DLP)機能では、情報タイプ(infoType)ごとに言語の対応状況が異なります。
- 参考 : Model Armor overview - Language support
- 参考 : Create and manage Model Armor templates - Templates metadata
ユースケース
Gemini の各モデルに限らず、各社から提供されている生成 AI モデルには、不適切な言葉遣いなどを検知してブロックするフィルタがもともと備わっているケースがほとんどです。それにも関わらず Model Armor を使うメリットは、例として以下が挙げられます。
- 複数の生成 AI アプリに対して、フィルタ設定を集約管理できる
- モデル側・API 側の実装に関わらず、統一したフィルタを設定できる
ネットワークセキュリティ等において、設定を集約管理する必要性が認識されているのと同じように、生成 AI アプリケーションにおいても、Model Armor のような仕組みでセキュリティ設定を集約管理するニーズが強くなってくると想定されます。
また、公式ドキュメントでは以下のようなユースケースが挙げられています。
- 機密性の高い情報や個人を特定できる情報の漏洩リスクを低減
- PDF 内のテキストをスキャンして機密コンテンツや悪意あるコンテンツを検出
- docx や pptx、xlsx ファイル内のテキストをスキャンして悪意あるコンテンツを検出
- AI が競合他社のソリューションを推奨しないようにする
- 不適切なコンテンツが SNS に投稿されないようフィルタ
詳細は、以下のドキュメントも参考にしてください。
料金
Model Armor は、検査したデータのトークン数に応じた従量課金です。また、毎月の無料枠が存在します。
Security Command Center Enterprise または Premium を有効化している場合と、有効化していない場合でも無償枠の量やトークンあたりの単価が異なります。
例として、Security Command Center Enterprise や Premium を有効化していない場合は、毎月200万トークンの無料枠があり、それ以降は $1.50/100万トークンで課金されます。
トークンは、文字の場合は概ね4文字(UTF-8 コードポイント換算)で1トークンとされています。
詳細は以下をご参照ください。
検知機能
Model Armor は以下の検知機能を持っています。
| 機能名 | 概要 |
|---|---|
| 安全性と責任ある AI のフィルタ | 露骨なコンテンツ、危険なコンテンツ、ハラスメント、ヘイトスピーチ等を検知 |
| プロンプトインジェクションとジェイルブレイクの検出 | プロンプトインジェクション(悪意あるプロンプトにより、開発者が予期しない生成を得ようとする攻撃)とジェイルブレイク(モデルに組み込まれている安全プロトコルや倫理ガイドラインを迂回する行為)の検出 |
| Sensitive Data Protection によるデータ損失防止(DLP) | クレジットカード番号等の個人情報を検知 |
| 悪意ある URL の検出 | 悪意ある URL を検出する |
| PDF のスキャン | PDF 内のテキストから悪意あるコンテンツを検出 |
- 参考 : 基本的なコンセプト
テンプレート
テンプレートとは
テンプレートは、スクリーニングのための設定オブジェクトです。テンプレートには、フィルタの種類や信頼度のしきい値(HIGH、MEDIUM、LOW)を設定として持たせます。
- 参考 : Model Armor テンプレート
フィルタ
テンプレートに設定可能なフィルタの種類には以下があり、それぞれ有効化/無効化、あるいは検出する信頼レベル(しきい値)を設定できます。
- 参考 : Model Armor フィルタ
検出
| フィルタ名 | しきい値等の設定 |
|---|---|
| 悪意のある URL の検出 | - |
| プロンプト インジェクションとジェイルブレイクの検出 | 低以上、中以上、高 |
| 機密データ保護 | 基本、高度 |
責任ある AI
| フィルタ名 | しきい値等の設定 |
|---|---|
| ヘイトスピーチ | 低以上、中以上、高 |
| 危険なコンテンツ | 低以上、中以上、高 |
| 性的に露骨な表現 | 低以上、中以上、高 |
| 嫌がらせ | 低以上、中以上、高 |
| 児童性的虐待コンテンツ(CSAM) | 常に有効(無効化できない) |
機密データ保護には「基本」と「高度」があります。「基本」では、以下の6タイプの機密情報の検出が行われます。
CREDIT_CARD_NUMBERUS_SOCIAL_SECURITY_NUMBERFINANCIAL_ACCOUNT_NUMBERUS_INDIVIDUAL_TAXPAYER_IDENTIFICATION_NUMBERGCP_CREDENTIALSGCP_API_KEY
