


G-gen の福井です。当記事では、Cloud Run 上で動作する Python アプリケーションのパフォーマンス分析に焦点を当て、Google Cloud の Cloud Trace を用いてリクエスト処理のボトルネックを特定・可視化する手順を紹介します。

はじめに
Cloud Trace とは
Cloud Trace は、Google Cloud が提供する分散トレーシングシステムです。アプリケーションに対するリクエストが、システム内の複数のサービスやコンポーネントをどのように経由していくかを追跡し、各処理ステップでのレイテンシ(遅延時間)を収集・可視化します。特にマイクロサービスアーキテクチャのように、一つのリクエストが複数のサービスにまたがる場合に、パフォーマンスのボトルネックを特定するのに役立ちます。
- 参考: Cloud Trace の概要
Cloud Trace を理解する上で重要な、以下の基本概念について説明します。
トレースとスパン
トレース(Trace)は、特定のリクエストがアプリケーション内で一連の処理を完了するまでの全体の流れを示すものです。このトレースは、一つ以上の「スパン」から構成されます。
スパン(Span)は、トレース内で行われる個々の作業単位を表します。例えば、特定の関数呼び出し、外部 API へのリクエスト、データベースクエリなどが一つのスパンに対応します。各スパンは、開始時刻、終了時刻、名前、一意の ID、そして親子関係を示す情報(どのスパンから呼び出されたか)などを持ちます。トレース全体を包含する最初のスパンをルートスパンと呼びます。
- 参考: トレースとスパン
トレースコンテキスト
分散システムにおいて、リクエストがサービス境界を越えて伝播する際に、トレース情報をどのように引き継ぐかが重要です。トレースコンテキスト(Trace Context) は、このトレース ID や現在のスパン ID などの情報をサービス間で伝播させるための標準化された方法です。一般的には、HTTP ヘッダー(例: traceparent)などを用いて情報を伝達します。これにより、複数のサービスにまたがる処理を単一のトレースとして正しく紐付けることができます。
- 参考: トレース コンテキスト
サンプリング
常にすべてのリクエストのトレースデータを収集すると、特に高トラフィックなシステムでは、データ量やパフォーマンスへのオーバーヘッド、コストが大きくなる可能性があります。そのため、サンプリング(Sampling)という手法を用います。これは、一定の割合のリクエストのみをトレース対象とする仕組みです。
Cloud Trace は、計装ライブラリ(今回使用する OpenTelemetry など)と連携し、設定されたサンプリングレートに基づいてトレースデータを収集します。どのようなサンプリング戦略(常にサンプリングする、一定割合でサンプリングする、など)を取るかは、アプリケーション側で設定します。
- 参考: トレース サンプリング
事前準備
Cloud Trace API の有効化
アプリケーションがトレースデータを Google Cloud に送信するためには、プロジェクトで Cloud Trace API を有効にする必要があります。
gcloud services enable cloudtrace.googleapis.com
- 参考: Cloud Trace の設定
サービスアカウントの作成とロールを付与
以下の gcloud コマンドを順次実行します。
なお、以下のコマンド内で使用されている環境変数 PROJECT_ID の your-project-id の部分は、ご自身の Google Cloud プロジェクト ID に置き換えてください。
# 環境変数の設定 PROJECT_ID=your-project-id SA_NAME=sv-cloud-trace-demo-app # サービスアカウント作成 gcloud iam service-accounts create $SA_NAME \ --description="Cloud TraceでCloud Runの処理時間を計測するサービスアカウント" \ --display-name="Cloud TraceでCloud Runの処理時間を計測するサービスアカウント" # サービスアカウントへ権限付与 gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SA_NAME@$PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/cloudtrace.agent" gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SA_NAME@$PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/logging.logWriter"
アプリケーションへのトレース実装
Python アプリケーションにトレースデータを収集・送信するコードを追加します。ここでは、テレメトリデータ(トレース、メトリクス、ログ)を生成・収集するためのオープンソースのオブザーバビリティフレームワークである OpenTelemetry を使用します。
ディレクトリ構成
今回開発する Python アプリケーションのディレクトリ構成は以下のとおりです。
cloud-trace-demo-app |-- main.py |-- requirements.txt |-- Dockerfile
必要なライブラリのインストール
OpenTelemetry 関連の Python ライブラリをアプリケーションの依存関係に追加します。
requirements.txt
# Webフレームワーク flask>=2.0 # OpenTelemetry Core opentelemetry-api==1.32.1 opentelemetry-sdk==1.32.1 # Cloud Trace Exporter opentelemetry-exporter-gcp-trace==1.9.0 # Automatic Instrumentation opentelemetry-instrumentation-flask==0.53b1 opentelemetry-instrumentation-requests==0.53b1 # Logging opentelemetry-instrumentation-logging==0.53b1 google-cloud-logging==3.12.1
OpenTelemetry の設定と使用
アプリケーションコードに OpenTelemetry の設定と、トレース(スパン)生成のための実装を追加します。
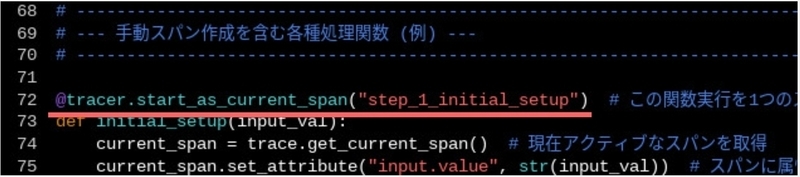
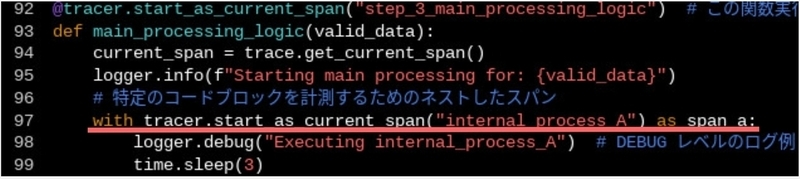
以下は、Flask アプリケーションに、OpenTelemetry の初期化、自動計装の適用、および手動でのスパン作成を組み込んでいます。
main.py
import logging import time import google.cloud.logging import requests from flask import Flask from opentelemetry import trace from opentelemetry.exporter.cloud_trace import CloudTraceSpanExporter # OpenTelemetry 自動計装ライブラリ from opentelemetry.instrumentation.flask import FlaskInstrumentor from opentelemetry.instrumentation.logging import LoggingInstrumentor from opentelemetry.instrumentation.requests import RequestsInstrumentor # OpenTelemetry SDK コンポーネント from opentelemetry.sdk.resources import Resource from opentelemetry.sdk.trace import TracerProvider from opentelemetry.sdk.trace.export import BatchSpanProcessor # -------------------------------------------------------------------------------- # --- OpenTelemetry