


G-genの佐伯です。当記事では、Vertex AIのAutoML及びバッチ予測の基本的な操作方法を解説しながら、簡易的で且つ安価に予測データを収集できる手法を解説できればと考えます。前編では、Vertex AIのAutoML及びバッチ予測の基本的な操作方法を解説させていただきます。
Vertex AI AutoML とは
AIのモデル作成は、高度なデータサイエンスの知識・経験が必要ですが、Vertex AI AutoMLを使用すれば、トレーニングデータをアップロードするだけで自動的に機械学習モデルを構築することができます。
Vertex AIのAutoMLやバッチ予測は、誰でも簡易的にモデル作成や予測が行え、 最近ですとAutoMLがモデル構築において、その手法(学習及びトレーニングを行っているのかの過程)を 知ることもできる機能がリリースされるなど、機械学習初学者にも利便性の高いものであります。 機械学習をこれから学習したいや概要を掴みたいなどの初学者には、特に有用性が高いと考えます。
(参考)Vertex AIの概要

また、以下の4つのデータを取り扱うことが出来ます。
- 画像データ
- 表形式データ
- テキストデータ
- 動画データ
当記事で行う検証作業
検証作業内容
パブリックドメインとなっている [Adult Census Income]をトレーニングデータとして、
『所得:income(ターゲット)』とある個人に関する様々な情報(年齢、職業、結婚歴など)との相関性を調べ、AutoMLでモデルを作成します。
そのモデルを用いて年収($50,000よりも高いかどうか)を予測して行きます。
今回のトレーニングデータについて
モデルの作成に使用するトレーニングデータとして、パブリックドメインとなっている Adult Census Income を使用しています。形式は csv です。
このデータは米国の国勢調査局のデータベースから抽出されたものであり、ある個人に関する様々な情報(年齢、職業、結婚歴など)と「年収(income)が$50,000よりも高いか、$50,000以下か」が記録されています。
データの前処理
トレーニングデータのAdult Census Incomeのセル中に『'?'』が含まれているため、これを以下のコードで事前に削除しておきます。
また、トレーニングデータを(モデルに与えて)予測用(pred_data.csv)と答え合わせ用(pred_answer.csv)に便宜上分割します。
import pandas as pd from sklearn.model_selection import train_test_split # データ読み込み df = pd.read_csv('/home/saikio/SRC/Vertex_AI/adult.csv') # ?を含む行を削除 drop_index = [] for column in ['workclass', 'occupation', 'native.country']: drop_index.extend(df.loc[df[column] == '?'].index.values) drop_index = sorted(set(drop_index)) df2 = df.drop(index=drop_index) # 学習に使用するデータ(train)とモデルに予測させるデータ(test)に分ける train, test = train_test_split(df2, test_size=0.01, random_state=0) # testを使ってincomeを予測したときの正解率を見たいので、incomeは分離しておく pred_data = test.drop('income', axis=1) pred_answer = test['income'] # それぞれCSVファイルに出力 train.to_csv('/home/saikio/SRC/Vertex_AI/train.csv', index=False) # トレーニング用のデータ pred_data.to_csv('/home/saikio/SRC/Vertex_AI/pred_data.csv', index=False) # テストの際にモデルに与えるデータ pred_answer.to_csv('/home/saikio/SRC/Vertex_AI/pred_answer.csv', index=False) # テストの正解データ(※後で不要になる)
上記のコードは、作成時のものから一部抜粋したものになります。
作業の主な流れ
今回私が実施した全体的な操作の流れは、以下の3点になります。
1. 対象となるデータをデータセットに登録する
2. データセットを指定してAutoMLの学習処理を実行する
3. 学習済みモデルを使ってバッチ予測を行う
対象となるデータをデータセットに登録する
次に対象となるデータの選択を行います。
今回はターゲット列の予測を行いたいので、
タブ『表形式』⇛『回帰/分類』を選択

データセットが作成されます。
次にトレーニングでどのデータと紐つけるかを選択します。
※今回は事前にCloud Storageにトレーニング用データを用意していましたので、
こちらを選択

データセットが作成されたことを確認。

データセットを指定してAutoMLの学習処理を実行する
①Vertex AIのダッシュボードから『トレーニング』⇛『作成』をクリック

②トレーニング方法
以下の手順で選択
Dataset:先程作成したデータセット
Objective:Classification(今回は分類が対象)
Model training method:AutoML

③モデルの詳細(トレーニングの作成と目的変数の設定)
Vertex AIでは新規に学習をするほかに、既存の学習済みモデルの新しいバージョンを作成できます。
これはデータを更新して新しいモデルを作成する際など、モデルを更新しつつ旧バージョンも残しておくのに最適です。

Vertex AIでデータセットを利用する際には、学習時に自動的にtrain, valid, testの3つのデータに分割されます。 保存先は以下になります。
Cloud Storage
BigQuery
(『Export test dataset to BigQuery』にチェックを入れて出力先を設定する必要はあります)
③トレーニングオプション
ここでは説明変数に関する設定を行います。 各列の項目にチェックを入れることで、その列を利用します。 また、データの型を明示的に設定することも可能です。