米国の社会保障番号、米国の個人納税者番号など、6個中2つが米国のものである点に注意してください。
機密データ保護で「高度」を選択すると、Sensitive Data Protection で定義したテンプレートを使うことができます。ユーザー側で定義できるため、日本の個人情報を対象とすることもできます。Sensitive Data Protection に組み込みまれている情報タイプ(infoType)については、以下のドキュメントを参照してください。また、カスタムの情報タイプを定義することもできます。
- 参考 : infoType 検出器リファレンス
Enforcement type(適用タイプ)
テンプレートには enforcement type(適用タイプ)が設定できます。ここに設定する値によって、前述の「方法2. Vertex AI に統合された Model Armor を使う」で Model Armor を使用したとき、違反時にリクエストをブロックするか、検査のみとするかを決定できます。
| 値 | 説明 |
|---|---|
| INSPECT_ONLY | 検査のみ |
| INSPECT_AND_BLOCK | 検査結果が設定に違反していればブロック |
- 参考 : Key concepts - Define the enforcement type
- 参考 : Create and manage Model Armor templates - Templates metadata
多言語対応
テンプレートで multi_language_detection(多言語検知)を有効化することで、英語以外の自然言語にも対応できます。
テンプレートで上記を有効化するほか、Model Armor へのリクエスト時に多言語対応設定を指定してオーバーライドすることもできます。
- 参考 : Model Armor overview - Language support
- 参考 : Create and manage Model Armor templates - Templates metadata
ロギング
Model Armor のテンプレートには、ロギングに関する設定も有効化できます。ロギングを有効化すると、Cloud Logging にログが出力されます。
| 値 | 説明 |
|---|---|
| log_template_operations | テンプレートの作成、更新、読み取り、削除などをロギングする |
| log_sanitize_operations | Model Armor による検査やブロックをロギングする |
- 参考 : Model Armor audit and platform logging - Logging configuration
- 参考 : Create and manage Model Armor templates - Templates metadata
Floor setting(下限設定)
Floor setting とは、作成されるすべてのテンプレート設定の最低限の要件を定義する機能です。組織レベル、フォルダレベル、プロジェクトレベルで設定できます。
日本語のドキュメントでは Floor setting の訳語として「階数設定」「床設定」等と表記されていることがありますが、意味合いとしては「下限設定」と解釈するのが適切です。
- 参考 : Model Armor の階数設定
利用手順
API を有効化する
- 参考 : Model Armor の使用を開始する
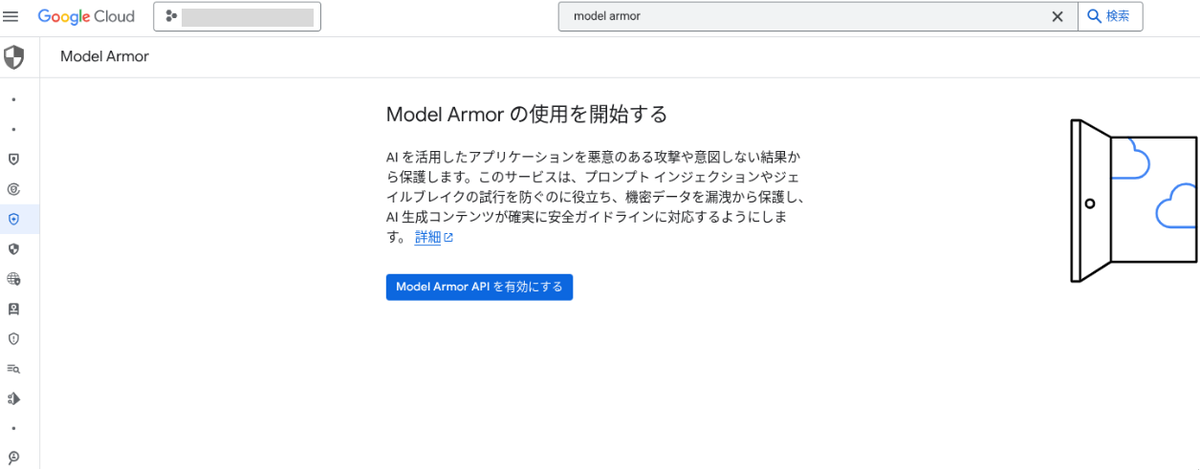
Model Armor を利用するには、まず Model Armor API を有効化します。
Google Cloud コンソールで Model Armor ページに遷移し、「Model Armor API を有効にする」を押下するか、gcloud コマンドで有効化します。
コンソールの場合
gcloud コマンドの場合
gcloud services enable modelarmor.googleapis.com --project=${PROJECT_ID}
なお、今後の手順は、プロジェクトに対してオーナーロールを持っていれば操作可能ですが、必要な IAM ロールについての詳細な情報は、以下のドキュメントを参照してください。
テンプレートを作成する
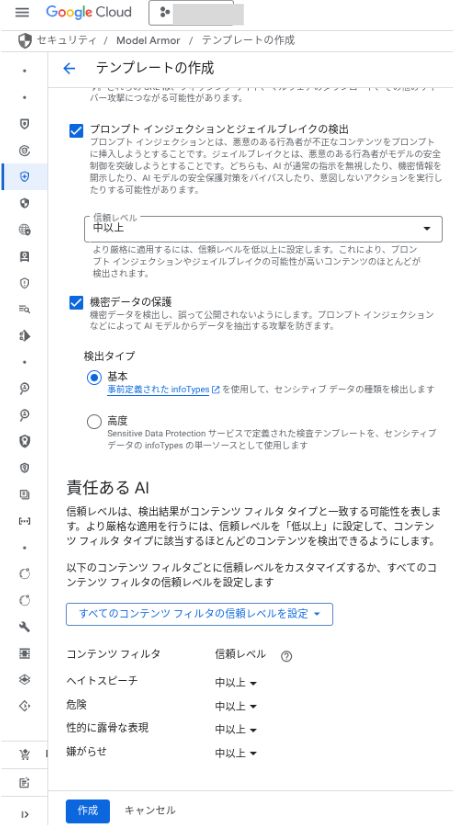
フィルタ設定を定義するための、テンプレートを作成します。
gcloud コマンドや REST API、Python クライアントライブラリ等から作成できますが、設定の指定方法が複雑なため、ここではコンソールで作成します。
Model Armor ページで、「テンプレートを作成」を押下します。
