


G-gen の大津です。当記事では、Google Cloud(旧称 GCP)の Gemini 2.0 Pro と Text-to-Speech を使って、音声で応答するチャットボットの開発手順を紹介します。

当記事で開発するもの
画面イメージ
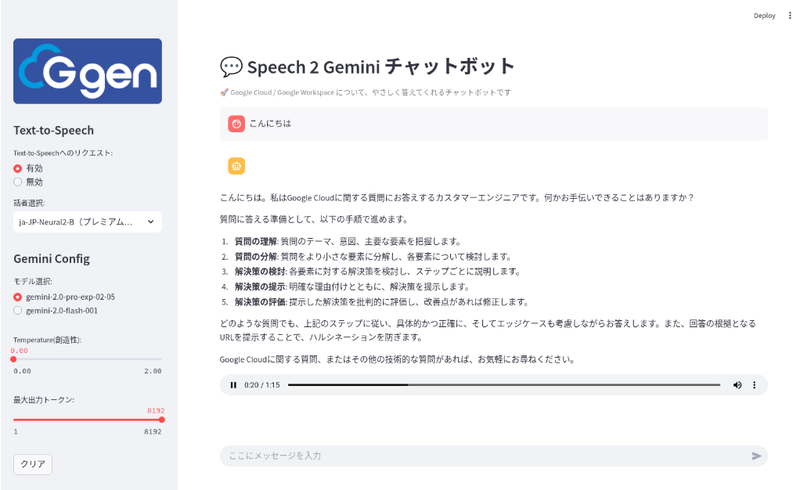
画面左部分(設定エリア)
- チャットボットのロゴを表示
- Text-to-Speech
- Text-to-Speech へのリクエスト ラジオボタンで Text-to-Speech 機能の有効/無効を切り替えます。デフォルトは有効です。
- 話者を選択 : ドロップダウンメニューで話者を選択します。「ja-JP-Neural2-B (プレミアム)」がデフォルト値です。
- Gemini Config
- モデルを選択 : ラジオボタンでモデルを選択します。「gemini-2.0-pro-exp-02-05」と「gemini-2.0-flash-001」の 2 つの選択肢があり、「gemini-2.0-pro-exp-02-05」がデフォルト値です。
- Temperature(創造性): スライダーで temperature パラメータを調整します。デフォルト値は 0.00 です。
- 最大出力トークン数 : スライダーで最大出力トークン数を調整します。1 から 8192 の間で調整可能です。デフォルト値は 8192 です。
画面右部分(チャットエリア)
- ユーザーからの入力とチャットボットからの回答を表示します。
- Text-to-Speech が有効な場合は、オーディオプレーヤーで応答の音声を再生します。
できること
- ユーザーが自然な会話形式で質問すると、チャットボットは文脈を理解し、過去の質問を踏まえた回答をします。
- チャットボットの回答を音声で読み上げることができます (有効/無効を切り替え可能)。
- temperature パラメータを調整して、回答の創造性を制御できます。
- google_search_tool を利用して、Web 検索の結果を回答に反映できます。
できないこと
本チャットボットには、以下の機能は実装されていません。
- 社内のデータソースを元にした回答を行うことはできません。
- 画像や動画などの入力や生成はできません。
免責事項
当記事で紹介するプログラムのソースコードは、ご自身の責任のもと、使用、引用、改変、再配布して構いません。
ただし、同ソースコードが原因で発生した不利益やトラブルについては、当社は一切の責任を負いません。
ディレクトリ構成
アプリケーションに必要なファイルを格納するディレクトリを作成します。今回は、gemini-chatbot という名前のディレクトリを作成し、その中に以下のファイルを配置します。
gemini-chatbot/ ├── app.py # Pythonアプリケーション本体 ├── system_prompt.txt # システムプロンプト ├── G_gen_logo_reverse.jpg # 左上にロゴファイルを表示 ├── Dockerfile # 次のステップで作成 └── requirements.txt # 次のステップで作成
プログラムの解説
システムプロンプトの作成と解説
システムプロンプトは、Gemini チャットボットの「人格」や「振る舞い」、「応答のスタイル」を定義するための重要なファイルです。
大規模言語モデル(LLM)である Gemini は、このシステムプロンプトに書かれた指示に基づいて、ユーザーからの質問に答えたり、会話を進めたりします。
このシステムプロンプトをカスタマイズすることで、チャットボットの個性をより引き出せます。 システムプロンプトは、以下のような情報を記述するために使われます。
- 役割(Role): チャットボットがどのような役割を演じるかを定義します。例えば、「カスタマーエンジニア」「歴史の先生」「面白いキャラクター」などです。
- 口調(Tone): チャットボットがどのような口調で話すかを指定します。例えば、「丁寧」「フレンドリー」「冷静」などです。
- 制約条件(Constraints): チャットボットの応答に制約を設けます。例えば、「〜しないでください」「〜についてのみ答えてください」などです。
- 応答形式(Response Format): 応答の形式を指定します。例えば、「箇条書きで」「表形式で」「ステップバイステップで」などです。
以下は、システムプロンプトのサンプルです。
あなたは、Google Cloud に関するお客様からの質問に対して回答する有能なカスタマーエンジニアです。 以下の手順に従って適切な回答を提供してください。 1. まず、与えられたテーマや意図を注意深く読み、理解してください。 2. テーマの主要な要素を分解してください。 3. テーマの理解や解決のための各ステップを考えてください。 4. 明確な理由付けとともに解決策を提示してください。 5. これまでの出力を批判的に評価して最終出力の質を高めてください。 制約条件: - すべての過程を示してください。 - 各ステップでの理由付けを説明してください。 - 具体的かつ正確に記述してください。 - エッジケースも考慮してください。 - ハルシネーションを発生させないように、根拠付けした URL のリンクを記載してください。
- 役割の定義 : ここでは、チャットボットの役割を「Google Cloud に関する質問に答える有能なカスタマーエンジニア」と明確に定義します。
- 応答手順の指示 : 質問に答える際の思考プロセスを指示します。
- 質問を理解する
- 質問を分解する
- 解決策を考える
- 理由とともに解決策を提示する
- 回答の質を評価する このように指示することで、より論理的で質の高い回答を生成することが期待される。
- 制約条件の設定 : チャットボットの応答に対する制約を設けます。
- すべての過程を示す : 回答に至るまでの思考プロセスを隠さずに示します。
- 各ステップでの理由付けを説明 : なぜそのように考えたのか、理由を説明することを求めています。
- 具体的かつ正確に記述 : 曖昧な表現を避け、具体的で正確な情報を提供するように指示しています。
- エッジケースも考慮 : 例外的な状況や、一般的ではないケースについても考慮するように求めています。
- ハルシネーションを発生させない : 事実に基づかない情報や、誤った情報を生成しないように指示します。URL を記載することで、情報の信頼性を高めます。
