


当記事は みずほリサーチ&テクノロジーズ × G-gen エンジニアコラボレーション企画 で執筆されたものです。
みずほリサーチ&テクノロジーズ株式会社の藤根です。この度、G-gen さんとのコラボを通じて、弊社エンジニアによる Google Cloud の記事を執筆する機会をいただきました。
本記事では、Google Cloud が誇る BigQuery について、初学者を対象にご紹介させていただきます。
先行して弊社小野寺より AWS アーキテクトがはじめて Google Cloud で静的 Web ページを配信した話も公開しておりますので、こちらも是非ご覧ください。

BigQuery でできること
BigQuery とは、様々なデータを蓄積・統合・クエリできる Google Cloud の データウェアハウス(DWH)サービスです。
「データの蓄積やクエリ」と言うと、Oracle や PostgreSQL 等の RDBMS をイメージする方も多いと思います。しかし、BigQuery は RDBMS とは全く異なり、以下のように多くのメリットがあります。
OLAP に特化したアーキテクチャ
BigQuery は列指向アーキテクチャ(列方向にデータを保持する構造、図の右)であり、列単位でのクエリが得意です。オンライン分析処理( OLAP : Online Analytical Processing ) などのデータ分析では特定の列のみを抽出・処理することが多く、RDBMS(図の左)では行全体をスキャンする必要がありますが、BigQuery なら必要な列だけをスキャンできるため、パフォーマンスに優れています。
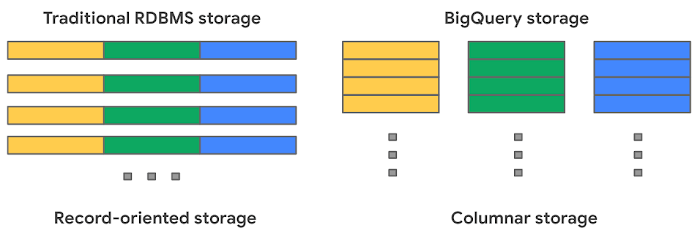
(画像は BigQuery 特集:ストレージの概要より引用)