SDK の初期化と設定 # -------------------------------------------------------------------------------- # リソースの定義: トレースに紐付けるサービス名などを設定 resource = Resource(attributes={"service.name": "my-python-cloudrun-service"}) # TracerProviderの作成: リソース情報を紐付け provider = TracerProvider(resource=resource) # CloudTraceSpanExporterの作成: トレースデータを Google Cloud Trace に送信 trace_exporter = CloudTraceSpanExporter(resource_regex="^service\.name$") # BatchSpanProcessorの作成: スパンをまとめて効率的にエクスポート trace_processor = BatchSpanProcessor(trace_exporter) provider.add_span_processor(trace_processor) # グローバルなTracerProviderとして設定: アプリケーション全体で使用可能に trace.set_tracer_provider(provider) # -------------------------------------------------------------------------------- # --- Python標準loggingとOpenTelemetry Logging計装の設定 # -------------------------------------------------------------------------------- # LoggingInstrumentorの有効化: ログレコードにトレースID/スパンIDを自動付加 # set_logging_format=True で、ログ形式にトレース情報が追加される LoggingInstrumentor().instrument(set_logging_format=True) # Google Cloud Logging クライアントの初期化と設定 client = google.cloud.logging.Client() client.setup_logging(log_level=logging.INFO) logger = logging.getLogger(__name__) # -------------------------------------------------------------------------------- # --- OpenTelemetry Tracer の取得 # -------------------------------------------------------------------------------- # アプリケーションコード内で手動スパンを作成するためにTracerを取得 tracer = trace.get_tracer(__name__) # -------------------------------------------------------------------------------- # --- Flaskアプリケーションの初期化と自動計装 # -------------------------------------------------------------------------------- app = Flask(__name__) # FlaskInstrumentorの適用: Flaskリクエストの自動トレース FlaskInstrumentor().instrument_app(app) # RequestsInstrumentorの適用: requestsライブラリによるHTTPコールの自動トレース RequestsInstrumentor().instrument() # -------------------------------------------------------------------------------- # --- 手動スパン作成を含む各種処理関数 (例) # -------------------------------------------------------------------------------- @tracer.start_as_current_span("step_1_initial_setup") # この関数実行を1つのスパンとして計測 def initial_setup(input_val): current_span = trace.get_current_span() # 現在アクティブなスパンを取得 current_span.set_attribute("input.value", str(input_val)) # スパンに属性を追加 logger.info( f"Executing initial_setup for: {input_val}", extra={"json_fields": {"tags": ["setup"], "input_data": input_val}}, ) time.sleep(1) result = f"Setup_{input_val}" current_span.set_attribute("output.value", result) return result @tracer.start_as_current_span("step_2_data_validation") # この関数実行を1つのスパンとして計測 def validate_data(data_to_validate): time.sleep(2) return len(data_to_validate) > 3 @tracer.start_as_current_span("step_3_main_processing_logic") # この関数実行を1つのスパンとして計測 def main_processing_logic(valid_data): current_span = trace.get_current_span() logger.info(f"Starting main processing for: {valid_data}") # 特定のコードブロックを計測するためのネストしたスパン with tracer.start_as_current_span("internal_process_A") as span_a: logger.debug("Executing internal_process_A") # DEBUG レベルのログ例 time.sleep(3) result_a = "Result_A_from_main_processing" span_a.set_attribute("process_a.status", "completed") # 別のコードブロックを計測するためのネストしたスパン (外部呼び出しを含む) with tracer.start_as_current_span("call_dependent_microservice") as span_b: logger.info("Calling dependent microservice (simulated via httpbin)") # このrequests呼び出しはRequestsInstrumentorにより自動トレースされる response = requests.get("https://httpbin.org/get?service_call=true", params={"id": "internal_B"}) span_b.set_attribute("http.status_code", response.status_code) result_b = response.json().get("args", {}) logger.info("Dependent microservice call successful, args: %s", result_b) final_result = f"{result_a} & {result_b}" current_span.set_attribute("final_result.summary", final_result[:30]) logger.info("Main processing