


G-gen の佐々木です。当記事では Google Kubernetes Engine(以下、GKE)で 予備の容量プロビジョニング(spare capacity provisioning) を使用することで、ワークロードを素早くスケールアウトする方法を解説します。
- GKE とは
- ノードの自動プロビジョニングを使用したスケールアウトの問題点
- 予備の容量プロビジョニングについて
- 予備の容量プロビジョニングを使用する

GKE とは
GKE はコンテナオーケストレーションツールである Kubernetes を、Google マネージドのクラスタで使用することができるサービスです。
GKE ではノードの管理をユーザーが行うことで柔軟な要件に対応できる Standard モード のクラスタと、ノードの管理を Google に任せ、ワークロードの管理のみに集中することができる Autopilot モード のクラスタを選択することができます。
GKE の詳細については以下の記事で解説しています。
ノードの自動プロビジョニングを使用したスケールアウトの問題点
ノードの自動プロビジョニング が有効化されている GKE クラスタでは、Pod がスケールアウトするとき、既存のノードに新しい Pod を起動するための容量がない場合に新しいノードが自動で作成されます。
しかし、新しいノードの起動には約 80 秒 ~ 120 秒かかるため、急激なトラフィック増加などに素早く対応できない場合があります。

特に Autopilot モードのクラスタでは、ノードのコンピューティングリソース量をユーザーが指定することができないため、スケールアウト時のリソース使用量を考慮してノードのマシンタイプを設定したり、事前にノード数を増やしておいたりして対策することが難しくなっています。
当記事では、事前にノード数を増やしておき Pod をすぐに起動できるようにする方法として、予備の容量プロビジョニング を使用します。当機能は Autopilot クラスタと Standard クラスタの両方で利用可能です。
予備の容量プロビジョニングについて
予備の容量プロビジョニングの概要
予備の容量プロビジョニングでは、Kubernetes の PriorityClass オブジェクトを使用し、一定数の 優先度の低い Pod をノードで実行します。こうすることで予めノードを増やしておくことができ、ワークロードの Pod がスケールアウトする際に、優先度の低い Pod を終了してワークロードの Pod に置き換えることができます。
ここで使用する優先度の低い Pod は プレースホルダ Pod、または バルーン Pod と呼ばれます。当記事では公式ドキュメントに従いプレースホルダ Pod と記載します。
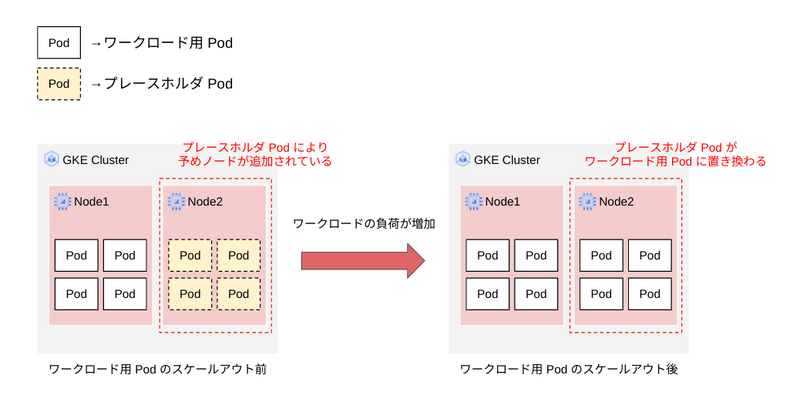
予備の容量プロビジョニングでは、プレースホルダ Pod の実行の仕方によって、一貫した容量のプロビジョニング と 単一のイベント容量のプロビジョニング の 2種類の方法を使うことができます。
一貫した容量のプロビジョニング
一貫した容量のプロビジョニングでは、Deployment を使用することで、クラスタ内で常に実行されるプレースホルダ Pod を配置します。
プレースホルダ Pod の実行に必要な容量だけノードがプロビジョニングされ、ワークロードのスケールアウトが必要になった際はプレースホルダ Pod に置き換える形で Pod を追加することができます。
プレースホルダ Pod はワークロードの Pod に置き換えられますが、Deployment を使用してデプロイされているために、一度ワークロードの Pod に置き換えられたあと、プレースホルダ Pod の数を維持しようとします。そのため、GKE クラスタは新たなノードを追加してプレースホルダ Pod を再作成します。
したがって、クラスタにはワークロードを実行するために必要な容量よりも多くの容量が常に確保される点には注意が必要です。
