


G-gen の佐々木です。当記事では、Google Cloud が提供するデータサイエンスエージェント(Data Science Agent)について解説します。データサイエンスエージェントは、Colab Enterprise ノートブック上で、AI エージェントがデータクレンジングや分析などのタスクを自動的に行う機能です。

概要
データサイエンスエージェントとは
Google Cloud のデータサイエンスエージェント(Data Science Agent)とは、データエンジニア、データサイエンティスト、データアナリストのタスクを支援するマネージド AI エージェントです。このエージェントにより、Colab Enterprise ノートブック上で自然言語によるデータ分析が実現できます。
データサイエンスエージェントは、Colab Enterprise ノートブック(IPYNB ファイル)を使用して、ユーザーの入力したプロンプトに従って以下のようなタスクを自律的に行います。
- 実行計画の生成
- データクレンジングの実行
- 探索的データ分析の実行、データ可視化
- 機械学習モデルのトレーニング、評価
データサイエンスエージェントは、Google Cloud コンソールの Colab Enterprise もしくは BigQuery Studio から使用することができます。
エージェントが自動的にコードを実行する場合は、コンピュートリソースとして Colab Enterprise のランタイムが使用されます。
- 参考 : データ サイエンス エージェントを使用する
- 参考 : BigQuery で Colab Enterprise データ サイエンス エージェントを使用する
- 参考 : ランタイムとランタイム テンプレート
注意点
データサイエンスエージェントは、2026年1月現在、Public Preview 版です。当記事で解説する内容は一般提供(GA)の際に変更される可能性があることを予めご了承ください。
Preview 版のサービスや機能を使うに当たっての注意点は、以下の記事も参考にしてください。
Google Colab のデータサイエンスエージェント
データサイエンスエージェントは、無料のクラウドホスト型ノートブック環境である Google Colab でも使用することができます。Google Cloud のサービスである Colab Enterprise や BigQuery と異なり、Google Cloud の契約が不要であるため、手軽にエージェントを使用することができます。
個人での使用など、Google Cloud が提供する企業・組織向けの高度なアクセス管理やサポート等が不要な場合は、まずはこちらでエージェントを試してみるのもよいでしょう。
Google Colab と Colab Enterprise の比較については、以下の記事をご一読ください。
制限事項
データサイエンスエージェントには、データソースの制限のほか、以下のような制限事項があります。