completed.") return final_result @tracer.start_as_current_span("step_4_skip") # この関数実行を1つのスパンとして計測 def skip_loggic(): pass @tracer.start_as_current_span("step_5_final_aggregation") # この関数実行を1つのスパンとして計測 def final_aggregation(data_from_main): current_span = trace.get_current_span() logger.info("Aggregating final results.") time.sleep(5) aggregated_result = {"main_output": data_from_main} current_span.set_attribute("aggregation.items_count", 2) logger.info( "Final aggregation complete.", extra={"json_fields": {"aggregated_keys": list(aggregated_result.keys())}} ) return aggregated_result # -------------------------------------------------------------------------------- # --- Flask ルート定義 # -------------------------------------------------------------------------------- @app.route("/") def main_request_handler(): # このリクエスト処理全体を包括する親スパンを手動で作成 with tracer.start_as_current_span("main_request_flow") as parent_span: parent_span.set_attribute("http.request.path", "/") # スパンの属性にリクエストパスを追加 parent_span.set_attribute("user.id", "example_user_123") # スパンの属性にユーザー情報を追加 logger.info("Main request handler started for user: %s", "example_user_123") # step_1 setup_result = initial_setup("Request_Payload_Data") # step_2 is_data_valid = validate_data(setup_result) # step_3 main_processed_data = main_processing_logic(setup_result) if is_data_valid: parent_span.add_event("DataValidationSkipped", {"reason": "Invalid data"}) logger.warning("processing skipped due to invalid data.") else: # step_4 skip_loggic() # step_5 final_output = final_aggregation(main_processed_data) parent_span.set_attribute("response.content_type", "application/json") logger.info("Main request handler completed successfully.") return final_output # -------------------------------------------------------------------------------- # --- アプリケーション起動 # -------------------------------------------------------------------------------- if __name__ == "__main__": app.run(debug=True, host="0.0.0.0", port=7860)
Cloud Run へのデプロイ
Dockerfile の準備
アプリケーションをコンテナ化するための Dockerfile を作成します。
Dockerfile
FROM python:3.12-slim WORKDIR /usr/src/app COPY requirements.txt ./ RUN pip install --no-cache-dir -r requirements.txt COPY . . EXPOSE 7860 CMD [ "python", "./main.py" ]
Cloud Run にデプロイ
Dockerfile が存在するディレクトリで、以下の gcloud コマンドを順次実行します。
なお、以下のコマンド内で使用されている環境変数 PROJECT_ID の your-project-id の部分は、ご自身の Google Cloud プロジェクト ID に置き換えてください。
# 環境変数の設定 PROJECT_ID=your-project-id REGION=asia-northeast1 SA_NAME=sv-cloud-trace-demo-app # Cloud Run サービスをデプロイ gcloud run deploy cloud-trace-demo-app --source . \ --region=asia-northeast1 \ --allow-unauthenticated \ --port 7860 \ --memory=1Gi \ --min-instances=0 \ --max-instances=1 \ --service-account=$SA_NAME@$PROJECT_ID.iam.gserviceaccount.com \ --set-env-vars=PROJECT_ID=$PROJECT_ID,LOCATION=$REGION
動作確認
Cloud Run のデプロイが完了すると、標準出力に Cloud Run のエンドポイントが Service URL として出力されます。この URL に、ブラウザからアクセスします。
$ gcloud run deploy cloud-trace-demo-app --source . \ --region=asia-northeast1 \ --allow-unauthenticated \ --port 7860 \ --memory=1Gi \ --min-instances=0 \ --max-instances=1 \ --service-account=$SA_NAME@$PROJECT_ID.iam.gserviceaccount.com \ --set-env-vars=PROJECT_ID=$PROJECT_ID,LOCATION=$REGION Building using Dockerfile and deploying container to Cloud Run service [cloud-trace-demo-app] in project [your-project-id] region [asia-northeast1] \ Building and deploying... Uploading sources. \ Uploading sources... OK Building and deploying... Done. OK Uploading sources... OK Building Container... Logs are available at ・・・ OK Creating Revision... OK Routing traffic... OK Setting IAM Policy... Done. Service [cloud-trace-demo-app] revision [cloud-trace-demo-app-00003-tdv] has been deployed and is serving 100 percent of traffic. Service URL: https://cloud-trace-demo-app-XXXXXXXX.asia-northeast1.run.app
アクセスすると、以下の画面が表示されます。

