


当記事では、BigQuery に統合された Vertex AI Feature Store というベクトルストアと、テキストの意味をベクトル化できる Vertex AI Text-Embeddings API を使った活用事例をご紹介します。
当記事は Google Cloud Champion Innovators Advent Calendar 2023 の7日目の記事です。

Vertex AI Feature Store とは
Vertex AI Feature Store は、Google Cloud が提供するフルマネージドのベクトルストアです。同サービス自体は従来より存在しましたが、2023年10月に 「BigQuery 統合版」がプレビュー公開され、同年11月に GA(一般公開)となりました。以前のバージョンはレガシー(従来)版という位置づけになりました。
Vertex AI Feature Store はベクトルと呼ばれる機械学習の特徴量を保存する専用のデータストアです。Bigtable 等の Google のインフラを利用した高速なオンライン(リアルタイム)特徴量データストアを簡単に構築でき、自前で構築する必要がなくなります。また、今回新たに特徴量のベクトル検索機能が追加されたため、ベクトル検索エンジンとして使うことも可能になりました。
Feature Store の特徴量ストアは、 BigQuery の既存テーブルから自動的に同期できます。そのため、これまでのようにデータウェアハウス(BigQuery)、特徴量ストア、ベクトル検索インデックスのそれぞれを別々に用意する必要がありません。ベクトル検索インデックスの構築も自動的に行われます。
Vertex AI Text-Embeddings API とは
LLM(大規模言語モデル)によって、テキストの意味解釈をしたベクトル(数値表現)を返す API です。ベクトル抽出用の最新版安定モデルは2023年12月時点で textembedding-gecko@002 です。
- 参考 : 利用可能な安定版のモデル
ここで、そもそものベクトルとは何で、どう使うかの説明をします。例えば「海ぶどう」と「ラーメン」という言葉をLLMがベクトルで表現するしくみを単純化した例が以下の図になります。

この図では、横軸が「カロリー」、縦軸が「沖縄度」だとした場合に、 「海ぶどう」はカロリーが低く沖縄っぽさが高いため、(カロリー, 沖縄度)=(0.1, 0.9)というベクトルで表現されています。
一方で、「ラーメン」はカロリーが高く沖縄というよりは万国共通の食べ物のため、(カロリー, 沖縄度)=(0.9, 0.2)というベクトルで表現されています。
これはあくまでごく単純化した例ですが、Embeddings for Text はこのように個々の言葉や文章の意味を相対的な距離で表す768次元のベクトルを返します。あとはベクトル同士の距離を求めるだけで、近い概念の言葉を見つけることができます。
また、Embeddings for Text では個々の単語に限らず、最大3000トークンまでの文章の意味をベクトル化することも可能です。
例えば、「麺の上に豚肉がのった沖縄料理」≒「沖縄(ソーキ)そば」となりますが、Vertex AI Embeddings for Text によって、両者が近い概念であることを踏まえた数値表現を得ることができます。
ベクトルは単なる数値の集まりであり、簡単な四則演算によりベクトル同士の距離を計算できます。この距離の最も近いものが意味的にも近いものとなります。この仕組みを使い、例えばユーザーが入力した検索クエリを Embeddings for Text によりベクトル化して、それに距離の近いものを順に返すことで、意味の近さによる検索(意味検索)機能を実装できます。
つまり、Embeddings for Text で取得したベクトルをBigQueryテーブルに保存するだけで、Feature Store のベクトル検索機能を使った「意味検索」を簡単に実現できます。
ベクトル検索は、レコメンドやグラウンディングといった用途に活用できます。
活用例
①レコメンド
レコメンドの仕組みは色々あるため、すべては網羅できませんが、ここでは EC サイト等でよく見る以下の 2 つを考えてみます。
- 自分と似ているユーザが買った商品をおすすめされる(≒ ユーザベースレコメンド)
- 自分が過去に買ったものと似ている商品をおすすめされる(≒ アイテムベースレコメンド)
「1. 自分と似ているユーザが買った商品をおすすめされる」に関しては、自分と似ているユーザを探すために、ユーザ同士の類似性を割り出せれば良さそうです。同様に、「2. 自分が過去に買ったものと似ている商品をおすすめされる」に関しては、商品同士の類似性を求めれば良いことになります。
先程のベクトル検索の内容を踏まえると、ユーザにしろ、商品にしろ、一旦ベクトル化してしまえば、以下のように掛け合わせでレコメンドすることができます。この手法は「Two-Tower」モデルと呼ばれ、これまで一般的だった「誰がどの商品を何個買ったか」のような購買データのみによるレコメンドモデルではなく、ユーザ属性や商品属性といったあらゆる特徴量を活用できる拡張性があります。
参考:「Google を支える推薦モデル「Two-Tower」とベクトル近傍検索技術」