- 初回実行時に5~10分程度のレイテンシーが発生することがある(プロジェクト単位)。
- VPC Service Controls が有効化されているプロジェクトでは使用できない。
- PySpark を使用する場合、2026年1月現在は Serverless for Apache Spark 4.0 のみ生成できる。古いバージョンの Apache Spark コードは生成できない。
制限事項に関する最新の情報については以下のドキュメントを参照してください。
料金
データサイエンスエージェントは無料で利用することができます。
ただし、エージェントがノートブック上でコードを実行する場合、Colab Enterprise のランタイムが使用されるため、ランタイムの構成(マシンタイプ + ディスク容量)に応じた料金が発生します。
Colab Enterprise の料金に関しては以下の記事をご一読ください。
また、データソースとなる BigQuery にクエリを実行する場合など、他の Google Cloud のサービスを操作する場合、そのサービスの料金が別途発生する可能性がある点には注意が必要です。
開始方法
IAM ロールの設定
データサイエンスエージェントを使用するには、操作するユーザーに対して、プロジェクト単位で以下のロールを付与します。
- Colab Enterprise ユーザー(roles/aiplatform.colabEnterpriseUser)
Gemini in Colab Enterprise の起動
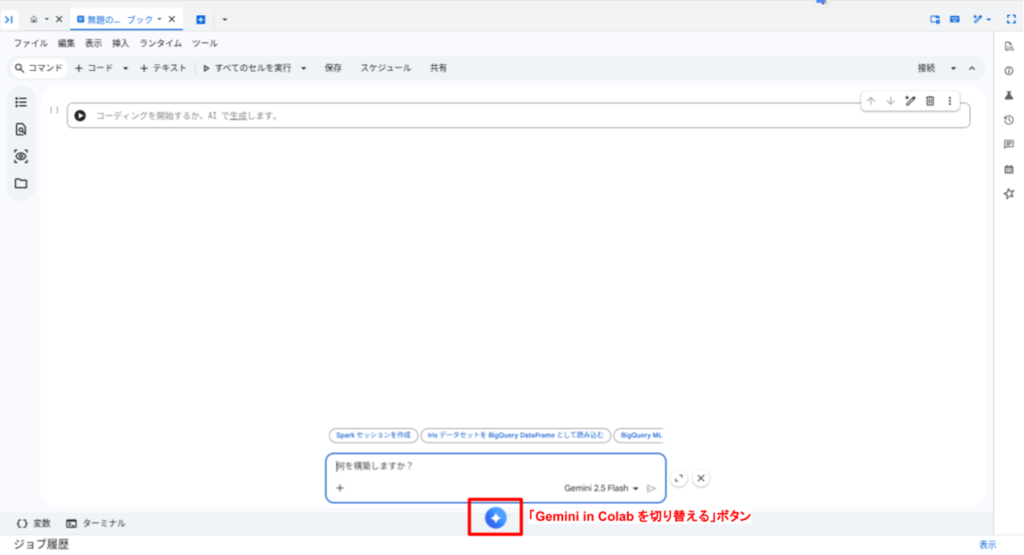
Colab Enterprise もしくは BigQuery Studio で Colab Enterprise ノートブックを開きます。画面下部にある青いボタンを押下することで、Gemini(Gemini in Colab Enterprise)のプロンプト入力を行い、データサイエンスエージェントに対して指示を与えることができます。
読み取り可能なデータソース
CSV ファイル
CSV ファイルをデータソースとする場合、プロンプト入力ウィンドウにある + マークからファイルをアップロードし、エージェントが参照するファイルとして指定することができます。
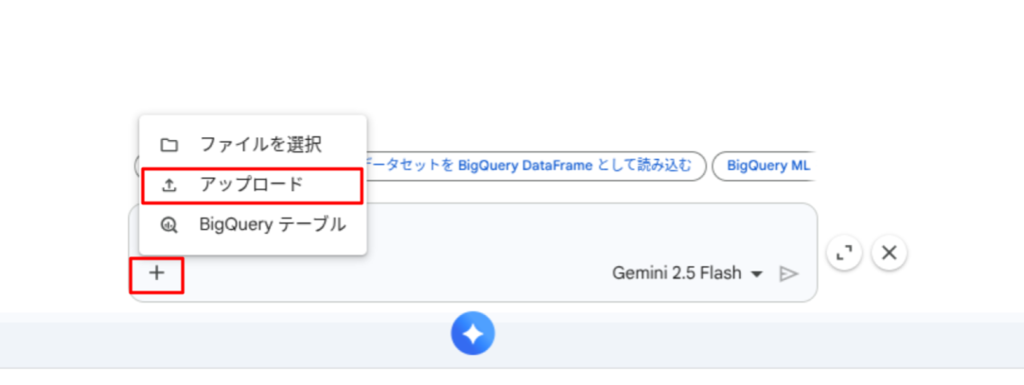
アップロードしたファイルのパスは /content/<ファイル名> となります。
BigQuery テーブル
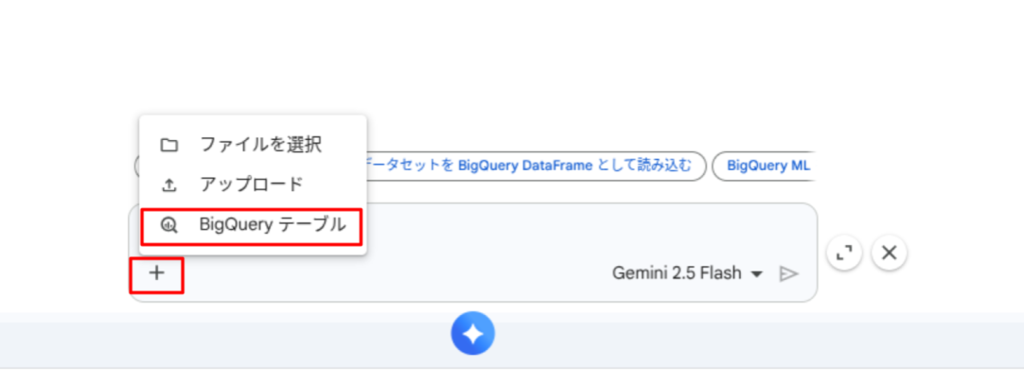
BigQuery テーブルをデータソースとする場合、以下の方法でエージェントからテーブル内のデータを参照できます。
- テーブルセレクタを使用する。
- プロンプトに
<プロジェクトID>:<データセット名>.<テーブル名>の形式で記述する。 - プロンプトに
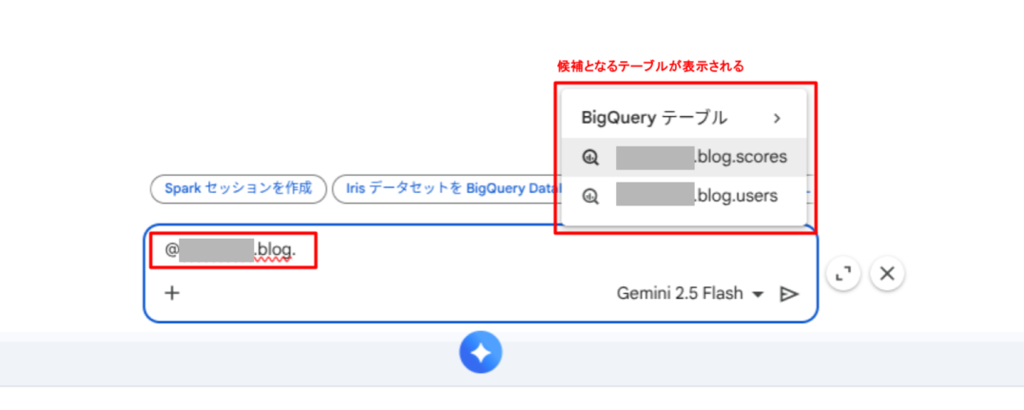