また、BigQuery の内部ではストレージとコンピューティングのリソースが分離されています。ストレージ(図の左)はデータのレプリケーションと分散管理が行われているため、単一障害点なしで大規模なデータを蓄積できます。コンピューティング(図の右)は数万台規模のクラスターサーバーで構成されているため、複雑なクエリも 超並列処理 (MPP) による高速化 を利用することができます。
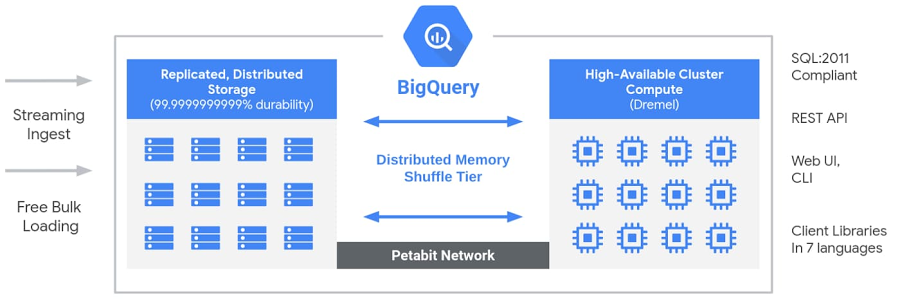
(画像は[新しいブログシリーズ] BigQuery 特集:概要より引用)
サーバーレス
BigQuery はサーバーレスサービスです。BigQuery の ストレージ容量は実質無制限 のため、将来のクエリ計画やデータ量を予測してストレージ/メモリを購入・増強したり、定期的なバキューム処理で使用可能スペースを確保する必要はありません。インフラ管理者を悩ませる セキュリティパッチ適用やライセンス更新といった作業も不要 です。
加え、BigQuery の SLA は非常に高く、 2020 年には 99.99% の保証を発表 しています。これは、競合の AWS Redshift や Azure Synapse Analytics を大きく引き離しています。特に安定稼働を重視するプロジェクトでは、BigQuery の高い SLA は重要な指標の 1 つとなり得るでしょう。
| プロバイダー | サービス名 | SLA |
|---|---|---|
| Google Cloud | BigQuery | 99.99% |
| AWS | Redshift | 99.9% |
| Azure | Synapse Analytics | 99.9% |
低コスト