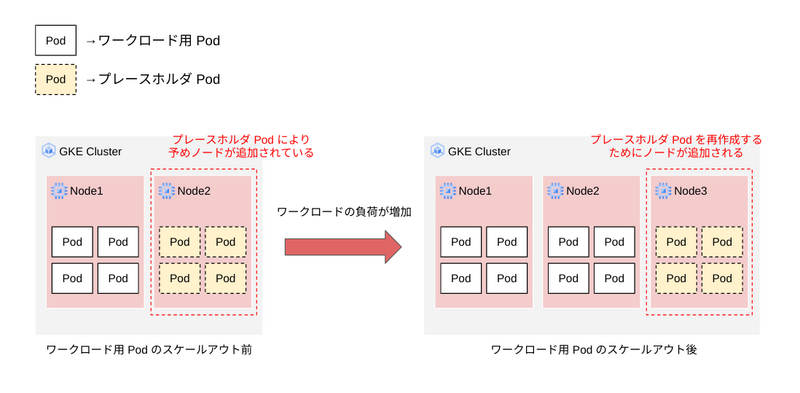
単一イベント容量のプロビジョニング
単一イベント容量のプロビジョニングでは、Job を使用することで特定の期間だけプレースホルダ Pod を起動し、その実行に必要な容量だけノードをプロビジョニングします。
ワークロードのスケールアウトが必要になると、プレースホルダ Pod がワークロードの Pod と置き換わる点は一貫した容量のプロビジョニングと同様ですが、Job で実行されているため、置き換わったあとに Pod が再作成されることはありません。

2 つの方法の比較
プレースホルダ Pod の作成に Job を使用する場合(単一イベント容量のプロビジョニング)は Deployment を使用する場合(一貫した容量のプロビジョニング)とは異なり、終了したプレースホルダ Pod を再作成するような動作はしないため、プレースホルダ Pod の再作成するためにノードが追加されることはありません。したがって、プレースホルダ Pod 用に確保される容量は Job を使用したほうが抑えられます。
GKE の Standard モードでは起動しているノードあたりの時間料金、Autopilot モードでは Pod がリクエストしているリソース量あたりの時間料金が発生するため、必要なときだけプレースホルダ Pod を実行するほうにコストメリットがあります。
ただし、Job を使用する場合はワークロードがスケールアウトするタイミングをある程度は把握しておき、それに合わせて Job を作成しておく必要があります。また、一度置き換えられたプレースホルダ Pod は再作成されないため、一日に何度もスケーリングをする必要があるワークロードの場合には向きません。Deployment を使用していればプレースホルダ Pod は常に存在するため、ワークロードがスケールアウトする余裕を持ち続けることができます。
予備の容量プロビジョニングを使用する
ここからは、予備の容量プロビジョニングを使用することで、Pod の起動時間が改善されるかどうかを検証します。
使用するマニフェストファイル
当記事で使用するマニフェストファイルは、公式ドキュメントに記載されているものを参考にしています。
priorityclasses.yaml
Pod に紐付けることができる PriorityClass オブジェクトを 2つ作成するマニフェストファイルです。
優先度は value フィールドに設定し、数値が大きいほど Pod の実行優先度が高くなります。
# priorityclasses.yaml apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: low-priority value: -10 # この PriorityClass を使用する Pod の優先度(値が小さいほど優先度が低い) preemptionPolicy: Never # この PriorityClass を使用する Pod は、これより優先度の低い Pod を削除しない(=Never) globalDefault: false description: "Low priority workloads" --- apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: default-priority value: 0 # この PriorityClass を使用する Pod の優先度 preemptionPolicy: PreemptLowerPriority # この PriorityClass を使用する Pod は、これより優先度の低い Pod を削除する(=PreemptLowerPriority) globalDefault: true # Pod に PriorityClass が明示的に設定されていない場合、これをデフォルトの PriorityClass とする description: "The global default priority."