@を記述して BigQuery テーブルを検索する。
テーブルセレクタは、プロンプト入力ウィンドウにある + マークから使用することができます。検索フィルタを設定することで、他のプロジェクトや一般公開データセットのテーブルも参照できます。
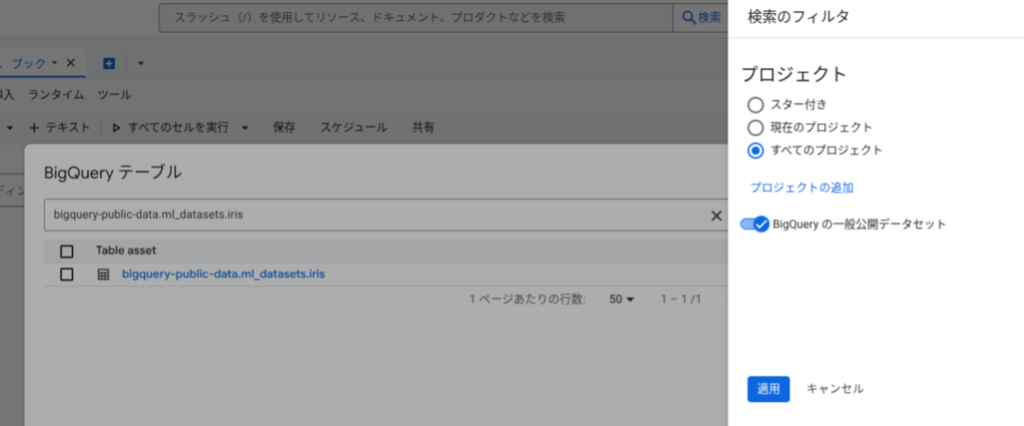
プロンプト内でテーブルを指定する場合は、以下の例のように、プロンプトに <プロジェクトID>.<データセット名>.<テーブル名> の形式で記述することで、対象のテーブルのデータを参照することができます。こちらの方法でも、他のプロジェクトや一般公開データセットのテーブルが参照できます。
`bigquery-public-data.ml_datasets.iris` を使い、アヤメの種類を分類するロジスティック回帰モデルを構築してください
また、プロンプトに @<プロジェクトID>.<データセット名>.<テーブル名> のように記述することで BigQuery テーブルを検索することもできます。検索結果として他のプロジェクトのテーブルも表示されますが、実際に参照できるのは同じプロジェクトに存在するテーブルのみです。なお、他のプロジェクトのテーブルを指定すると無視されます。
使用例
BigQuery Studio でデータサイエンスエージェントを使用し、機械学習モデルの構築を試してみます。
まず、BigQuery Studio で新しいノートブックを開きます。