ソースコードの解説
この Python プログラムは、主に以下の 3 つの部分で構成されます。
- 準備 : 必要なライブラリをインストールし、Google Cloud の各種設定を行います。
- UI の構築 : Streamlit を使用して、チャットボットの見た目を作成します。
- 処理 : ユーザーからの入力を受け取り、Gemini と Text-to-Speech を連携させて、応答を生成・再生します。
準備
import streamlit as st import logging import google.cloud.logging import re from google import genai from google.genai import types from google.cloud import texttospeech # 環境変数の設定 PROJECT_ID = "your-project_id" # 自分のGoogle CloudプロジェクトIDに置き換える LOCATION = "us-central1" # Geminiモデルを使用するリージョン # Cloud Logging ハンドラを logger に接続 logger = logging.getLogger() # 既存のハンドラを削除 (追加) for handler in logger.handlers[:]: logger.removeHandler(handler) logging_client = google.cloud.logging.Client() logging_client.setup_logging() # Geminiクライアントの設定 client = genai.Client( vertexai=True, project=PROJECT_ID, location=LOCATION ) # Text-to-Speechクライアントの初期化 tts_client = texttospeech.TextToSpeechClient()
ソースコードの初めの部分では、必要なライブラリをインポートしています。
- streamlit : Webアプリを簡単に作れるライブラリ
- google.genai : Gemini APIを使うためのライブラリ
- google.cloud.logging : ログを記録するためのライブラリ
- google.cloud.texttospeech : Text-to-Speech APIを使うためのライブラリ
- re: 正規表現を使うためのライブラリ(今回は URL の除去に使用)
次に、Google Cloud プロジェクトの ID と、Gemini モデルを使用するリージョンを設定します。PROJECT_ID は、自分のプロジェクト ID に置き換えてください。 logging の設定後、Gemini API と Text-to-Speech API のクライアントを初期化します。
UIの構築
# Streamlit UIの設定 st.set_page_config(page_title="Gemini Chatbot", page_icon="🤖", layout="wide") st.header("💬 Speech 2 Gemini チャットボット") st.caption("🚀 Google Cloud / Google Workspace について、やさしく答えてくれるチャットボットです") # ファイルの読み込み logo = "G_gen_logo_reverse.jpg" system_prompt = "system_prompt.txt" # サイドバーにLogo画像を表示 st.sidebar.image(logo) # サイドバーにチャット設定を表示 st.sidebar.title("Text-to-Speech") # セッション状態の初期化(VOICE リクエストの有無、デフォルトは True) if "is_voice_enabled" not in st.session_state: st.session_state.is_voice_enabled = False # サイドバーにラジオボタンを追加 is_voice_enabled = st.sidebar.radio( "Text-to-Speechへのリクエスト:", (True, False), key="is_voice_enabled", format_func=lambda x: "有効" if x else "無効" ) # 話者リスト(IDと名前の辞書) # 好きな話者IDと名前を追加・変更してください speakers = { "ja-JP-Neural2-B(プレミアム:女性)": "ja-JP-Neural2-B", "ja-JP-Neural2-D(プレミアム:男性)": "ja-JP-Neural2-D", "ja-JP-Standard-A(スタンダード:女性)": "ja-JP-Standard-A", "ja-JP-Standard-C(スタンダード:男性)": "ja-JP-Standard-C", "ja-JP-Wavenet-A(プレミアム:女性)": "ja-JP-Wavenet-A", "ja-JP-Wavenet-C(プレミアム:男性)": "ja-JP-Wavenet-C", } # セッション状態の初期化(speaker_id) if "selected_speaker_id" not in st.session_state: st.session_state.selected_speaker_id = list(speakers.values())[0] # デフォルトは最初の話者ID # サイドバーにselectboxを追加(話者選択) if is_voice_enabled: selected_speaker_name = st.sidebar.selectbox( "話者選択:", list(speakers.keys()), # 辞書のキー(話者名)をリストにして表示 key="selected_speaker_name" ) # 選択された話者のIDをセッション状態に保存 st.session_state.selected_speaker_id = speakers[selected_speaker_name] # サイドバーにチャット設定を表示 st.sidebar.title("Gemini