1つ目の PriorityClass は低優先度のプレースホルダ Pod に紐付けるもので、優先度の値が -10 に設定されています。
2つ目の PriorityClass は globalDefault フィールドの値が true に設定されており、GKE クラスタにデプロイされる Pod にデフォルトで紐付けられます。preemptionPolicy フィールドの値が PreemptLowerPriority に設定されているため、この PriorityClass が紐付いた Pod が起動する際にノードの容量が足りていないと、優先度がより低い Pod を削除してから起動するように動作します。
test-deployment.yaml
このマニフェストファイルでは、ワークロードの Pod を想定したサンプルの Pod を 5 つ実行する Deployment を作成します。
PriorityClass を指定していないため、priorityclasses.yaml により作成された PriorityClass がある場合、これらの Pod の優先度は 0となります。
# test-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: helloweb labels: app: hello spec: replicas: 5 selector: matchLabels: app: hello tier: web template: metadata: labels: app: hello tier: web spec: containers: - name: hello-app image: us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0 ports: - containerPort: 8080 resources: requests: cpu: 400m memory: 400Mi
capacity-res-deployment.yaml(一貫した容量のプロビジョニングで使用)
プレースホルダ Pod を作成するためのマニフェストファイルでは、priorityClassName に低優先度の PriorityClass を指定し、10 個の Pod が優先度 -10 で作成されるようにします。
これらの Pod はノードの容量を予め確保しておき、ワークロードのスケールアウトが必要になったとき、ワークロードの Pod と置き換わります。
# capacity-res-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: capacity-res-deploy spec: replicas: 10 selector: matchLabels: app: reservation template: metadata: labels: app: reservation spec: priorityClassName: low-priority # 低優先度の PriorityClass を指定 terminationGracePeriodSeconds: 0 containers: - name: ubuntu image: ubuntu command: ["sleep"] args: ["infinity"] resources: requests: cpu: 500m memory: 500Mi
capacity-res-job.yaml(単一イベント容量のプロビジョニングで使用)
単一イベント容量のプロビジョニングでは Job を使用してプレースホルダ Pod を実行します。
このマニフェストファイルでは低優先度の Pod を Job として実行し、ワークロード用の Pod による置き換えが起こるか sleep コマンドの処理が終わる(10時間が経過する)と Pod が削除されます。
# capacity-res-job.yaml apiVersion: batch/v1 kind: Job metadata: name: capacity-res-job spec: parallelism: 10 backoffLimit: 0 template: spec: priorityClassName: low-priority terminationGracePeriodSeconds: 0 containers: - name: ubuntu-container image: ubuntu command: ["sleep"] args: ["36000"] resources: requests: cpu: 500m restartPolicy: Never
GKE クラスタの作成
以下のコマンドを使用して、検証用のクラスタを作成します。
当記事では Autopilot モードのクラスタを使用していきます。
# Autopilot モードの GKE クラスタを作成する
$ gcloud container clusters create-auto {クラスタ名} \
--region={リージョン} \
--project={プロジェクトID}
予備の容量プロビジョニングを使用しない場合
まず、予備の容量プロビジョニングを使用しない場合のワークロード用 Pod の起動時間を計測してみます。
作成した GKE クラスタのノードの初期状態を確認します。
# ノードの状態を確認 $ kubectl get nodes # 出力例 $ kubectl get nodes NAME STATUS ROLES AGE VERSION gk3-cluster-sasashun-gke-default-pool-69f9cf5d-m972 Ready <none> 74m v1.26.5-gke.1200 gk3-cluster-sasashun-gke-default-pool-b9c30e3b-z2jn Ready <none> 74m v1.26.5-gke.1200
次に、Pod の起動時間を確認するために、kubectl get pods コマンドで --watch オプションを使用して Pod のステータスをモニタリングします。
# Pod のステータスをモニタリングする $ kubectl get pods -w
別のターミナルから test-deployment.yaml をクラスタに適用し、ワークロード用の Pod をデプロイします。
# Pod のデプロイ(別のターミナルで実施) $ kubectl apply -f test-deployment.yaml
最初のターミナルで Pod のステータスをモニタリングしているため、各 Pod の STATUS 列が Running になるまで待機します。
今回の検証時の出力を以下に記載します。Pod がすべて実行されるまで、2分 30秒ほど要したことがわかります。