似たような商品ばかりおすすめされるようであれば、(2)類似アイテムに関しては、非 類似度を見るようにしてもいいです。潜在的な商品要求にマッチする可能性があります。
②グラウンディング
ベクトル検索により生成AIで扱えるデータを拡張したりハルシネーションを抑制する手法はグラウンディングと呼ばれます。
以下のように、質問文をベクトル化し、最も類似するアイテムの情報を引っ張り出して、プロンプトによって回答文を仕上げます。

処理フローは以下の通り。
質問文をベクトル化
例:「うどんが好きなんですが、沖縄でそれと似ている食べ物について教えてください。→ (0.5, 0.9)
ベクトル検索で最も類似するアイテムを検索
例:沖縄そば(0.6, 0.9)
ヒットしたアイテムの情報(カラム)を変数化し、プロンプトに埋め込んで生成 AI に与える
例:「あなたは沖縄観光大使のチャットボットです。お客様からの商品問い合わせ 「
${質問}」 に対して、沖縄の魅力が十分に伝わるようなレコメンドをしてください。前提となる情報は、商品名となる${名前}、商品の概要は${概要}、商品の売上額は${売上額}、商品の売上数は${売上数}とし、これらを統合して訴求するのです」回答を得る
例:「オススメは 沖縄そば と言いまして、日本の・・。売上額は 10億円、売上数は・・・」
ポイントは、「概要」のような文章と、「売上額」や「売上数」のような集計情報を組み合わせることで、自社データを活用したオリジナルの生成AIによる検索サービスが作れる点です。
LLM の基盤モデルは最新情報や自社の情報は持っていないため、このようにリアル情報に「接地(=グラウンディング)」させることで、ハルシネーション(幻覚)の問題を抑制できます。
サンプルアプリ
「活用例②:グラウンディング」のサンプルとして、Google 画像検索の仕組みを真似て、問い合わせに最もマッチする食品アイテムを表示するアプリを作ってみました。
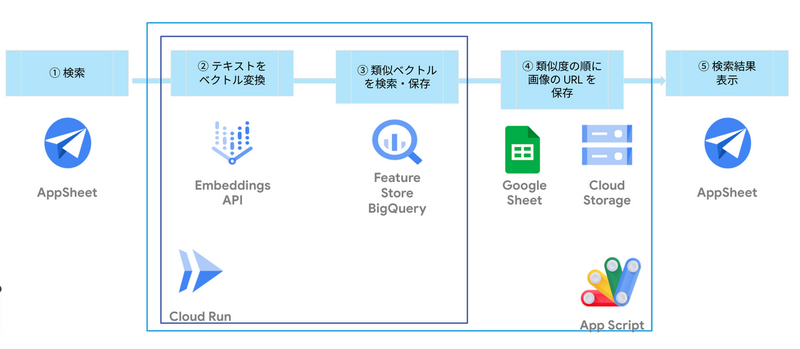
アーキテクチャ
フロント側は AppSheet というノーコードローコードでさくっとアプリケーションを作れるツールで構築しています。機能説明とアーキテクチャは以下のとおりです。
検索画面
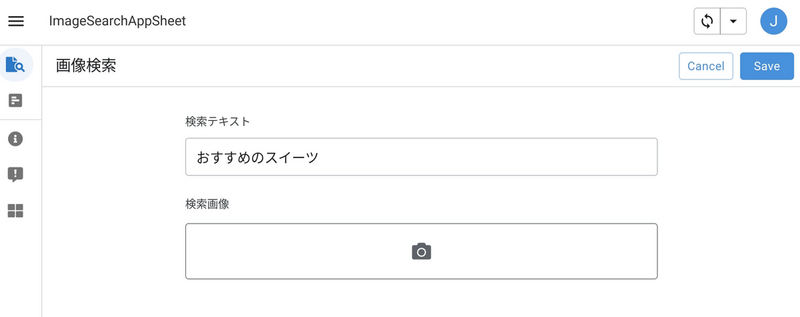
ユーザからの入力を受け付ける画面は以下です。ここに質問を打ち込むと、生成 AI が最もマッチする商品を探して、商品説明をしてくれます。
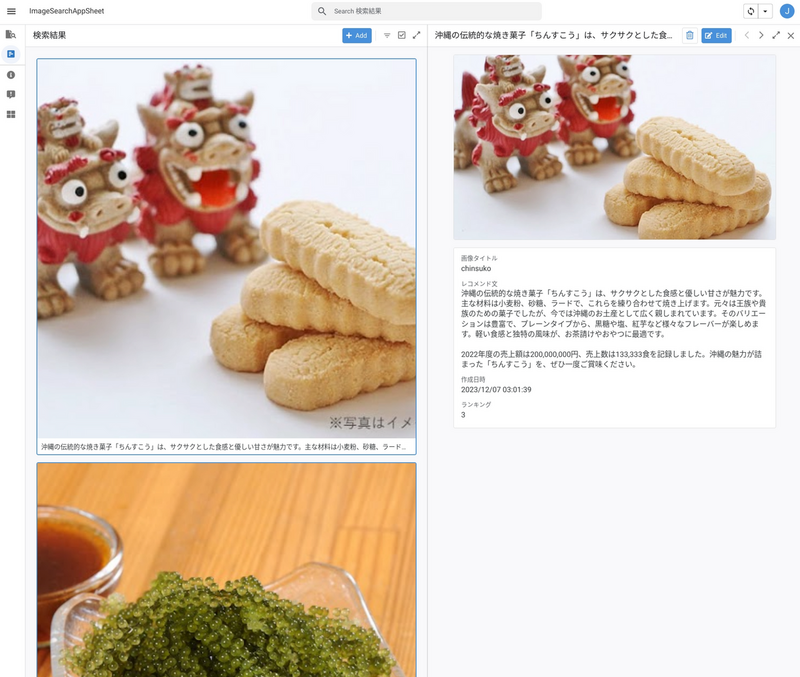