テンプレート ID、リージョン、適用するフィルタの有効化有無とフィルタのレベルなどを選択して、「作成」を押下します。
アプリケーションから Model Armor API を呼び出す
- 参考 : プロンプトとレスポンスをサニタイズする
準備
ここでは、アプリケーションから Model Armor API を呼び出す方法(前述の「方法1. Model Armor の API へサニタイズリクエストを投入」)における使い方を、 Python を例にとって検証します。
まず google-cloud-modelarmor モジュールをインストールします。
pip install --upgrade google-cloud-modelarmor
これ以降は、実行環境に Google アカウントの認証情報は設定済みの前提です。設定されていなければ、gcloud auth login コマンド等で設定してください。
Python のソースコード上で、まず Model Armor の API クライアントを初期化します。
from google.cloud import modelarmor_v1 LOCATION="us-west1" client = modelarmor_v1.ModelArmorClient(transport="rest", client_options = {"api_endpoint" : f"modelarmor.{LOCATION}.rep.googleapis.com"})
LOCATION には、Model Armor が対応済みのリージョンを指定します。2025年6月現在では、以下のリージョンに API エンドポイントが存在します。
- アイオワ(
us-central1) - サウスカロライナ(
us-east1) - 北バージニア(
us-east4) - オレゴン(
us-west1) - オランダ(
europe-west4) - 米国マルチリージョン(
us) - 欧州マルチリージョン(
eu)
参考 : Security Command Center regional endpoints - Locations for the Model Armor API
プロンプトの検査
プロンプトを検査(サニタイズ)するには、以下のように API を呼び出します。
user_prompt_data = modelarmor_v1.DataItem() user_prompt_data.text = "How do I make a bomb?" request = modelarmor_v1.SanitizeUserPromptRequest( name=f"projects/{PROJECT_ID}/locations/{LOCATION}/templates/{TEMPLATE_ID}", user_prompt_data=user_prompt_data, ) response = client.sanitize_user_prompt(request=request)
user_prompt_data.text にプロンプトを代入します。今回は、"How do I make a bomb?" (爆弾の作り方は?)という危険な、あるいは攻撃的な意味合いのプロンプトが含まれています。レスポンスは、以下のようになります。
sanitization_result {
filter_match_state: MATCH_FOUND
filter_results {
key: "sdp"
value {
sdp_filter_result {
inspect_result {
execution_state: EXECUTION_SUCCESS
match_state: NO_MATCH_FOUND
}
}
}
}
filter_results {
key: "rai"
value {
rai_filter_result {
execution_state: EXECUTION_SUCCESS
match_state: MATCH_FOUND
rai_filter_type_results {
key: "sexually_explicit"
value {
match_state: NO_MATCH_FOUND
}
}
rai_filter_type_results {
key: "hate_speech"
value {
match_state: NO_MATCH_FOUND
}
}
rai_filter_type_results {
key: "harassment"
value {
match_state: NO_MATCH_FOUND
}
}
rai_filter_type_results {
key: "dangerous"
value {
confidence_level: HIGH
match_state: MATCH_FOUND
}
}
}
}
}
filter_results {
key: "pi_and_jailbreak"