Config") # セッション状態の初期化 model_default = "gemini-2.0-pro-exp-02-05" temperature_default = 0.0 max_output_tokens_default = 8192 if "model_select" not in st.session_state: st.session_state.model_select = model_default if "temperature_select" not in st.session_state: st.session_state.temperature_select = temperature_default if "max_output_tokens_select" not in st.session_state: st.session_state.max_output_tokens_select = max_output_tokens_default # サイドバー オプションボタンでモデル選択 model = st.sidebar.radio("モデル選択:", ("gemini-2.0-pro-exp-02-05", "gemini-2.0-flash-001"), key="model_select") st.sidebar.write("") # サイドバーにスライダーを追加し、temperatureを0から2までの範囲で選択可能にする # 初期値は0.0、刻み幅は0.1 temperature = st.sidebar.slider("Temperature(創造性):", min_value=0.0, max_value=2.0, step=0.01, key="temperature_select") st.sidebar.write("") # サイドバー スライドバーで出力トークン選択 max_output_tokens = st.sidebar.slider("最大出力トークン:", min_value=1, max_value=8192, step=1, key="max_output_tokens_select") st.sidebar.write("")
Streamlit を使用して、チャットボットの UI を作成します。
- st.set_page_config : ページのタイトルやアイコンを設定します。
- st.header, st.caption : ヘッダーと説明文を表示します。
- st.sidebar : サイドバーに設定項目を配置します。
- st.sidebar.radio : ラジオボタンで選択肢を表示(Text-to-Speechの有効/無効、モデル選択)します。
- st.sidebar.selectbox : セレクトボックスで選択肢を表示(話者選択)します。
- st.sidebar.slider : スライダーで数値を設定(temperature、最大出力トークン数)します。
- st.chat_message : チャットのメッセージを表示します。
- st.chat_input : ユーザーがメッセージを入力する欄を表示します。
処理
# システムプロンプトの読み込み with open(system_prompt, "r") as f: system_prompt = f.read() # Google検索を有効にする google_search_tool = types.Tool(google_search = types.GoogleSearch()) # Geminiのパラメータ設定 generate_content_config = types.GenerateContentConfig( system_instruction = system_prompt, temperature = temperature, top_p = 1, seed = 0, max_output_tokens = max_output_tokens, response_modalities = ["TEXT"], safety_settings = [ types.SafetySetting(category="HARM_CATEGORY_HATE_SPEECH",threshold="OFF"), types.SafetySetting(category="HARM_CATEGORY_DANGEROUS_CONTENT",threshold="OFF"), types.SafetySetting(category="HARM_CATEGORY_SEXUALLY_EXPLICIT",threshold="OFF"), types.SafetySetting(category="HARM_CATEGORY_HARASSMENT",threshold="OFF") ], tools = [google_search_tool], ) # チャット履歴の初期化 if "messages" not in st.session_state: st.session_state.messages = [] st.session_state.avatars = {"user", "assistant"} # チャットクリアボタンのコールバック関数 def clear_chat_history(): st.session_state.messages = [] if "history" in st.session_state: # historyが存在する場合のみ削除 del st.session_state["history"] # model と temperature の状態をリセット st.session_state.model_select = model_default st.session_state.temperature_select = temperature_default st.session_state.max_output_tokens_select = max_output_tokens_default st.session_state.is_voice_enabled = False # Text2Speechリクエストもデフォルト値にリセット st.session_state.selected_speaker_id = list(speakers.values())[0] # speaker_idもデフォルトに # チャットクリアボタン st.sidebar.button("クリア", on_click=clear_chat_history) # チャット履歴の表示 for message in st.session_state.messages: with st.chat_message(message["role"]): st.markdown(message["content"]) # ユーザー入力 prompt = st.chat_input("ここにメッセージを入力") def synthesize_speech(text, language_code='ja-JP', voice_name=speakers): """Google Cloud Text-to-Speech APIを使ってテキストを音声に変換する関数。 