これだけのメリットがあるとさぞ高いのでは...と思いたくなりますが、BigQuery のオンデマンド分析は従量課金制となっており、使った分のみの請求となります。単価も安く、仮に 10TB のデータに対して同量のクエリスキャンを毎月行ったとしても、使用料はわずか $300 未満/月です。
高額な DWH サービスでは導入前に入念な事前検証を求められますが、BigQuery ならば 少額の予算からスモールスタートが可能 です。更に、1TB までのクエリ、10GB までのストレージ使用なら毎月無料のため、小規模なデータセットなら料金を気にせず実行できます。
| 科目 | 単価(東京リージョン) |
|---|---|
| オンデマンドクエリ料金 | $6.00/TB |
| ストレージ料金 | $0.023/GB |
直近のアップデート
2022 年 10 月にGoogle Cloud Next'22 が開催され、多数のサービスで大幅なアップデートが発表されました。BigQuery でも重要な機能がプレビュー公開されましたので、いくつかご紹介いたします。
非構造化データのサポート
BigQuery の新しいテーブルタイプであるオブジェクトテーブルのプレビュー版が公開され、Google Cloud Storage に保存された画像、音声、PDF ドキュメントなどの非構造化データに対して直接クエリ・機械学習を実行できるようになりました。
これまで非構造化データはサポートしておらず、API や前処理加工を通じて構造化データを抽出する作業が別途必要でしたが、このアップデートにより 非構造化データの検索・加工・学習を BigQuery だけで実行できる ようになります。
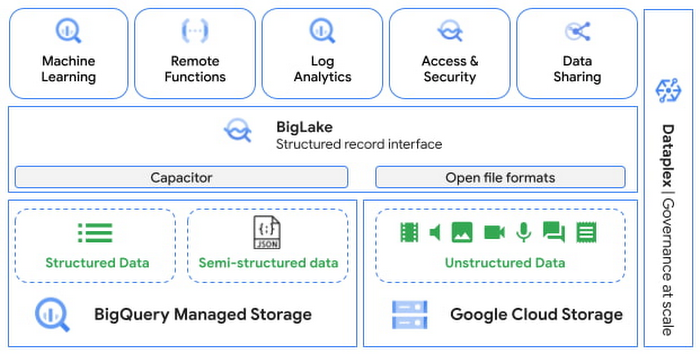
(画像はデータと AI の統合により BigQuery に非構造化データ分析を提供するより引用)