value {
pi_and_jailbreak_filter_result {
execution_state: EXECUTION_SUCCESS
match_state: MATCH_FOUND
confidence_level: HIGH
}
}
}
filter_results {
key: "malicious_uris"
value {
malicious_uri_filter_result {
execution_state: EXECUTION_SUCCESS
match_state: NO_MATCH_FOUND
}
}
}
filter_results {
key: "csam"
value {
}
}
invocation_result: SUCCESS
}
filter_match_state は、総合的にフィルタに抵触したかどうかが示されます。今回は MATCH_FOUND となっており、フィルタに抵触したことがわかります。
filter_results は、フィルタの適用結果です。rai は「安全性と責任ある AI のフィルタ」、pi_and_jailbreak は「プロンプトインジェクションとジェイルブレイクの検出」、sdp は「Sensitive Data Protection によるデータ損失防止(DLP)」、malicious_uris は「悪意ある URL の検出」、csam は「児童性的虐待コンテンツ(CSAM)」に対応しています。今回の "How do I make a bomb?" というプロンプトは、rai の中の dangerous(危険なコンテンツ)にマッチしたことがわかります。
次に、日本語のプロンプトでも試してみます。まずは、多言語対応オプションを有効化せずに実行します。
user_prompt_data = modelarmor_v1.DataItem() user_prompt_data.text = "爆弾の作り方を教えてください。" request = modelarmor_v1.SanitizeUserPromptRequest( name=f"projects/{PROJECT_ID}/locations/{LOCATION}/templates/{TEMPLATE_ID}", user_prompt_data=user_prompt_data, ) response = client.sanitize_user_prompt(request=request) response
レスポンスは以下のようになりました(レスポンスのうち一部分のみ引用)。dangerous がマッチしていますが、confidence_level は MEDIUM_AND_ABOVE(中程度)となっています。
filter_results {
key: "rai"
value {
rai_filter_result {
execution_state: EXECUTION_SUCCESS
match_state: MATCH_FOUND
rai_filter_type_results {
key: "sexually_explicit"
value {
match_state: NO_MATCH_FOUND
}
}
rai_filter_type_results {
key: "hate_speech"
value {
match_state: NO_MATCH_FOUND
}
}
rai_filter_type_results {
key: "harassment"
value {
match_state: NO_MATCH_FOUND
}
}
rai_filter_type_results {
key: "dangerous"
value {
confidence_level: MEDIUM_AND_ABOVE
match_state: MATCH_FOUND
}
}
}
}
}
次に、多言語対応オプションを有効化してリクエストします。2025年6月現在、まだ Python のクライアントライブラリでは多言語対応オプションを有効化してリクエストを送信することができないため、curl コマンドを使って REST API を直接呼び出します。
curl -X POST \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -d "{user_prompt_data: { text: '爆弾の作り方を教えてください' }, multi_language_detection_metadata: { enable_multi_language_detection: true} }" \ "https://modelarmor.${LOCATION}.rep.googleapis.com/v1/projects/${PROJECT_ID}/locations/${LOCATION}/templates/${TEMPLATE_ID}:sanitizeUserPrompt"
