


G-gen 又吉です。Google の提供する最新の生成 AI モデルである Gemini を用いて、マルチモーダルな生成 AI チャットアプリを簡単に開発できましたので、ご紹介します。

概要
当記事の内容
Google の提供する最新の生成 AI モデルである Gemini を用いて、テキスト、画像、動画の入力に対応したマルチモーダルな生成 AI チャットアプリを作ってみたので、当記事ではその開発の経緯をご紹介します。
実行環境として Google Cloud(旧称 GCP)の Cloud Run を利用しています。また、Cloud Run サービスの前段に Identity-Aware Proxy (IAP) 認証を用いることで、社内ユーザーのみがアクセスできる状態を構成しました。
Vertex AI 経由で提供される Gemini API を用いていますので、生成 AI モデルへの入出力データは Google によって利用されることがなく、データガバナンスを維持することができます。この点が、コンシューマ向け生成 AI サービスである Bard との大きな違いです。
デモ動画
以下は、当記事で開発したマルチモーダル生成 AI チャットアプリのデモ動画です。
前提知識
Gemini とは
Gemini とは、Google が2023年12月初旬に発表した、最新の生成 AI モデルです。テキスト、画像、動画など、複数の形式のデータを扱えるマルチモーダル生成 AI モデルであり、テキスト生成、動画や画像の説明など、さまざまなタスクで高いパフォーマンスを出すとされています。
Gemini には Ultra、Pro、Nano という3つのサイズが用意されておりますが、2024年1月現在では Pro のみが Vertex AI 上で Public Preview(一般利用者も試用できる状態)となっています。
気軽に Vertex AI 上の Gemini Pro を触ってみたい方は、以下のブログで紹介しているように Google Cloud の Vertex AI Studio という Web UI を通して試すことができます。
使用するモデル
2024年1月現在、Vertex AI 上の Gemini API では Gemini Pro と Gemini Pro Vision の2つの基盤モデルが利用可能です。
| モデル名 | 説明 |
|---|---|
| Gemini Pro (gemini-pro) | 自然言語タスク、マルチターン(会話)、コード生成を処理するように設計されており、プロンプトにテキストのみを含む場合は Gemini Pro を推奨 |
| Gemini Pro Vision (gemini-pro-vision) | マルチモーダルなタスクを処理するように設計されており、プロンプトに画像や動画が含まれる場合は Gemini Pro Vision を推奨 |
今回の Web アプリ上では、ユーザーの入力 (プロンプト) がテキストのみの場合は Gemini Pro を、画像や動画も含まれる場合は Gemini Pro Vision を利用します。
Gradio
Gradio とは、Python で機械学習 Web アプリを容易に構築できるフレームワークです。
今回は、テキスト以外にも画像と動画の入力に対応できる Web アプリを構築するために以下のコンポーネントを使用しました。

| No | コンポーネント | 説明 |
|---|---|---|
| 1 | Chatbot | 会話履歴を表示する部分 |
| 2 | Image | 画像をアップロードする部分 |
| 3 | Video | 動画をアップロードする部分 |
| 4 | Textbox | テキストを入力する部分 |
| 5 | Slider | Gemini API のプロンプトパラメータを調整する部分 |
| 6 | Button | Refresh ボタンは画面をリロードする処理を、Submin ボタンはユーザーの入力を送信する処理を実装 |
Cloud Runサービスへのアクセス制御
Cloud Run サービスへのアクセス制御は、Identity-Aware Proxy (IAP) を用いることで IAP を利用できる IAM ロール がアタッチされた組織内 Google アカウント / グループ に制限することができます。
また、IAP を用いることで、ユーザーのメールアドレスが HTTP リクエストヘッダーに格納されます。
社内ユーザーしかアクセスできない仕様であれども、誰がどのくらい利用しているのか管理者側で把握したい場合に、IAP からユーザーのメールアドレスを取得してユーザーの識別ができることで実装可能になります。
全体の構成図は以下のとおりです。

準備
ディレクトリ構成
開発環境は Cloud Shell を用いて行います。ディレクトリ構成は以下のとおりです。
multimodal_app ディレクトリ配下は、以下のとおりです。
multimodal_app |-- app | |-- app.py | `-- requirements.txt `-- Dockerfile
app.py
app.py には、以下の Python コードを記述します。
import base64 from datetime import datetime import json import logging import math from typing import Optional import os import pytz import sys import time import google.cloud.logging from google.cloud import storage import gradio as gr import PIL.Image from proto.marshal.collections import RepeatedComposite import vertexai from vertexai.preview.generative_models import GenerativeModel, Part, GenerationConfig, GenerationResponse from moviepy.editor import VideoFileClip PROJECT_ID = os.environ.get("PROJECT_ID") if not PROJECT_ID: raise ValueError("PROJECT_ID environment variable is not set.") LOCATION = os.environ.get("LOCATION") if