# 出力例 $ kubectl get pods -w NAME READY STATUS RESTARTS AGE helloweb-75f7cfd4f7-mnn8f 0/1 Pending 0 1s helloweb-75f7cfd4f7-mnn8f 0/1 Pending 0 1s helloweb-75f7cfd4f7-gz58p 0/1 Pending 0 0s helloweb-75f7cfd4f7-gz58p 0/1 Pending 0 0s helloweb-75f7cfd4f7-hhf62 0/1 Pending 0 0s helloweb-75f7cfd4f7-hhf62 0/1 Pending 0 0s helloweb-75f7cfd4f7-sng6f 0/1 Pending 0 0s helloweb-75f7cfd4f7-6j9sx 0/1 Pending 0 0s helloweb-75f7cfd4f7-sng6f 0/1 Pending 0 0s helloweb-75f7cfd4f7-6j9sx 0/1 Pending 0 0s helloweb-75f7cfd4f7-mnn8f 0/1 Pending 0 77s helloweb-75f7cfd4f7-gz58p 0/1 Pending 0 76s helloweb-75f7cfd4f7-hhf62 0/1 Pending 0 76s helloweb-75f7cfd4f7-sng6f 0/1 Pending 0 76s helloweb-75f7cfd4f7-6j9sx 0/1 Pending 0 76s helloweb-75f7cfd4f7-mnn8f 0/1 ContainerCreating 0 77s helloweb-75f7cfd4f7-gz58p 0/1 ContainerCreating 0 76s helloweb-75f7cfd4f7-hhf62 0/1 ContainerCreating 0 76s helloweb-75f7cfd4f7-sng6f 0/1 Pending 0 82s helloweb-75f7cfd4f7-6j9sx 0/1 Pending 0 82s helloweb-75f7cfd4f7-sng6f 0/1 ContainerCreating 0 82s helloweb-75f7cfd4f7-6j9sx 0/1 ContainerCreating 0 82s helloweb-75f7cfd4f7-mnn8f 1/1 Running 0 2m18s helloweb-75f7cfd4f7-gz58p 1/1 Running 0 2m20s helloweb-75f7cfd4f7-hhf62 1/1 Running 0 2m23s helloweb-75f7cfd4f7-sng6f 1/1 Running 0 2m25s helloweb-75f7cfd4f7-6j9sx 1/1 Running 0 2m30s
次に、ノードのスケールアウトが行われたかどうかを確認します。
ワークロードの Pod を実行するために 2つのノードが追加されていることがわかります。ノードの追加を待ってから Pod が起動されるため、ノードの追加待ち時間だけ Pod の起動に時間がかかってしまっています。
# ノードの数を確認する $ kubectl get nodes # 出力例 $ kubectl get nodes NAME STATUS ROLES AGE VERSION gk3-cluster-sasashun-gke-default-pool-69f9cf5d-m972 Ready <none> 79m v1.26.5-gke.1200 gk3-cluster-sasashun-gke-default-pool-b9c30e3b-z2jn Ready <none> 79m v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-5d602c8d-zwcp Ready <none> 2m29s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-ed49f4e8-cgbn Ready <none> 2m25s v1.26.5-gke.1200
Pod を削除し、ノードの数が元に戻るまで待機します。
# Pod を削除する $ kubectl delete -f test-deployment.yaml
# ノード数が元に戻ったことを確認 $ kubectl get nodes # 出力例 $ kubectl get nodes $ kubectl get nodes NAME STATUS ROLES AGE VERSION gk3-cluster-sasashun-gke-default-pool-69f9cf5d-m972 Ready <none> 85m v1.26.5-gke.1200 gk3-cluster-sasashun-gke-default-pool-b9c30e3b-z2jn Ready <none> 85m v1.26.5-gke.1200
一貫した容量のプロビジョニングを使用する
まず、一貫した容量のプロビジョニングを使用してみます。
この方法では、Deployment によってクラスタ上でプレースホルダ Pod が常に実行されるようにします。
PriorityClass オブジェクトを作成する
Pod に優先度を設定するために PriorityClass オブジェクトを作成します。
クラスタに priorityclasses.yaml を適用します。
# PriorityClass のマニフェストを適用する $ kubectl apply -f priorityclasses.yaml
プレースホルダ Pod をデプロイする
capacity-res-deployment.yaml をクラスタに適用し、プレースホルダ Pod を作成します。
プレースホルダ Pod が全て作成されるまで待機します。
# プレースホルダ Pod のマニフェストを適用する $ kubectl apply -f capacity-res-deployment.yaml
# プレースホルダ Pod のステータスを確認する $ kubectl get pods # 出力例 $ kubectl get pods NAME READY STATUS RESTARTS AGE capacity-res-deploy-74b9b79578-4cvms 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-85tgp 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-89qfz 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-8v2dh 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-d4kth 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-dvxrd 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-gvqcp 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-kdxzl 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-kxr4w 1/1 Running 0 2m43s capacity-res-deploy-74b9b79578-rzjvk 1/1 Running 0 2m43s
ノードの状態を確認すると、プレースホルダ Pod を作成するためにノードが追加されていることがわかります。