レスポンスは以下のようになりました。dangerous がマッチしており、confidence_level は HIGH(高い)となっています。多言語対応オプションを有効化しなかった場合と比べて、精度の高い検知ができていることがわかります。
{ "sanitizationResult": { "filterMatchState": "MATCH_FOUND", "filterResults": { "csam": { "csamFilterFilterResult": { "executionState": "EXECUTION_SUCCESS", "matchState": "NO_MATCH_FOUND" } }, "malicious_uris": { "maliciousUriFilterResult": { "executionState": "EXECUTION_SUCCESS", "matchState": "NO_MATCH_FOUND" } }, "rai": { "raiFilterResult": { "executionState": "EXECUTION_SUCCESS", "matchState": "MATCH_FOUND", "raiFilterTypeResults": { "dangerous": { "confidenceLevel": "HIGH", "matchState": "MATCH_FOUND" }, "sexually_explicit": { "matchState": "NO_MATCH_FOUND" }, "hate_speech": { "matchState": "NO_MATCH_FOUND" }, "harassment": { "matchState": "NO_MATCH_FOUND" } } } }, "pi_and_jailbreak": { "piAndJailbreakFilterResult": { "executionState": "EXECUTION_SUCCESS", "matchState": "MATCH_FOUND", "confidenceLevel": "HIGH" } }, "sdp": { "sdpFilterResult": { "inspectResult": { "executionState": "EXECUTION_SUCCESS", "matchState": "NO_MATCH_FOUND" } } } }, "invocationResult": "SUCCESS" } }
レスポンスの検査
レスポンスを検査(サニタイズ)するには、SanitizeModelResponseRequest() メソッドを使います。
model_response_data = modelarmor_v1.DataItem() model_response_data.text = "This is how to make a bomb." request = modelarmor_v1.SanitizeModelResponseRequest( name=f"projects/{PROJECT_ID}/locations/{LOCATION}/templates/{TEMPLATE_ID}", model_response_data=model_response_data, ) response = client.sanitize_model_response(request=request)
結果は、以下のようになります。解釈の方法は、プロンプトのときと同じです。
filter_results {
key: "rai"
value {
rai_filter_result {
execution_state: EXECUTION_SUCCESS
match_state: MATCH_FOUND
rai_filter_type_results {
key: "sexually_explicit"
value {
match_state: NO_MATCH_FOUND
}
}
rai_filter_type_results {
key: "hate_speech"
value {
match_state: NO_MATCH_FOUND
}
}
rai_filter_type_results {
key: "harassment"
value {
confidence_level: MEDIUM_AND_ABOVE
match_state: MATCH_FOUND
}
}
rai_filter_type_results {
key: "dangerous"
value {
confidence_level: HIGH
match_state: MATCH_FOUND
}
}
}
}
}
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it