④コンピュートと料金
「コンピューティングと料金」で最大でどのくらい学習を行うかの設定をします。 ここで設定した値が最大で発生する料金となります。 AutoMLでは精度向上のための様々な学習が行われますが、 より精度が向上する余地があってもここで設定したノード時間で処理を中断させることで結果とコストのトレードオフをユーザが設定できます。
この設定は"最大"ノード時間となっています。 「早期停止を有効にする」オプションを有効にすることで、これ以上の向上が見込めないと判断された場合は途中で処理を終了することが可能なため、余分なコストは発生しません。

⑤モデル作成完了
モデルが作成されると推論が可能になります。 自分が作成したモデルの場合、作成時間は2時間 17分で作成料金は3017円となりました。
また、モデル作成完了時にはメールで完了メッセージも送信されます。 時間単位での課金ではない点は、ご注意ください。

Model Registory
Model Registryに登録されたものはバージョンごとに学習済みモデルのファイルの他、学習時の情報や推論の際に利用するコンテナに関する情報が含まれています。

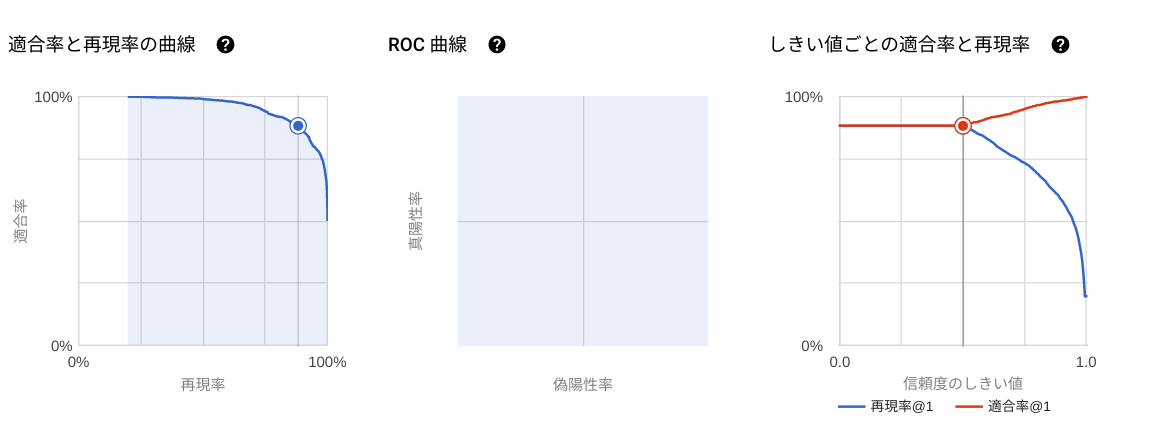
事例:信頼度50%を超えると、再現率と適合率の乖離が大きくなる。
推論手法
推論方法については、以下の2点があります。
1. エンドポイント作成(リアルタイム処理の場合に最適)
2. バッチ予測 (大量のデータに対してまとめて推論する場合に最適)
今回は、リアルタイム処理は必要ない為、バッチ予測を用いた方法をご紹介します。
バッチ予測
「バッチ予測の定義」では利用するモデルと入出力先の情報を設定します。 入力・出力はそれぞれBigQueryかCloud Storageを設定できます。
今回は以下の手順で設定します。
・モデル名(上記で作成したモデル名を指定)
・推論用データ元のリソース指定:Cloud Storage
・推論用データ(Cloud Storage内で作成したvertex_ai_test/pred_data.csvファイルを指定)
・出力先のリソース指定:Cloud Storage
・推論出力先のCloud Storage(Cloud Storage内で作成したvertex_ai_testのバケット)

「モデルのモニタリング」では、特徴量が学習時と異なる場合に検出する設定が可能です。 オプショナルとなるため、今回は割愛しています。
「バッチ予測の定義」及び「モデルのモニタリング」の内容が、よければ『作成』ボタンを押し処理開始。

バッチ推論が完了すると、メールで終了の連絡が送信されます。
今回はCloud Storageを選択した為、複数ファイルに分割されていることが確認できます。 以下はCSV形式でCloud Storageに出力した結果です。多くの推論結果がcsvファイル形式で出力されています。

推論データの結果確認
CSV形式でCloud Storageに出力した結果です。 入力に使ったデータの各行の最後に推論結果(黄色でのマーキング箇所)が付与されているのが確認できます。

まとめ
今回は、Vertex AIのAuto MLを使用してバッチ予測を行う基本的な手法を行いました。
初心者にも大変使いやすい機能ですので、機械学習初学者の方やVertex AIを初めて使用される方の手助けになれば、幸いです。
後編では、今回作成した予測済みモデルとdockerを使用して
予測データを取得する方法をご紹介できればと思います。
佐伯 修 (記事一覧)
クラウドソリューション部
前職では不動産業でバックエンドを経験し、2022年12月G-genにジョイン。
入社後、Google Cloudを触り始め、日々スキル向上を図る。
SEの傍ら、農業にも従事。水耕を主にとする。