# ノードのスケールアウトを確認する $ kubectl get nodes # 出力例 $ kubectl get nodes NAME STATUS ROLES AGE VERSION gk3-cluster-sasashun-gke-default-pool-69f9cf5d-m972 Ready <none> 90m v1.26.5-gke.1200 gk3-cluster-sasashun-gke-default-pool-b9c30e3b-z2jn Ready <none> 90m v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-144d029c-fjgv Ready <none> 3m2s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-144d029c-q4xg Ready <none> 3m1s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-5d602c8d-p78l Ready <none> 2m59s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-ed49f4e8-67dq Ready <none> 3m1s v1.26.5-gke.1200
ワークロード用 Pod のデプロイ
ワークロード用の Pod をデプロイし、Pod の起動時間とプレースホルダ Pod の動作を確認します。
まず、Pod のステータスをモニタリングするために以下のコマンドを実行します。
# Pod のステータスをモニタリングする $ kubectl get pods -w
続いて、別のターミナルで test-deployment.yaml をクラスタに適用し、ワークロード用の Pod をデプロイします。
# ワークロード用 Pod のデプロイ(別のターミナルで実施) $ kubectl apply -f test-deployment.yaml
ワークロード用 Pod のマニフェストファイルを適用したあと Pod のステータスをモニタリングしているターミナルを確認すると、優先度が低く設定されているプレースホルダ Pod が削除され、代わりにワークロード用 Pod が作成されていることがわかります。
プレースホルダ Pod が事前にノード容量を確保しているため、ワークロード用 Pod は素早く作成されます。今回の検証では 15秒以内に全てのワークロード用 Pod が起動していることがわかります。
# 出力例 $ kubectl get pods -w NAME READY STATUS RESTARTS AGE capacity-res-deploy-74b9b79578-4cvms 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-85tgp 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-89qfz 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-8v2dh 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-d4kth 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-dvxrd 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-gvqcp 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-kdxzl 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-kxr4w 1/1 Running 0 6m19s capacity-res-deploy-74b9b79578-rzjvk 1/1 Running 0 6m19s helloweb-75f7cfd4f7-plv6r 0/1 Pending 0 0s helloweb-75f7cfd4f7-plv6r 0/1 Pending 0 0s helloweb-75f7cfd4f7-plv6r 0/1 ContainerCreating 0 0s helloweb-75f7cfd4f7-d8tdv 0/1 Pending 0 0s helloweb-75f7cfd4f7-lnbbh 0/1 Pending 0 0s helloweb-75f7cfd4f7-n67w5 0/1 Pending 0 1s helloweb-75f7cfd4f7-nwknn 0/1 Pending 0 1s capacity-res-deploy-74b9b79578-kdxzl 1/1 Running 0 6m51s capacity-res-deploy-74b9b79578-kdxzl 1/1 Terminating 0 6m51s capacity-res-deploy-74b9b79578-kdxzl 1/1 Terminating 0 6m51s helloweb-75f7cfd4f7-d8tdv 0/1 Pending 0 1s capacity-res-deploy-74b9b79578-fdmfl 0/1 Pending 0 0s capacity-res-deploy-74b9b79578-d4kth 1/1 Running 0 6m51s capacity-res-deploy-74b9b79578-d4kth 1/1 Terminating 0 6m51s capacity-res-deploy-74b9b79578-d4kth 1/1 Terminating 0 6m51s helloweb-75f7cfd4f7-lnbbh 0/1 Pending 0 1s capacity-res-deploy-74b9b79578-gvqcp 