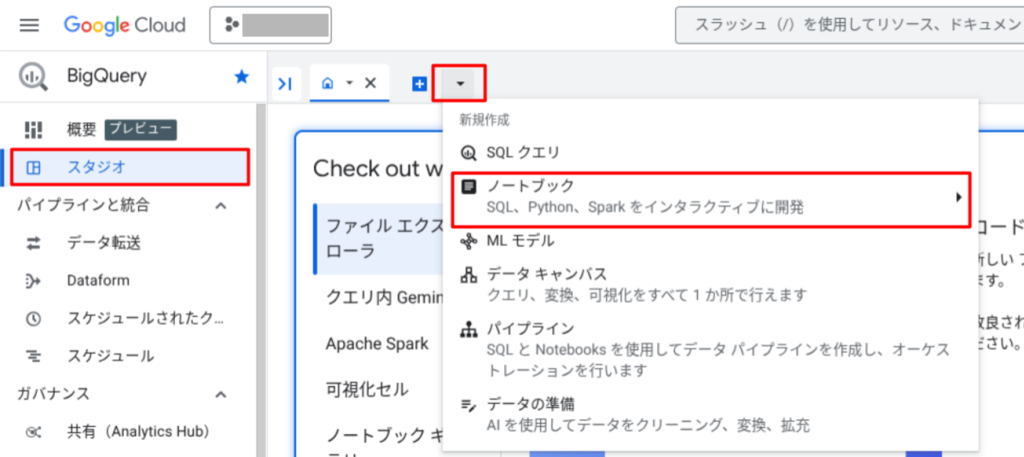
以下のプロンプトを送信して、BigQuery の一般公開データセットにある iris テーブルを使用した機械学習モデルの構築を指示します。
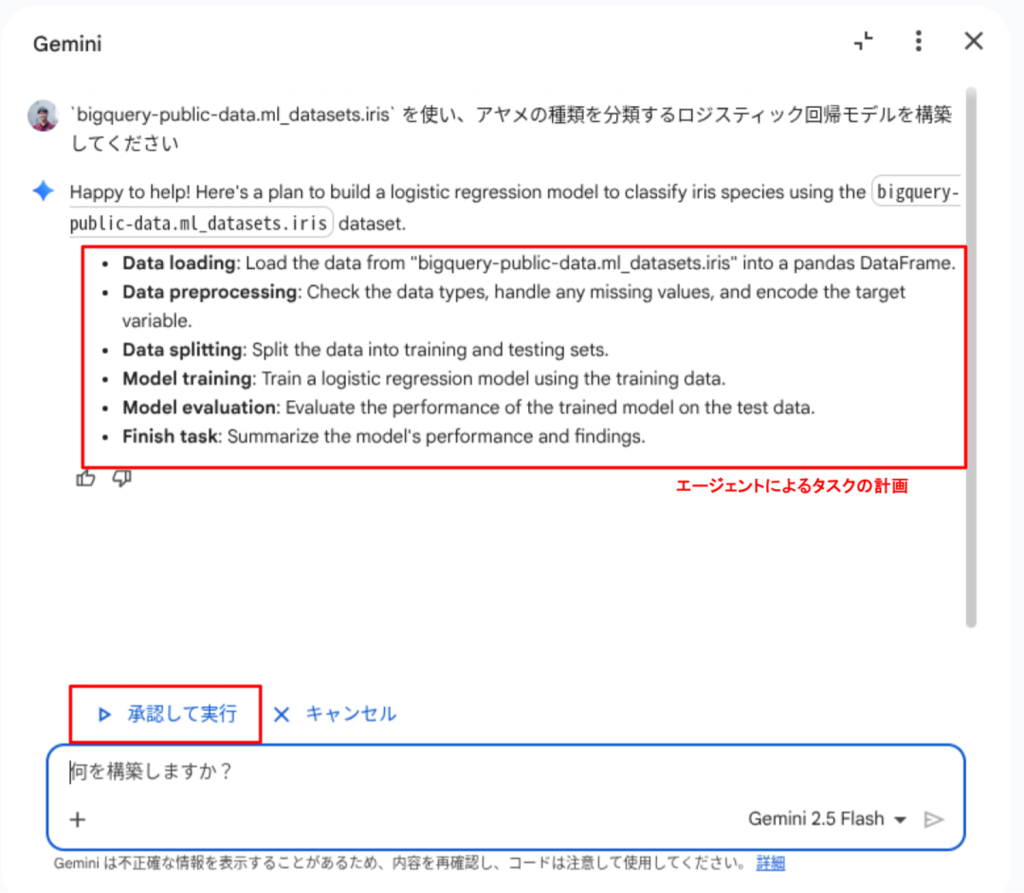
`bigquery-public-data.ml_datasets.iris` を使い、アヤメの種類を分類するロジスティック回帰モデルを構築してください
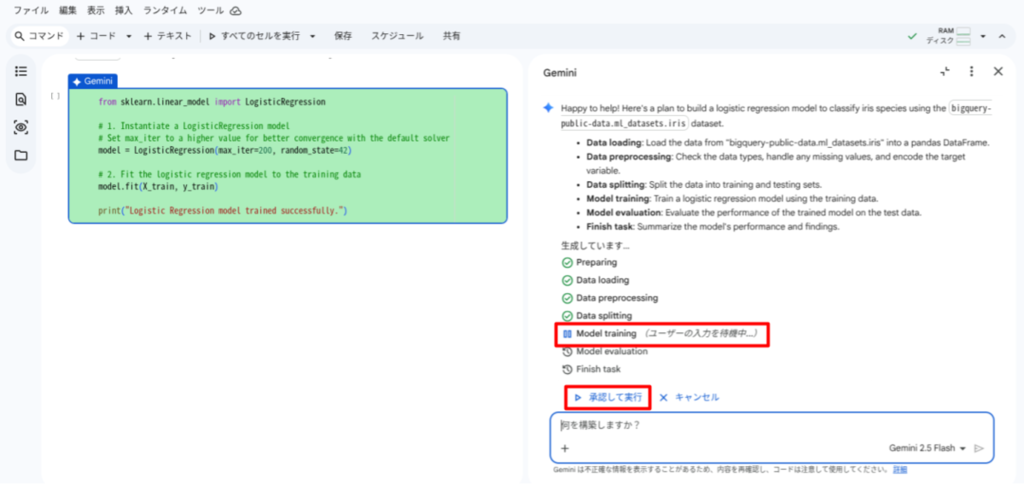
プロンプトを送信すると、タスクの実行計画が表示されます。内容を確認し、[承認して実行] を押下します。
実行計画に従い、エージェントによる自律的なコード生成、実行が行われます。
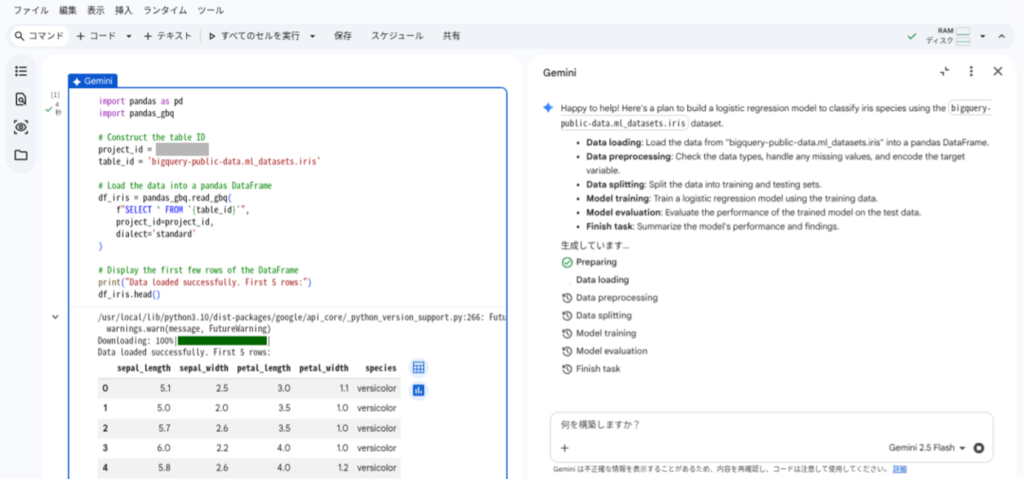
2026年1月時点では、タスクの各段階の実行前にユーザーによる承認が必要となっています。都度、前のタスクの実行結果と生成されたコードをレビューし、[承認して実行] を押下します。
すべてのタスクが完了すると、エージェントが実行したタスクのサマリーが出力されます。
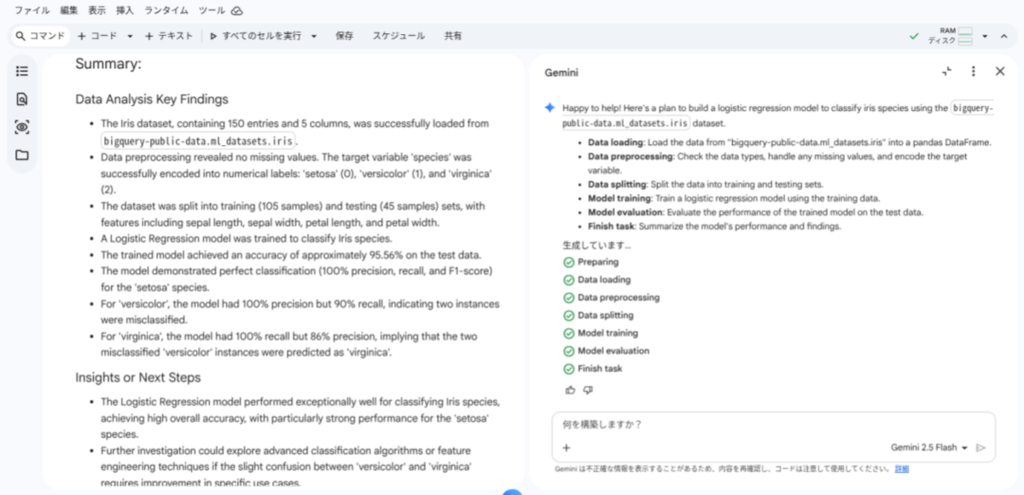
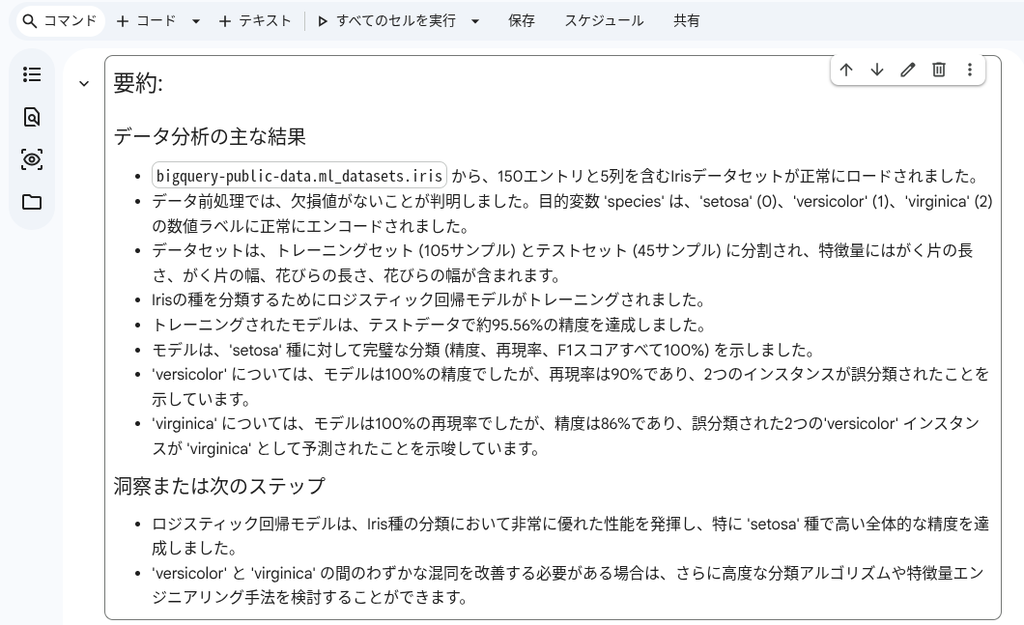
なお、今回は出力が英語になってしまったので、プロンプトで指示を与えて日本語に翻訳します。