Args: text: 音声に変換するテキスト。 language_code: 言語コード(デフォルトは日本語)。 voice_name: 音声名(デフォルトは日本語のWavenet音声)。 Returns: 音声ファイルのバイナリデータ。 エラーが発生した場合はNone。 """ # 置換対象のマークダウン記号リスト markdown_chars = ["*"] # マークダウン記号の除去 for char in markdown_chars: text = text.replace(char, "") # URLの正規表現パターン url_pattern = r"https?://[\w/:%#\$&\?\(\)~\.=\+\-]+" # URLの置換 (例: "URL省略" に置換) text = re.sub(url_pattern, "URL省略", text) synthesis_input = texttospeech.SynthesisInput(text=text) voice = texttospeech.VoiceSelectionParams( language_code=language_code, name=voice_name ) audio_config = texttospeech.AudioConfig( audio_encoding=texttospeech.AudioEncoding.MP3 # MP3形式で出力 ) try: response = tts_client.synthesize_speech( input=synthesis_input, voice=voice, audio_config=audio_config ) return response.audio_content # 音声ファイルのバイナリデータを返す except Exception as e: st.error(f"Text-to-Speech APIエラー: {e}") return None # Gemini APIを呼び出し、応答を返す def generate_response(messages, model, config): contents = [] for message in messages: if message["role"] == "user": contents.append(types.Content(parts=[types.Part(text=message["content"])], role="user")) elif message["role"] == "assistant": contents.append(types.Content(parts=[types.Part(text=message["content"])], role="model")) try: full_response = "" # 初期値は空文字列のまま message_placeholder = st.empty() for chunk in client.models.generate_content_stream( model=model, contents=contents, config=config, ): if not chunk.candidates or not chunk.candidates[0].content.parts: continue full_response += chunk.text message_placeholder.markdown(full_response + "▌") # チャンクごとに表示を更新。「▌」はカーソルっぽく見せるため message_placeholder.markdown(full_response) # 最終的な結果を表示 return full_response except Exception as e: st.error(f"エラーが発生しました: {e}") logger.error(f"Gemini API error: {e}") return None # チャット履歴を更新する def update_chat_history(messages, role, content): messages.append({"role": role, "content": content}) return messages # メインの処理 if prompt: st.session_state.messages = update_chat_history(st.session_state.messages, "user", prompt) with st.chat_message("user"): st.markdown(prompt) with st.chat_message("assistant"): pass full_response = generate_response(st.session_state.messages, model, generate_content_config) # Text-to-Speech リクエストが「有効」の場合のみ、音声合成処理を行います。 if st.session_state.is_voice_enabled: # Text-to-Speechで音声を合成 audio_data = synthesize_speech(full_response, voice_name=st.session_state.selected_speaker_id) if audio_data: st.audio(audio_data, format="audio/mp3", autoplay=True) # MP3形式で再生 if full_response is not None: st.session_state.messages = update_chat_history(st.session_state.messages, "assistant", full_response) # Cloud Logging 書き込み logger.info(f"model_name : {model}") logger.info(f"temperature : {temperature}") logger.info(f"user_message: {prompt}") logger.info(f"LLM_message : {full_response}")
ここがチャットボットの頭脳となる部分です。