1/1 Running 0 6m51s capacity-res-deploy-74b9b79578-gvqcp 1/1 Terminating 0 6m51s capacity-res-deploy-74b9b79578-gvqcp 1/1 Terminating 0 6m51s capacity-res-deploy-74b9b79578-p48dn 0/1 Pending 0 0s helloweb-75f7cfd4f7-n67w5 0/1 Pending 0 1s capacity-res-deploy-74b9b79578-dvxrd 1/1 Running 0 6m51s capacity-res-deploy-74b9b79578-dvxrd 1/1 Terminating 0 6m51s capacity-res-deploy-74b9b79578-dvxrd 1/1 Terminating 0 6m51s capacity-res-deploy-74b9b79578-bq9bm 0/1 Pending 0 0s helloweb-75f7cfd4f7-nwknn 0/1 Pending 0 1s capacity-res-deploy-74b9b79578-fdmfl 0/1 Pending 0 0s capacity-res-deploy-74b9b79578-p48dn 0/1 Pending 0 0s capacity-res-deploy-74b9b79578-bq9bm 0/1 Pending 0 0s capacity-res-deploy-74b9b79578-55mx9 0/1 Pending 0 0s capacity-res-deploy-74b9b79578-55mx9 0/1 Pending 0 0s helloweb-75f7cfd4f7-lnbbh 0/1 Pending 0 3s helloweb-75f7cfd4f7-nwknn 0/1 Pending 0 3s helloweb-75f7cfd4f7-n67w5 0/1 Pending 0 3s helloweb-75f7cfd4f7-d8tdv 0/1 Pending 0 3s helloweb-75f7cfd4f7-lnbbh 0/1 ContainerCreating 0 3s helloweb-75f7cfd4f7-d8tdv 0/1 ContainerCreating 0 3s helloweb-75f7cfd4f7-nwknn 0/1 ContainerCreating 0 3s helloweb-75f7cfd4f7-n67w5 0/1 ContainerCreating 0 3s helloweb-75f7cfd4f7-plv6r 1/1 Running 0 11s helloweb-75f7cfd4f7-d8tdv 1/1 Running 0 12s helloweb-75f7cfd4f7-lnbbh 1/1 Running 0 13s helloweb-75f7cfd4f7-nwknn 1/1 Running 0 13s helloweb-75f7cfd4f7-n67w5 1/1 Running 0 14s
さらにしばらく待機すると、Deployment に設定されたプレースホルダ Pod の数を維持するために新たなプレースホルダ Pod が作成されます。
# 出力例 $ kubectl get pods NAME READY STATUS RESTARTS AGE capacity-res-deploy-74b9b79578-4cvms 1/1 Running 0 8m53s capacity-res-deploy-74b9b79578-55mx9 1/1 Running 0 2m2s capacity-res-deploy-74b9b79578-85tgp 1/1 Running 0 8m53s capacity-res-deploy-74b9b79578-89qfz 1/1 Running 0 8m53s capacity-res-deploy-74b9b79578-8v2dh 1/1 Running 0 8m53s capacity-res-deploy-74b9b79578-bq9bm 1/1 Running 0 2m2s capacity-res-deploy-74b9b79578-fdmfl 1/1 Running 0 2m2s capacity-res-deploy-74b9b79578-kxr4w 1/1 Running 0 8m53s capacity-res-deploy-74b9b79578-p48dn 1/1 Running 0 2m2s capacity-res-deploy-74b9b79578-rzjvk 1/1 Running 0 8m53s helloweb-75f7cfd4f7-d8tdv 1/1 Running 0 2m3s helloweb-75f7cfd4f7-lnbbh 1/1 Running 0 2m3s helloweb-75f7cfd4f7-n67w5 1/1 Running 0 2m3s helloweb-75f7cfd4f7-nwknn 1/1 Running 0 2m3s helloweb-75f7cfd4f7-plv6r 1/1 Running 0 2m3s
ノードの状態を確認すると、置き換えられたぶんのプレースホルダ Pod を実行するために、ノードが追加されていることがわかります。
このように、一貫した容量のプロビジョニングを使用する場合、プレースホルダ Pod 用の容量が常に確保されることになります。
# 出力例 $ kubectl get nodes NAME STATUS ROLES AGE VERSION gk3-cluster-sasashun-gke-default-pool-69f9cf5d-m972 Ready <none> 95m v1.26.5-gke.1200 gk3-cluster-sasashun-gke-default-pool-b9c30e3b-z2jn Ready <none> 95m v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-144d029c-fjgv Ready <none> 8m16s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-144d029c-q4xg Ready <none> 8m15s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-5d602c8d-p78l Ready <none> 8m13s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-ed49f4e8-67dq Ready <none> 8m15s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-2-af991da7-cq9c Ready <none> 86s v1.26.5-gke.1200
単一イベント容量のプロビジョニングを使用する