not LOCATION: raise ValueError("LOCATION environment variable is not set.") FILE_BUCKET_NAME = os.environ.get("FILE_BUCKET_NAME") if not FILE_BUCKET_NAME: raise ValueError("FILE_BUCKET_NAME environment variable is not set.") LOG_BUCKET_NAME = os.environ.get("LOG_BUCKET_NAME") if not LOG_BUCKET_NAME: raise ValueError("LOG_BUCKET_NAME environment variable is not set.") SUPPORTED_IMAGE_EXTENSIONS = [ "png", "jpeg", "jpg", ] SUPPORTED_VIDEO_EXTENSIONS = [ "mp4", "mov", "mpeg", "mpg", "avi", "wmv", "mpegps", "flv", ] ALL_SUPPORTED_EXTENSIONS = set(SUPPORTED_IMAGE_EXTENSIONS + SUPPORTED_VIDEO_EXTENSIONS) MAX_PROMPT_SIZE_MB = 4.0 # Cloud Logging ハンドラを logger に接続 logger = logging.getLogger() try: logging_client = google.cloud.logging.Client(project=PROJECT_ID) logging_client.setup_logging() except Exception as e: logger.error(f"An error occurred during Cloud Logging initialization: {e}") # Vertex AI インスタンスの初期化 try: vertexai.init(project=PROJECT_ID, location=LOCATION) except Exception as e: logger.error(f"An error occurred during Vertex AI initialization: {e}") # Cloud Storage インスタンスの初期化 try: storage_client = storage.Client(project=PROJECT_ID) except Exception as e: logger.error(f"An error occurred during Cloud Storage initialization: {e}") # Gemini モデルの初期化 try: txt_model = GenerativeModel("gemini-pro") multimodal_model = GenerativeModel("gemini-pro-vision") except Exception as e: logger.error(f"An error occurred during GenerativeModel initialization: {e}") # ファイルを Base64 にエンコード def file_to_base64(file_path: str) -> str: try: with open(file_path, "rb") as file: return base64.b64encode(file.read()).decode("utf-8") except Exception as e: logger.error(f"An error occurred during file_to_base64 func.: {e}") # ファイルの拡張子を取得 def get_extension(file_path: str) -> str: if "." not in file_path: logger.error(f"Invalid file path. : {file_path}") extension = file_path.split(".")[-1].lower() if not extension: logger.error(f"File has no extension. : {file_path}") return extension # 画像/動画ファイルを Cloud Storage にアップロード def file_upload_gsc(file_bucket_name: str, source_file_path: str) -> str: try: bucket = storage_client.bucket(file_bucket_name) # ファイルの名前を取得 destination_blob_name = os.path.basename(source_file_path) # ファイルをアップロード blob = bucket.blob(destination_blob_name) blob.upload_from_filename(source_file_path) return f"gs://{file_bucket_name}/{destination_blob_name}" except Exception as e: logger.error(f"Error uploading to Cloud Storage: {e}") # extension がサポートされているか判定 def is_extension(extension: str) -> bool: return extension in ALL_SUPPORTED_EXTENSIONS # mime_type を取得 def create_mime_type(extension: str) -> str: # サポートされた画像形式の場合 if extension in SUPPORTED_IMAGE_EXTENSIONS: return "image/jpeg" if extension in ["jpg", "jpeg"] else f"image/{extension}" # サポートされた動画形式の場合 elif extension in SUPPORTED_VIDEO_EXTENSIONS: return f"video/{extension}" # サポートされていない拡張子の場合 else: logger.error(f"Not