SQL 以外の言語をサポート
Apache Spark 用ストアドプロシージャのプレビュー版が公開され、BigQuery から Apache Spark プログラムを実行できるようになりました。
これまで Apache Spark を活用したデータ処理は、DataProc 単体で実行する方法と、BigQuery コネクタを通じて DataProc からデータを読み書きする方法がありましたが、どちらも DataProc のクラスタ構築が必要でした。今回のアップデートで BigQuery 上で Apache Spark の ETL を直接実行できる ようになるため、既存の Spark 資産をサーバーレスな BigQuery で実行できるのはとても便利です。
さらに、リモート関数が一般公開され、Cloud Functions と Cloud Run で作成したユーザー定義関数を実行できるようになりました。SQL と JavaScript 以外の選択肢が増えたことで、開発の柔軟性がさらに高まりました。
(画像はBigQuery で無制限のワークロードを構築: SQL 以外の言語を使用した新機能より引用)
トランザクションデータをニアリアルタイムで分析
Datastream for BigQuery のプレビュー版が公開され、PostgreSQL、MySQL、AlloyDB、Oracle などのデータベースから BigQuery に直接データをレプリケーションできるようになりました。
BigQuery へのデータ反映作業が自動化されることで、反映後の分析やレポート生成の頻度・スピードが向上し、データドリブンな意思決定を加速させることができます。
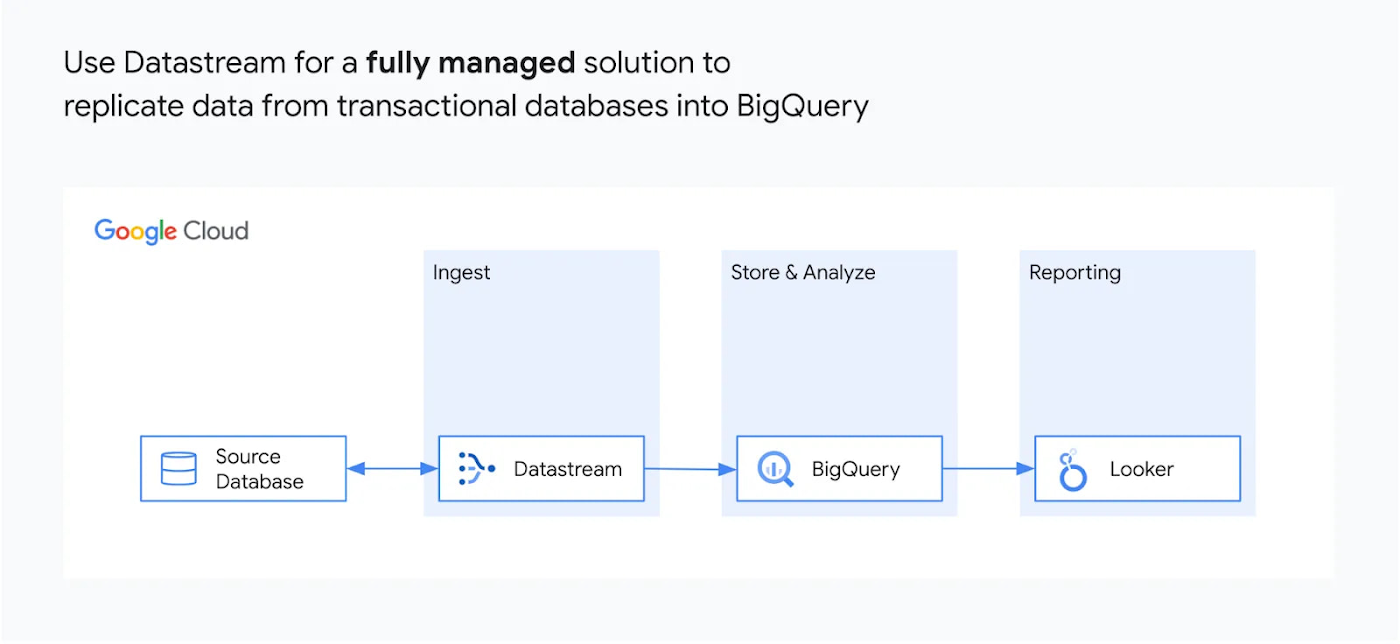