最後に、単一イベント容量のプロビジョニングを使用して ワークロード用 Pod をデプロイします。
当記事ではクラスタの状態を初期化するために一度クラスタを削除し、再作成しています。
ノードの初期状態を確認する
クラスタを再作成したため、まずはノードの初期状態を確認します。
# ノードの状態を確認 $ kubectl get nodes # 出力例 $ kubectl get nodes NAME STATUS ROLES AGE VERSION gk3-cluster-sasashun-gke-default-pool-76ea9d98-xj4v Ready <none> 99s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-default-pool-d830f363-f5bt Ready <none> 98s v1.26.5-gke.1200
PriorityClass オブジェクトを作成する
改めて priorityclasses.yaml を適用し、PriorityClass を作成します。
# PriorityClass のマニフェストを適用する $ kubectl apply -f priorityclasses.yaml
プレースホルダ Pod をデプロイする
capacity-res-job.yaml をクラスタに適用し、プレースホルダ Pod を実行する Job を作成します。
プレースホルダ Pod が全て作成されるまで待機します。
# プレースホルダ Job のマニフェストを適用する $ kubectl apply -f capacity-res-job.yaml
# ジョブのステータスを確認する $ kubectl get jobs # 出力例 $ kubectl get jobs NAME COMPLETIONS DURATION AGE capacity-res-job 0/1 of 10 114s 114s
# Job で起動されたプレースホルダ Pod を確認する $ kubectl get pods # 出力例 $ kubectl get pods NAME READY STATUS RESTARTS AGE capacity-res-job-fc8v2 1/1 Running 0 3m4s capacity-res-job-g56jm 1/1 Running 0 3m4s capacity-res-job-ks6j7 1/1 Running 0 3m3s capacity-res-job-lzpqk 1/1 Running 0 3m4s capacity-res-job-n9w6p 1/1 Running 0 3m4s capacity-res-job-nsmks 1/1 Running 0 3m3s capacity-res-job-ph5cp 1/1 Running 0 3m3s capacity-res-job-rh8cq 1/1 Running 0 3m3s capacity-res-job-t7h4t 1/1 Running 0 3m3s capacity-res-job-zxgg4 1/1 Running 0 3m3s
ノードの状態を確認すると、プレースホルダ Pod を作成するためにノードが追加されていることがわかります。
# ノードのスケールアウトを確認する $ kubectl get nodes # 出力例 $ kubectl get nodes NAME STATUS ROLES AGE VERSION gk3-cluster-sasashun-gke-default-pool-76ea9d98-xj4v Ready <none> 6m7s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-default-pool-d830f363-f5bt Ready <none> 6m6s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-1dc5c9f6-6g97 Ready <none> 2m17s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-1dc5c9f6-fl7d Ready <none> 2m16s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-4d328f57-bm4l Ready <none> 2m19s v1.26.5-gke.1200 gk3-cluster-sasashun-gke-publi-pool-1-b29f6e44-xkhk Ready <none> 2m19s v1.26.5-gke.1200
ワークロード用 Pod のデプロイ
ワークロード用の Pod をデプロイし、Pod の起動時間とプレースホルダ Pod の動作を確認します。
まず、Pod のステータスをモニタリングするために以下のコマンドを実行します。
# Pod のステータスをモニタリングする $ kubectl get pods -w
続いて、別のターミナルで test-deployment.yaml をクラスタに適用し、ワークロード用の Pod をデプロイします。
# ワークロード用 Pod のデプロイ(別のターミナルで実施) $ kubectl apply -f test-deployment.yaml
Job によってプレースホルダ Pod がノード容量を確保しているため、ワークロード用 Pod は素早く作成されます。今回も 15秒以内に全てのワークロード用 Pod が起動していることがわかります。
# 出力例 $ kubectl get pods -w NAME READY STATUS RESTARTS AGE capacity-res-job-fc8v2 1/1 Running 0 3m47s capacity-res-job-g56jm 1/1 Running 0 3m47s capacity-res-job-ks6j7 1/1 Running 0 3m46s capacity-res-job-lzpqk 1/1 Running 0 3m47s capacity-res-job-n9w6p 1/1 Running 0 3m47s capacity-res-job-nsmks 1/1 Running 0 3m46s capacity-res-job-ph5cp 1/1 Running 0 3m46s capacity-res-job-rh8cq 1/1 Running 0 3m46s capacity-res-job-t7h4t 1/1 Running 0 3m46s capacity-res-job-zxgg4 1/1 