supported mime_type for extension: {extension}") # プロンプトサイズの計算 def calculate_prompt_size_mb(text: str, file_path: str) -> float: try: # テキストサイズをバイト単位で取得 text_size_bytes = sys.getsizeof(text) # ファイルサイズをバイト単位で取得 file_size_bytes = os.path.getsize(file_path) # バイトからメガバイトに単位変換 prompt_size_mb = (text_size_bytes + file_size_bytes) / 1048576 except Exception as e: logger.error(f"Error calculating prompt size: {e}") return prompt_size_mb # safety_ratingsオブジェクトをリストに変換する def repeated_safety_ratings_to_list(safety_ratings: RepeatedComposite) -> list: safety_rating_li = [] for safety_rating in safety_ratings: safety_rating_dict = {} safety_rating_dict["blocked"] = safety_rating.blocked safety_rating_dict["category"] = safety_rating.category.name safety_rating_dict["probability"] = safety_rating.probability.name safety_rating_li.append(safety_rating_dict) return safety_rating_li # citation_metadataオブジェクトをリストに変換する def repeated_citations_to_list(citations: RepeatedComposite) -> list: citation_li = [] for citation in citations: citation_dict = {} citation_dict["startIndex"] = citation.startIndex citation_dict["endIndex"] = citation.endIndex citation_dict["uri"] = citation.uri citation_dict["title"] = citation.title citation_dict["license"] = citation.license citation_dict["publicationDate"] = citation.publicationDate citation_li.append(citation_dict) return citation_li # Gemini 利用ログの作成 def create_gemini_usage_log( current_time_str: str, user_name: str, temperature: float, max_output_tokens: int, top_k: int, top_p: float, text: str, response: GenerationResponse, gcs_file_path: Optional[str] = None, local_file_path: Optional[str] = None ) -> json: # 初期値を設定 image_path, video_path, video_duration = None, None, 0 # gcs_file_pathが提供された場合の処理 if gcs_file_path: # ファイルの拡張子を取得 file_extension = get_extension(gcs_file_path) # 画像ファイルの場合 if file_extension in SUPPORTED_IMAGE_EXTENSIONS: image_path = gcs_file_path # 動画ファイルの場合 elif file_extension in SUPPORTED_VIDEO_EXTENSIONS: video_path = gcs_file_path # 動画ファイルの場合は動画時間を取得 try: with VideoFileClip(local_file_path) as video: video_duration = math.ceil(video.duration) except Exception as e: logger.error(f"An error occurred while calculating the video duration: {e}") video_duration = 0 gemini_usage_log = { "current_time_str" : current_time_str, "user" : user_name, "prompt" : { "text" : text, "image_path" : image_path, "video_path" : video_path, "video_duration" :video_duration, "config" : { "temperature" : temperature, "top_p" : top_p, "top_k" : top_k, "max_output_tokens" : max_output_tokens }, }, "response" : { "text" : response.candidates[0].text, "finish_reason" : response.candidates[0].finish_reason.name, "finish_message" : response.candidates[0].finish_message, "safety_ratings" : repeated_safety_ratings_to_list(response.candidates[0].safety_ratings), "citation_metadata" : repeated_citations_to_list(response.candidates[0].citation_metadata.citations) }, "usage_metadata" : { "prompt_token_count" : response._raw_response.usage_metadata.prompt_token_count, "candidates_token_count" : response._raw_response.usage_metadata.candidates_token_count, "total_token_count" : response._raw_response.usage_metadata.total_token_count } } gemini_usage_log_json = json.dumps(gemini_usage_log) return gemini_usage_log_json # ログデータを Cloud Storage にアップロード def log_upload_gcs( log_bucket_name: str, current_time_str: str, user_name: str, log_data_json: json ): try: bucket = storage_client.get_bucket(log_bucket_name) blob = bucket.blob(f"output/{current_time_str}-{user_name}.json") blob.upload_from_string(log_data_json) except Exception as e: logger.error(f"Error uploading to Cloud Storage: {e}") # ユーザーのクエリメッセージを作成 def query_message(history: str, txt: str, image: str, video: str) -> str: try: # ユーザーのクエリがテキストのみの場合 if not (image or video): history += [(txt,None)] # ユーザーのクエリに画像が含まれる場合 if image: prompt_size_mb = calculate_prompt_size_mb(text=None, file_path=image) # 画像サイズが上限を超えた場合 if prompt_size_mb > MAX_PROMPT_SIZE_MB: history += [(f"[This Image is not display] {txt}", None)] else: image_extension = get_extension(image) base64 = file_to_base64(image) data_url = f"data:image/{image_extension};base64,{base64}" image_html = f'<img src="{data_url}" alt="Uploaded image">' history += [(f"{image_html} {txt}", None)] # ユーザーのクエリに動画が含まれる場合 if video: prompt_size_mb = calculate_prompt_size_mb(text=None, file_path=video) # 動画サイズが上限を超えた場合 if prompt_size_mb > MAX_PROMPT_SIZE_MB: history += [(f"[This video is not display] {txt}", None)] else: video_extension = get_extension(video) base64 = file_to_base64(video) data_url = f"data:video/{video_extension};base64,{base64}" video_html = f'<video controls><source src="{data_url}" type="video/{video_extension}"></video>' history += [(f"{video_html} {txt}", None)] except Exception as e: logger.error(f"Error processing query message: {e}") return history # Gemini からの出力を取得 def gemini_response( history: str, text: str, image: str, video: str, temperature: float, max_output_tokens: int, top_k: int, top_p: float, request: gr.Request ) -> str: try: # ログインしたユーザー情報を取得 user_email = request.headers.get('X-Goog-Authenticated-User-Email', 'Unknown') user_name = user_email.split(':')[1].split('@')[0] # 現在時刻を取得 jst = pytz.timezone('Asia/Tokyo') current_time_str = datetime.now(jst).strftime("%Y%m%d-%H%M%S") # テキストが未入力の場合 if not text: response = "テキストを入力して下さい。" history += [(None,response)] # テキストのみの場合 elif not (image or video): # Gemini Pro にリクエストを送信 response = txt_model.generate_content( contents=text, generation_config=GenerationConfig( temperature=temperature, top_p=top_p, top_k=top_k, max_output_tokens=max_output_tokens ) ) # Gemini Pro 使用ログを作成 gemini_usage_log_json = create_gemini_usage_log( current_time_str=current_time_str, user_name=user_name, temperature=temperature, max_output_tokens=max_output_tokens, top_k=top_k, top_p=top_p, text=text, response=response, ) # データを