(画像は Datastream for BigQuery のご紹介より引用)
BigQuery のアンチパターン
アップデートの度に便利になる BigQuery ですが、適切な使い方をしないと思わぬコストが発生する場合があります。
BigQuery ではクエリ料金が大半を占めることが多いため、 いかにスキャンデータを抑えるか、がコストコントロールの要 です。ここでは、BigQuery におけるコスト最適化のベストプラクティスを参考に、コスト高になり得るアンチパターンとその回避方法をご紹介します。
① SELECT * を使わず、必要なカラムを指定する
SELECT *を実行すると、全ての列でフルスキャンが実行されてしまいます。代わりに、 必要なカラムを指定することで、スキャンデータ量を最小限に抑える ことができます。また、 LIMIT 句を指定してもスキャンデータ量は変わらない(コスト削減にならない) 点にも注意が必要です。
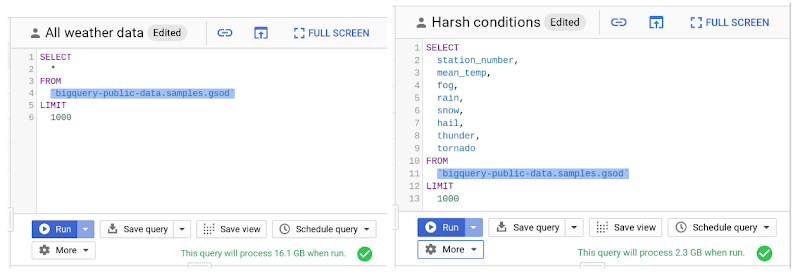
(画像は BigQuery におけるコスト最適化のベストプラクティスより引用)
② クエリに上限を設定する
デフォルトではクエリのスキャンデータ量に上限は無いため、誤ったクエリによりフルスキャンが実行されることがあり得ます。代わりに、課金される最大バイト数を設定すると、上限値を超えそうな場合はクエリがエラーとなり、料金は発生しません。人為的なミスはどんなに注意しても起こり得るものですので、設定を推奨します。
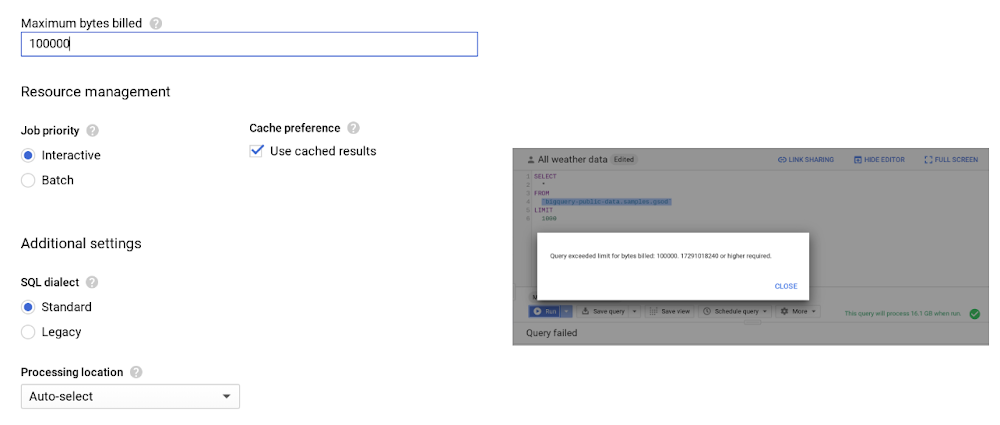
(画像は BigQuery におけるコスト最適化のベストプラクティスより引用)
③ テーブルを分割する