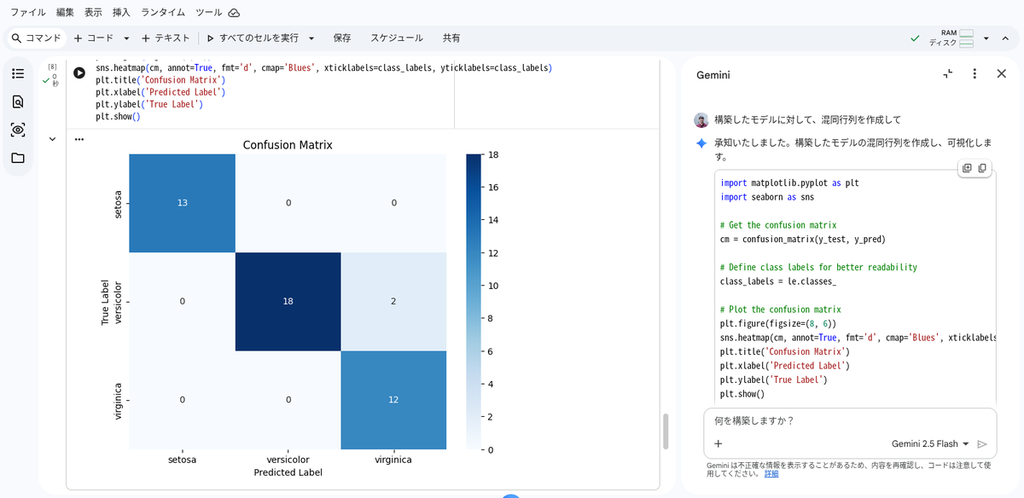
構築したモデルの評価のため、混同行列を用いた可視化を指示してみます。以下のプロンプトを送信します。
構築したモデルに対して、混同行列を作成して
別の分類アルゴリズムでモデルを作成し、最初のモデルと比較してみます。以下のプロンプトを送信します。
ランダムフォレストを使用したモデルを構築し、最初のモデルと性能を比較してください。
エージェントによって新たなタスクの計画、実行がされ、サマリーとして以下の出力が得られました。今回の検証では、ランダムフォレストを使用するモデルよりも、最初に構築したロジスティック回帰モデルのほうが良い成績を出しているようです。
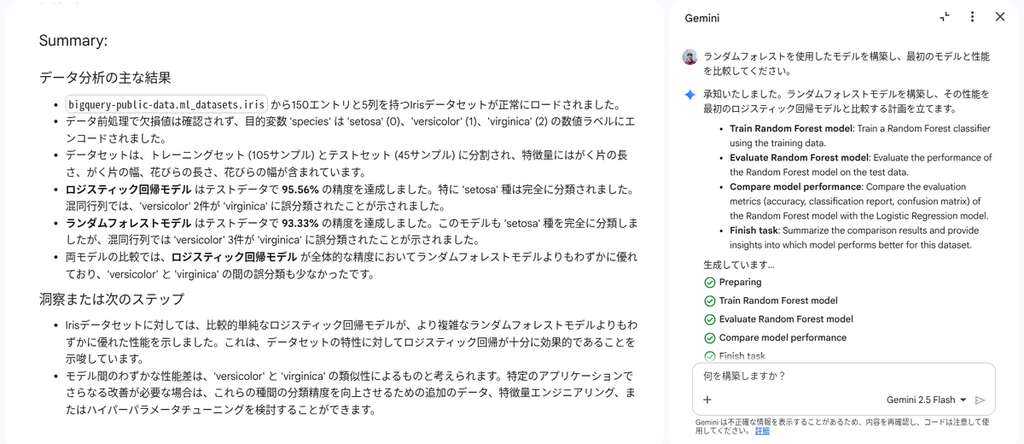
このように、データサイエンスエージェントを使用することで、コード生成における Vibe Coding のように、自然言語によるデータ分析を行うことができます。
佐々木 駿太 (記事一覧)
G-gen 最北端、北海道在住のクラウドソリューション部エンジニア
2022年6月に G-gen にジョイン。Google Cloud Partner Top Engineer に選出(2024 / 2025 Fellow / 2026)。好きな Google Cloud プロダクトは Cloud Run。
趣味はコーヒー、小説(SF、ミステリ)、カラオケなど。
Follow @sasashun0805