Cloud Storage にアップロード log_upload_gcs( log_bucket_name=LOG_BUCKET_NAME, current_time_str=current_time_str, user_name=user_name, log_data_json=gemini_usage_log_json ) history += [(None,response.text)] # 画像と動画の両方が入力された場合 elif image and video: response = "1度に画像と動画を含めることはサポートされていません。" history += [(None,response)] else: # ファイルパスを取得 file_path = image or video # プロンプトサイズを取得 prompt_size_mb = calculate_prompt_size_mb(text=text, file_path=file_path) # プロンプトサイズが上限を超えた時 if prompt_size_mb > MAX_PROMPT_SIZE_MB: response = f"画像/動画とテキストを含むプロンプトサイズは{MAX_PROMPT_SIZE_MB}MB未満として下さい。現在のプロンプトサイズは{round(prompt_size_mb, 1)}MBです。" history += [(None,response)] else: # ファイルの拡張子を取得 extension = get_extension(file_path=file_path) # サポートされている extension の場合 if is_extension(extension): # 画像/動画ファイルを Cloud Storage にアップロード gcs_url = file_upload_gsc(file_bucket_name=FILE_BUCKET_NAME, source_file_path=file_path) # mime_type を取得 mime_type = create_mime_type(extension) # Gemini Pro Vision にリクエストを送信 file = Part.from_uri(uri=gcs_url, mime_type=mime_type) response = multimodal_model.generate_content( contents=[file, text], generation_config=GenerationConfig( temperature=temperature, top_p=top_p, top_k=top_k, max_output_tokens=max_output_tokens ) ) # Gemini Pro Vision 使用ログを作成 gemini_usage_log_json = create_gemini_usage_log( current_time_str=current_time_str, user_name=user_name, temperature=temperature, max_output_tokens=max_output_tokens, top_k=top_k, top_p=top_p, text=text, response=response, gcs_file_path=gcs_url, local_file_path=file_path ) # データを Cloud Storage にアップロード log_upload_gcs( log_bucket_name=LOG_BUCKET_NAME, current_time_str=current_time_str, user_name=user_name, log_data_json=gemini_usage_log_json ) history += [(None,response.text)] else: support_image_extensions_str = ", ".join(SUPPORTED_IMAGE_EXTENSIONS) support_video_extensions_str = ", ".join(SUPPORTED_VIDEO_EXTENSIONS) response = f"サポートされている形式について、画像の場合は {support_image_extensions_str} で、動画の場合は {support_video_extensions_str} です。" history += [(None,response)] except Exception as e: logger.error(f"Error during Gemini response generation: {e}") return history # Gradio インターフェース with gr.Blocks() as app: # 画面の各コンポーネント with gr.Row(): with gr.Column(): chatbot = gr.Chatbot(scale = 2) with gr.Column(): image_box = gr.Image(type="filepath", sources=["upload"], scale = 1) video_box = gr.Video(sources=["upload"], scale = 1) with gr.Row(): with gr.Column(): text_box = gr.Textbox( placeholder="テキストを入力して下さい。", container=False, scale = 2 ) with gr.Column(): with gr.Row(): temperature = gr.Slider(label="Temperature", minimum=0, maximum=1, step=0.1, value=0.4, interactive=True) max_output_tokens = gr.Slider(label="Max Output Token", minimum=1, maximum=2048, step=1, value=1024, interactive=True) with gr.Row(): top_k = gr.Slider(label="Top-K", minimum=1, maximum=40, step=1, value=32, interactive=True) top_p = gr.Slider(label="Top-P", minimum=0.1, maximum=1, step=0.1, value=1, interactive=True) with gr.Row(): btn_refresh = gr.Button(value="Refresh") btn_submit = gr.Button(value="Submit") # Submitボタンが押下されたときの処理 btn_submit.click( query_message, [chatbot, text_box, image_box, video_box], chatbot ).then( gemini_response, [chatbot, text_box, image_box, video_box, temperature, max_output_tokens, top_k, top_p], chatbot ) # Refreshボタンが押下されたときの処理 btn_refresh.click(None, js="window.location.reload()") app.launch(server_name="0.0.0.0", server_port=7860)
本 Web アプリでは、以下の点に考慮して作成しています。
- ユーザーのプロンプトがテキストのみの場合は gemini-pro に、画像もしくは動画を含む場合は gemini-pro-vision にリクエストを送信します。
- 画像や動画を含むプロンプト全体で 4MB 以上になった際は gemini-pro-vision へリクエストを実行しません。
- 画像や動画はサポートされてる拡張子のみを受け付けます。
- 画像と動画を一回のプロンプトで同時に送信しないようにしています。
一方で、以下の点は考慮しておりません。
- gemini-pro はマルチターン(会話)をサポートしていますが、本 Web アプリではマルチターンを考慮しておりません。
- gemini-pro-vision では画像ファイルを 1 回のプロンプトで最大 16 枚送信できますが、本 Web アプリは UI の設計上、1 回のプロンプトに 1 枚しか送信できません。
参考:Image requirements for prompts
参考:Video limits and requirements for prompts
requirements.txt
google-cloud-logging==3.9.0 google-cloud-storage==2.14.0 gradio==4.12.0 Pillow==10.1.0 google-cloud-aiplatform==1.38.1 moviepy==1.0.3
Dockerfile
FROM python:3.10-slim COPY ./app /app WORKDIR /app RUN pip install --no-cache-dir -r requirements.txt EXPOSE 7860 CMD ["python", "app.py"]
デプロイ
Cloud Shell にて、現在のディレクトリが multimodal_app ディレクトリであることを確認し、以下 gcloud コマンドを順次実行します。
# 環境変数の設定 PROJECT_ID={プロジェクト ID} BILLING_ACCOUNT_ID={請求先アカウント ID} REGION=asia-northeast1 FILE_BUCKET_NAME={FILE_BUCKET_NAME} LOG_BUCKET_NAME={LOG_BUCKET_NAME} AR_REPO={Artifact Repogitory のレポジトリ名} SERVICE_NAME={Cloud Run サービス名} SA_NAME={サービスアカウント名} # プロジェクト作成 gcloud projects create ${PROJECT_ID} --name=${PROJECT_NAME} # プロジェクト設定の変更 gcloud config set project ${PROJECT_ID} # 請求先アカウントの紐づけ gcloud beta billing projects link ${PROJECT_ID} \ --billing-account=${BILLING_ACCOUNT_ID} # API の有効化 gcloud services enable --project=$PROJECT_ID run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ compute.googleapis.com \ aiplatform.googleapis.com \ iap.googleapis.com # サービスアカウント作成 gcloud iam service-accounts create $SA_NAME # Cloud Storage バケットの作成 gcloud storage buckets create gs://$FILE_BUCKET_NAME gs://$LOG_BUCKET_NAME \ --location=$REGION \ --uniform-bucket-level-access \ --public-access-prevention # サービスアカウントへ権限付与 gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SA_NAME@$PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:$SA_NAME@$PROJECT_ID.iam.gserviceaccount.com" \ --role="roles/storage.admin" # Artifacts repositories 作成 gcloud artifacts repositories create $AR_REPO \ --location=$REGION \ --repository-format=Docker \ --project=$PROJECT_ID # イメージの作成&更新 gcloud builds submit --tag $REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME \ --project=$PROJECT_ID # Cloud Run デプロイ gcloud run deploy $SERVICE_NAME --port 7860 \ --image $REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME \ --no-allow-unauthenticated \ --service-account=$SA_NAME@$PROJECT_ID.iam.gserviceaccount.com \ --ingress=internal-and-cloud-load-balancing \ --region=$REGION \ --set-env-vars=PROJECT_ID=$PROJECT_ID,LOCATION=$REGION,FILE_BUCKET_NAME=$FILE_BUCKET_NAME,LOG_BUCKET_NAME=$LOG_BUCKET_NAME \ --memory=8Gi \ --cpu=2 \ --project=$PROJECT_ID
Cloud Run サービスと IAP の連携は、以下ブログの手順をご参照下さい。