時系列に増えるデータを単一のテーブルに追加し続けると、テーブルサイズが大きくなり、スキャンデータ量が増加してしまいます。BigQuery では、①データの取り込み時間、②日付やタイムスタンプ列、③整数列のいずれかで テーブルをパーティション分割 することが推奨されています。これにより、クエリ時にテーブル全体ではなく必要なパーティションのみがスキャンされるため、スキャンデータ量を削減できます。
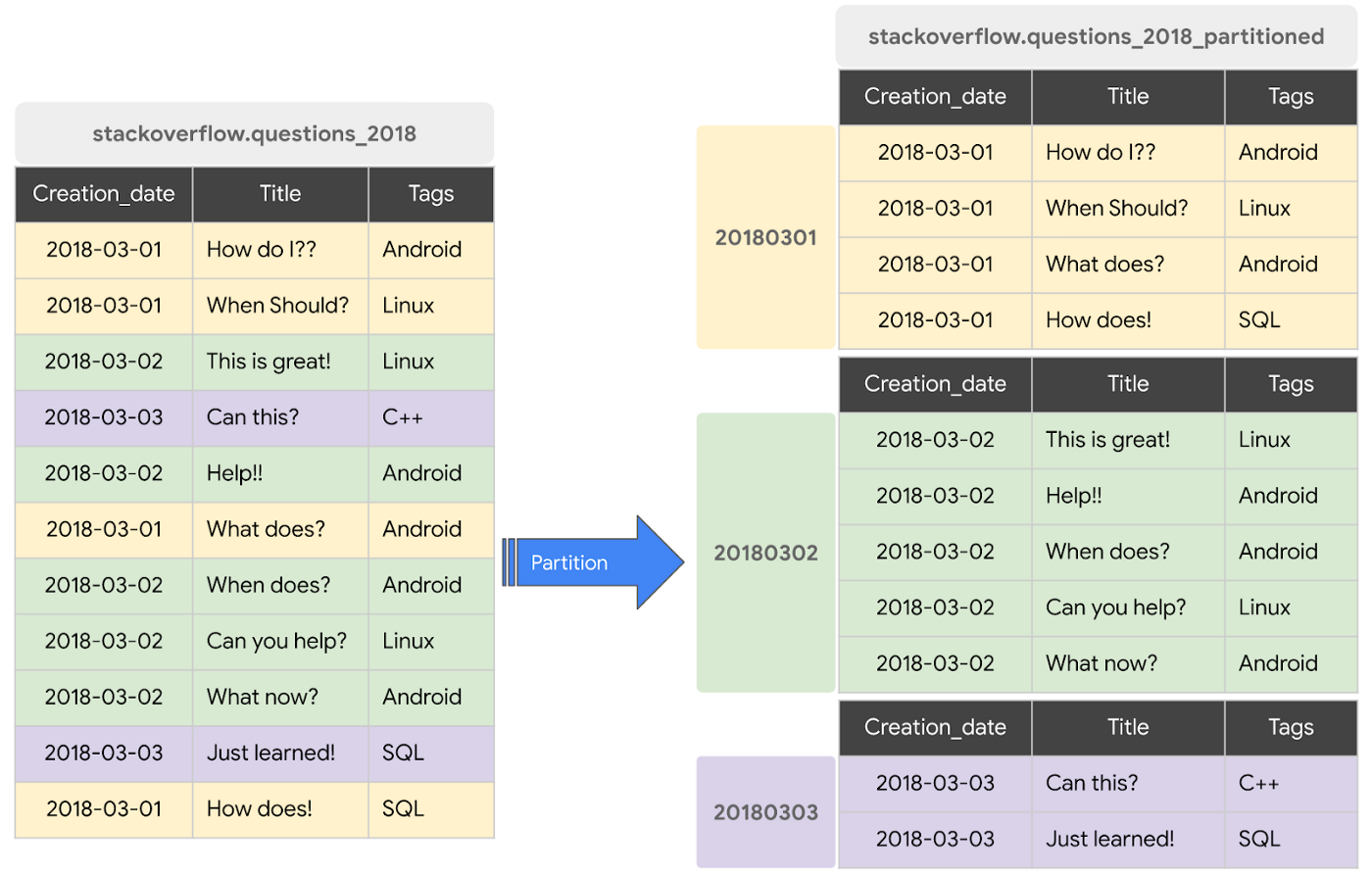
(画像は BigQuery 特集:ストレージの概要より引用)
サービスの概観
本記事では分量の都合から取り上げませんでしたが、BigQuery には他にも、
- BigQuery ML による機械学習
- BigQuery Omni によるマルチクラウド連携
- Tableau や Looker Studio 等の BI ツールとの連携
など、多様な機能を有しています。BigQuery の概観をざっと知るには、以下のクイックリファレンスが便利です。日本語の解説記事もありますので、ぜひご覧下さい。
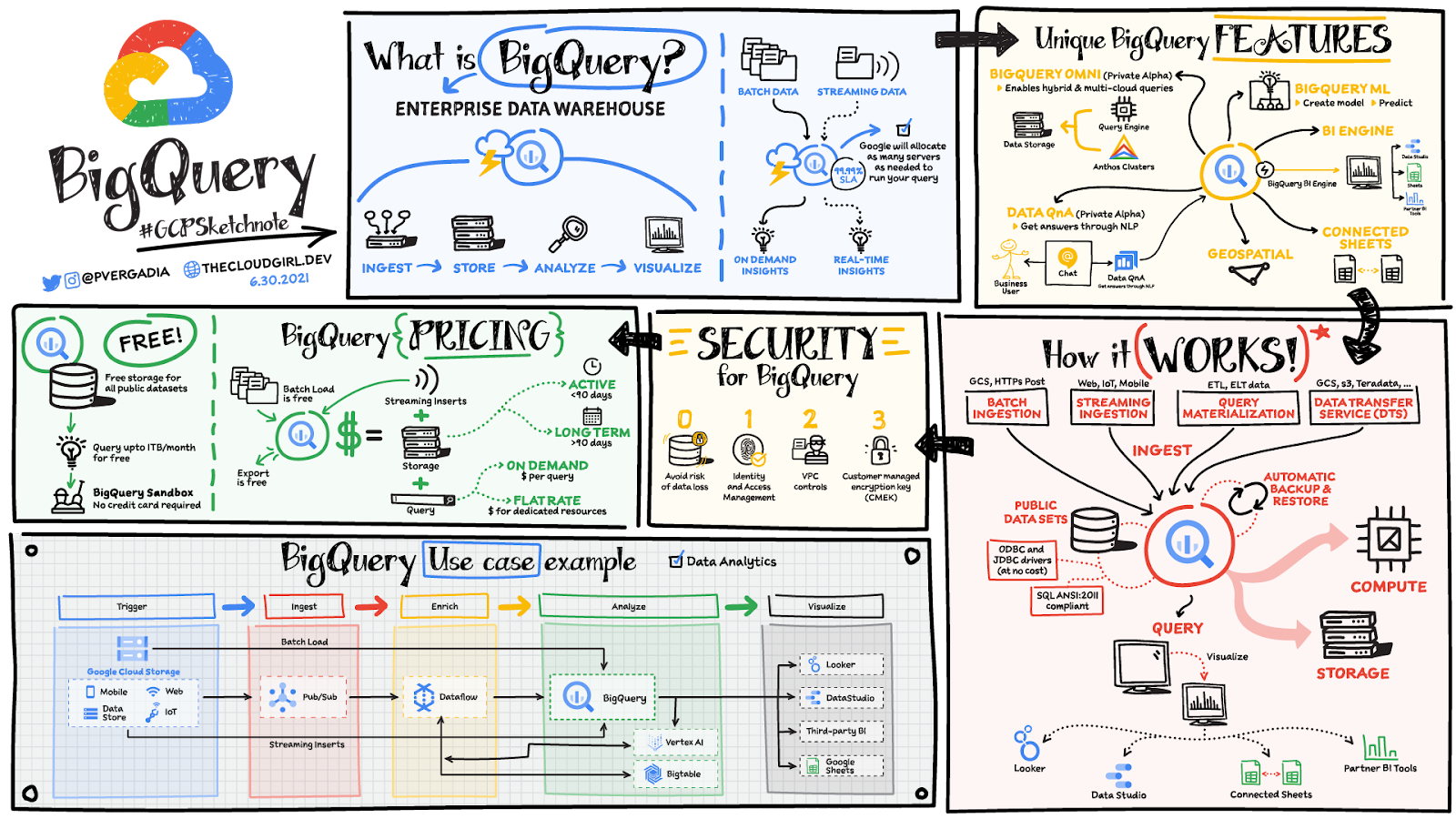
(画像は BigQuery で「ビッグ」なクエリを実行:クイックリファレンスより引用)
まとめ
本記事では、BigQuery という DWH サービスを紹介させていただきました。BigQuery は DWH として優れた機能が多々あり、今後もアップデートが期待されるサービスの1つですので、Google Cloud を使用される際は積極的に活用していきたいですね。
より詳細に BigQuery を知りたい方は、以下の記事をご参照ください。
藤根 成暢
みずほリサーチ&テクノロジーズ
先端技術研究部に所属。Pythonによるデータ分析やAI開発、Google Cloudの技術検証などを担当。保有資格はACE、PDE。