Running 0 3m46s helloweb-75f7cfd4f7-rvh8w 0/1 Pending 0 0s helloweb-75f7cfd4f7-rvh8w 0/1 Pending 0 0s helloweb-75f7cfd4f7-rvh8w 0/1 ContainerCreating 0 0s helloweb-75f7cfd4f7-6wq75 0/1 Pending 0 0s helloweb-75f7cfd4f7-2wblr 0/1 Pending 0 0s helloweb-75f7cfd4f7-5wjvd 0/1 Pending 0 1s helloweb-75f7cfd4f7-llkfh 0/1 Pending 0 1s capacity-res-job-zxgg4 1/1 Running 0 4m7s capacity-res-job-zxgg4 1/1 Terminating 0 4m7s helloweb-75f7cfd4f7-6wq75 0/1 Pending 0 1s capacity-res-job-ph5cp 1/1 Running 0 4m7s capacity-res-job-zxgg4 1/1 Terminating 0 4m7s capacity-res-job-ph5cp 1/1 Terminating 0 4m7s helloweb-75f7cfd4f7-2wblr 0/1 Pending 0 1s capacity-res-job-ph5cp 1/1 Terminating 0 4m7s capacity-res-job-rh8cq 1/1 Running 0 4m7s capacity-res-job-rh8cq 1/1 Terminating 0 4m7s helloweb-75f7cfd4f7-5wjvd 0/1 Pending 0 1s capacity-res-job-fc8v2 1/1 Running 0 4m8s capacity-res-job-fc8v2 1/1 Terminating 0 4m8s capacity-res-job-rh8cq 1/1 Terminating 0 4m7s helloweb-75f7cfd4f7-llkfh 0/1 Pending 0 1s capacity-res-job-fc8v2 1/1 Terminating 0 4m8s capacity-res-job-n9w6p 1/1 Terminating 0 4m9s capacity-res-job-g56jm 1/1 Terminating 0 4m9s capacity-res-job-nsmks 1/1 Terminating 0 4m8s capacity-res-job-ks6j7 1/1 Terminating 0 4m8s capacity-res-job-t7h4t 1/1 Terminating 0 4m8s capacity-res-job-lzpqk 1/1 Terminating 0 4m9s capacity-res-job-t7h4t 1/1 Terminating 0 4m8s capacity-res-job-nsmks 1/1 Terminating 0 4m8s capacity-res-job-zxgg4 1/1 Terminating 0 4m8s capacity-res-job-ks6j7 1/1 Terminating 0 4m8s capacity-res-job-ph5cp 1/1 Terminating 0 4m8s capacity-res-job-n9w6p 1/1 Terminating 0 4m9s capacity-res-job-g56jm 1/1 Terminating 0 4m9s capacity-res-job-fc8v2 1/1 Terminating 0 4m9s helloweb-75f7cfd4f7-llkfh 0/1 Pending 0 2s helloweb-75f7cfd4f7-6wq75 0/1 Pending 0 2s helloweb-75f7cfd4f7-2wblr 0/1 Pending 0 2s helloweb-75f7cfd4f7-5wjvd 0/1 Pending 0 2s capacity-res-job-rh8cq 1/1 Terminating 0 4m8s capacity-res-job-lzpqk 1/1 Terminating 0 4m9s helloweb-75f7cfd4f7-5wjvd 0/1 ContainerCreating 0 2s helloweb-75f7cfd4f7-llkfh 0/1 ContainerCreating 0 2s helloweb-75f7cfd4f7-6wq75 0/1 ContainerCreating 0 2s helloweb-75f7cfd4f7-2wblr 0/1 ContainerCreating 0 2s helloweb-75f7cfd4f7-rvh8w 1/1 Running 0 9s helloweb-75f7cfd4f7-2wblr 1/1 Running 0 9s helloweb-75f7cfd4f7-6wq75 1/1 Running 0 10s helloweb-75f7cfd4f7-5wjvd 1/1 Running 0 12s helloweb-75f7cfd4f7-llkfh 1/1 Running 0 13s
また、Job から作成された優先度の低いプレースホルダ Pod はすべて削除されています。
このように、Job を使用する場合は、置き換えが起こった後にプレースホルダ Pod を再作成するための容量が確保されないため、使用リソースを節約できる反面、再度スケールアウトが必要になったときに対応することができなくなります。
# 出力例 $ kubectl get po NAME READY STATUS RESTARTS AGE helloweb-75f7cfd4f7-2wblr 1/1 Running 0 3m10s helloweb-75f7cfd4f7-6wq75 1/1 Running 0 3m10s helloweb-75f7cfd4f7-cclwt 1/1 Running 0 2m helloweb-75f7cfd4f7-kw7t5 1/1 Running 0 2m helloweb-75f7cfd4f7-rvh8w 1/1 Running 0 3m10s
佐々木 駿太 (記事一覧)
G-gen 最北端、北海道在住のクラウドソリューション部エンジニア
2022年6月に G-gen にジョイン。Google Cloud Partner Top Engineer に選出(2024 / 2025 Fellow / 2026)。好きな Google Cloud プロダクトは Cloud Run。
趣味はコーヒー、小説(SF、ミステリ)、カラオケなど。
Follow @sasashun0805