動作検証
認証
マルチモーダル Web アプリの URL にアクセスすると、まず最初に IAP による認証画面が現れます。

許可された Google アカウントでログインするとマルチモーダル Web アプリの画面に遷移します。
テキストのみ
まずはテキストのみの入力を検証します。テキストのみの場合は、Gemini Pro モデルが利用されます。
入力するプロンプトは以下のとおりです。
BigQuery の特徴について箇条書きで3つにまとめて教えてください。
Gemini Pro からの出力は以下の通りでした。

画像①
画像と動画の入力には、Gemini Pro Vision モデルが利用されます。まずは、食べ物が写っている画像から食べ物の情報を取得できるか試してみます。

画像とともに入力するテキストは以下のとおりです。
画像から、料理名、特徴、1人前あたりのカロリー、アレルギー物質をjson形式で出力してください。
Gemini Pro Vision からの出力は以下の通りでした。
{ "料理名": "沖縄そば", "特徴": "沖縄そばは、沖縄県で古くから食べられている郷土料理です。鰹節と昆布で出汁をとったスープに、小麦粉を原料とした麺と三枚肉、かまぼこ、紅ショウガなどが乗っています。", "1人前あたりのカロリー": "約500kcal", "アレルギー物質": "小麦、卵、豚肉" }

画像②
画像内の表を読み取れるか試してみます。
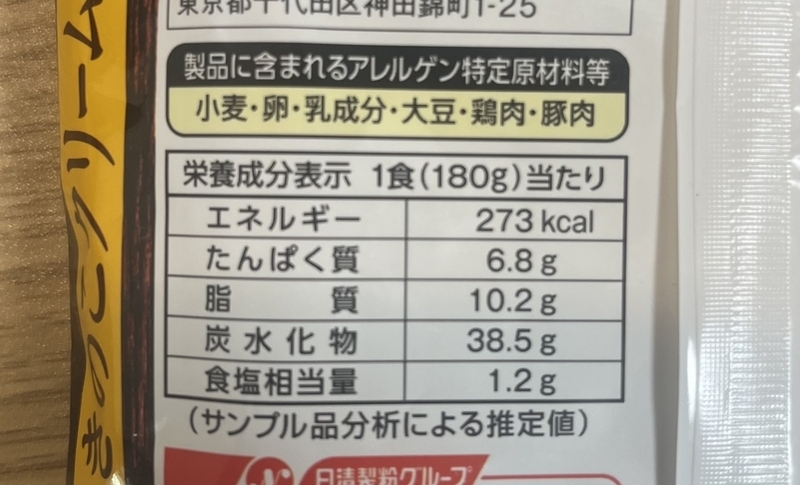
画像とともに入力するテキストは以下のとおりです。
栄養成分表示をテーブル形式で出力して下さい。
Gemini Pro Vision からの出力は以下の通りでした。
| 栄養成分表示 | 1食(180g)当たり |
|---|---|
| エネルギー | 273kcal |
| たんぱく質 | 6.8g |
| 脂質 | 10.2g |
| 炭水化物 | 38.5g |
| 食塩相当量 | 1.2g |

動画
愛犬とカフェに行った際の動画から動画内に写るオブジェクトを抽出させてみます。
動画とともに入力するテキストは以下のとおりです。
この動画内に映っている全てのオブジェクトにラベルを付けて、検索しやすい形で情報を提供してください。各オブジェクトの名称、種類、色をjson形式で出力してください。
Gemini Pro Vision からの出力は以下の通りでした。
{ "objects": [ { "name": "dog", "type": "animal", "color": "brown and white" }, { "name": "chair", "type": "furniture", "color": "black" }, { "name": "table", "type": "furniture", "color": "brown" }, { "name": "floor", "type": "surface", "color": "gray" }, { "name": "wall", "type": "surface", "color": "white" }, { "name": "ceiling", "type": "surface", "color": "white" }, { "name": "window", "type": "opening", "color": "transparent" }, { "name": "door", "type": "opening", "color": "brown" }, { "name": "tree", "type": "plant", "color": "green" }, { "name": "sky", "type": "natural", "color": "blue" }, { "name": "sea", "type": "natural", "color": "blue" }, { "name": "cloud", "type": "natural", "color": "white" }, { "name": "sun", "type": "natural", "color": "yellow" }, { "name": "ghost", "type": "decoration", "color": "white" } ] }

利用状況の可視化
Gemini API の料金は、入力した画像、動画、テキストの量と、出力されたテキストの量に応じた従量課金となります。マルチモーダルなチャットボットの導入に伴い、Gemini API の課金状況は気になるところです。
本 Web アプリでは、Gemini API への入出力情報をログとして Cloud Storage に出力しているため、そのログデータを解析することで利用状況を可視化することもできます。
以下は、組織全体またはユーザーごとに今どれだけ利用しているのか一目で把握できるように Looker Studio で可視化しています。

もし自社内で生成 AI を利用した社内アプリの実装を検討中なら、当社の Generative AI 活用支援ソリューションをご検討ください。
又吉 佑樹(記事一覧)
クラウドソリューション部
はいさい、沖縄出身のクラウドエンジニア!
セールスからエンジニアへ転身。Google Cloud 全 11 資格保有。Google Cloud Champion Innovator (AI/ML)。Google Cloud Partner Top Engineer 2024。Google Cloud 公式ユーザー会 Jagu'e'r でエバンジェリスト。好きな分野は生成 AI。
Follow @matayuuuu