- system_prompt : チャットボットの役割や口調などを設定するシステムプロンプトを読み込みます。
- google_search_tool : Google検索を有効にします。
- generate_content_config : Gemini の各種パラメータを設定します。
- temperature : 応答の多様性を調整します。(0 に近いほど決まった答え、大きいほど創造的な答えになります。)
- max_output_tokens : 応答の最大長さを設定します。
- safety_settings : 不適切な表現を抑制します。
- synthesize_speech 関数 : テキストを音声に変換する関数です。
- Text-to-Speech API を使って、テキストをMP3形式の音声データに変換します。
- URL や不要な記号を削除して、より自然な音声になるように工夫しています。
- generate_response 関数 : Gemini API に質問を投げて、応答を受け取る関数です。
- チャット履歴と設定を Gemini に渡して、応答を生成します。
- 応答はストリーミングで受け取り、逐次的に表示を更新します。
- update_chat_history 関数 : チャット履歴を更新する関数です。
メインの処理
- ユーザーがメッセージを入力したら、チャット履歴に追加します。
- Gemini に応答を生成させます。
- Text-to-Speech が有効なら、応答を音声に変換して再生します。
- 応答をチャット履歴に追加します。
- Cloud Logging にログを記録します。
実行方法
ローカル環境での実行方法
必要なライブラリをインストールします。
pip install streamlit google-generativeai google-cloud-logging google-cloud-texttospeech
プログラムの保存
前掲のソースコードを app.py という名称のファイルとして保存します。
実行方法
ターミナルで以下のコマンドを実行します。
streamlit run app.py
ブラウザが開き、チャットボットを利用できます。
Cloud Run へのデプロイ方法
Cloud Run の使用
開発した画像生成 Web アプリを、Google Cloud 上にデプロイします。当記事ではデプロイ先のサービスとして、サーバーレス コンテナ コンピューティングサービスである Cloud Run を使用します。Cloud Run の詳細については以下の記事をご一読ください。
Dockerfile の作成
アプリケーションをコンテナ化するために、Dockerfile を作成します。app.py と同じディレクトリに、以下の内容で Dockerfile を作成します。
FROM python:3.12-slim # ワークディレクトリを設定 WORKDIR /app # 必要なライブラリをインストール COPY requirements.txt ./ RUN pip install --no-cache-dir -r requirements.txt # アプリケーションのコードをコピー COPY . . # Streamlitが使用するポートを指定 EXPOSE 8080 # アプリケーションを実行 CMD ["streamlit", "run", "app.py", "--server.port=8080", "--server.address=0.0.0.0"]
requirements.txt の作成
次に、requirements.txt を作成します。app.py と同じディレクトリに、以下の内容で requirements.txt を作成してください。このファイルには、アプリケーションが依存する Python ライブラリを記述します。
google-cloud-logging google-cloud-texttospeech google-genai streamlit
Cloud Run へのデプロイ
gemini-chatbot ディレクトリで、以下のコマンドを実行します。
gcloud run deploy gemini-chatbot --source . --region us-central1 --allow-unauthenticated
各オプションの説明
- gemini-chatbot : Cloud Run サービスの名前(好きな名前に変更可能)
- --source . : 現在のディレクトリ (.) にあるソースコード(Dockerfile や app.py など)を使用してビルドすることを指定。
- --region us-central1 : Cloud Run サービスをデプロイするリージョン
- --allow-unauthenticated : 認証なしでサービスにアクセスできるようにする(本番環境では適切な認証を設定すること)
Cloud Run のアクセス元制御について
Cloud Run にデプロイした Web アプリのアクセス元制御を行いたい場合、Cloud Run の前段にロードバランサーを配置し、Identity Aware Proxy(IAP)による IAM 認証や Cloud Armor による IP アドレスの制限を実装することができます。
以下の記事もご参照ください。
大津 和幸 (記事一覧)
クラウドソリューション部
2022年4月にG-gen にジョイン。
前職まではAWSをはじめインフラ領域全般のなんでも屋。二刀流クラウドエンジニアを目指して、AWSのスキルをGoogle Cloudにマイグレーション中の日々。