検索結果
「おすすめのスイーツ」という問い合わせに対して、最もマッチしたのは以下の商品です。
データの拡張
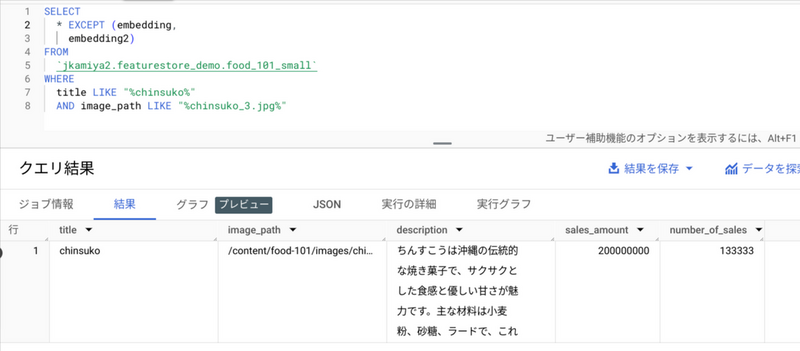
BigQuery のレコードとしては以下です。embedding 列は非表示にしていますが、こちらをベクトル検索に使っています。
このテーブルにある 「description」、「sales_amount」、「number_of_sales」列をさらに言語生成系の API である text-unicorn@001 にプロンプトともに入力しています。
回答文
以下は、最終的な回答結果です。概要説明だけでなく、売上額や売上数などの集計情報も自然に含まれた形になっています。
沖縄の伝統的な焼き菓子「ちんすこう」は、サクサクとした食感と優しい甘さが魅力です。主な材料は小麦粉、砂糖、ラードで、これらを練り合わせて焼き上げます。元々は王族や貴族のための菓子でしたが、今では沖縄のお土産として広く親しまれています。そのバリエーションは豊富で、プレーンタイプから、黒糖や塩、紅芋など様々なフレーバーが楽しめます。軽い食感と独特の風味が、お茶請けやおやつに最適です。
2022年度の売上額は200,000,000円、売上数は133,333食を記録しました。沖縄の魅力が詰まった「ちんすこう」を、ぜひ一度ご賞味ください。
サンプルコード
以下の処理に関してノートブックにコードをまとめました。
- 画像やテキストからベクトルを抽出して BigQuery に格納する(マルチモーダルモデルとテキストモデル両方のサンプルを掲載)
- Vertex AI Feature Store にオンラインインスタンスを立てる
- 問い合わせをベクトル化し、Vertex AI Feature Store で類似探索を行い、結果を表示する
他の生成 AI 事例
Google Cloud を用いた生成 AI のアーキテクチャや実装例については弊社 G-gen のブログでも扱っているため、興味のある方は御覧ください。
神谷 乗治 (記事一覧)
クラウドソリューション部
クラウドエンジニア。2017 年頃から Google Cloud を用いたデータ基盤構築や ML エンジニアリング、データ分析に従事。クラウドエース株式会社システム開発部マネージャーを経て現職。Google Cloud Partner Top Engineer 2023,2024、Google Cloud Champion Innovators(Database)、著書:「GCPの教科書III【Cloud AIプロダクト編】」