Cloud Trace で処理時間を確認
トレースリストの表示
Google Cloud コンソールの Cloud Trace エクスプローラ画面を表示します。 以下の画面は、Cloud Run アプリケーションへ連続して数回アクセスした後の画面です。

トレースリストの見方
サービス名(①)
プログラムで指定したサービス名で、関連するスパンを絞り込めます。

プログラムで指定したスパン名で、関連するスパンを絞り込めます。
ヒートマップでスパンの実行時間や処理時間を可視化し、一覧でスパン詳細を確認できます。
パフォーマンスのボトルネックを特定
- ヒートマップでは、処理時間が長いスパンが上に表示され、呼び出し数が多いと色が濃く表示されます。ヒートマップ上で対象を選択するとスパン一覧が絞り込まれ、パフォーマンスのボトルネックとなっているリクエストを特定できます。
- スパン一覧では、スパンごとに処理時間(列:期間)が表示されているため、処理時間の降順で並び替えることで、リクエスト内のより詳細なパフォーマンスのボトルネックとなっている箇所を特定できます。
トレース詳細の表示
トレースリストのスパン一覧からスパン ID のリンクを選択し、トレース詳細画面を表示します。
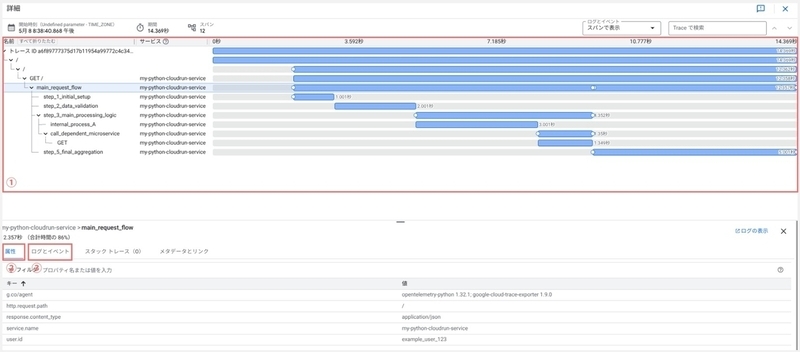
トレース詳細の見方
タイムライン(①)
トレース(単一のリクエスト)内における全スパンの実行の流れを時系列で示したものです。それぞれの横棒が個々のスパンを表し、棒の左端が処理の開始時刻、右端が終了時刻を示し、その長さが処理時間(レイテンシ)を意味します。スパンは親子関係に基づいて階層的に構成され、呼び出し元のスパンの下に、呼び出された処理のスパンがインデントされて表示されます。リクエスト全体の処理時間は、一番上に位置するルートスパンの長さとして示されます。
属性(②)
タイムライン上のスパンを選択すると、選択したスパンに紐づくプログラムで指定したキーと値の属性情報が表示されます。

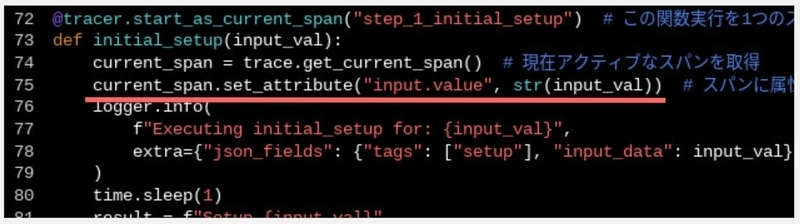
タイムライン上のスパンを選択すると、選択したスパンに紐づくプログラムで出力した Cloud Logging のログ情報が表示されます。

福井 達也(記事一覧)
カスタマーサクセス課 エンジニア
2024年2月 G-gen JOIN
元はアプリケーションエンジニア(インフラはAWS)として、PM/PL・上流工程を担当。G-genのGoogle Cloudへの熱量、Google Cloudの魅力を味わいながら日々精進