



G-gen の西島です。本記事は Google Cloud Next '24 in Las Vegas の2日目に行われた Breakout Session「What's new with BigQuery」のレポートです。
他の Google Cloud Next '24 の関連記事は Google Cloud Next '24 カテゴリの記事一覧からご覧いただけます。
- セッションの概要
- BigQuery data preparation(Preview)
- BigQuery workflows(Preview)
- BigQuery continuous queries(Preview)
- Cross-region disaster recovery(Preview)
- Query acceleration improvements(一部 GA、一部 Preview)
- 関連記事

セッションの概要
本セッションでは BigQuery に関連する新機能が多数発表されました。
キーワードとして「AI」と「unified(統合された)」という単語が頻出しており、BigQuery が AI に対応した単一のデータプラットフォームとして進化していることが強調されました。
BigQuery data preparation(Preview)
BigQuery data preparation は、生成 AI の補助のもと、BigQuery のデータのクレンジングができる仕組みです。
ビジネス的な背景情報を考慮したうえで、生成 AI がデータ変換のレコメンデーションを提示してくれます。データ変換の SQL パイプラインのデプロイとオーケストレーション、監視も機能として組み込まれるとされています。

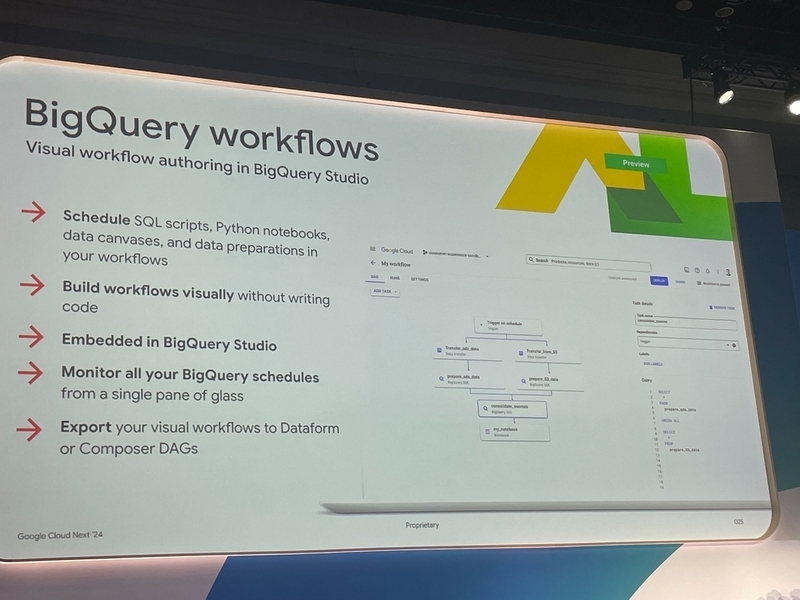
BigQuery workflows(Preview)
BigQuery workflows は BigQuery Studio(BigQuery の Web コンソール画面)組み込みのワークフロー機能です。コーディングなしに、GUI 上で、SQL スクリプトや Python notebook、データキャンバス、前述の data preparation を実行するワークフローを構築し、スケジューリングできます。さらに、ワークフローは Dataform や Composer 用にエクスポートできます。
従来から存在する Scheduled query は手軽である一方、単発の単純な SQL 実行に特化しており、複雑なワークフローを実行するには Dataform や Composer などのワークフローツールを用いる必要がありました。BigQuery workflows は、Scheduled query とこれらのワークフローツールの中間に位置するツールになると考えられます
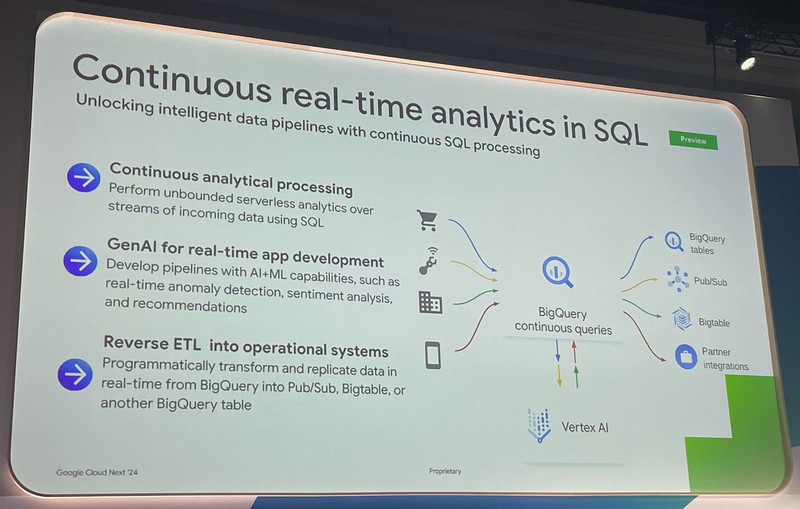
BigQuery continuous queries(Preview)
Continuous queries は BigQuery で継続的にクエリを実行できる機能です。ストリームデータ(連続的なデータ)に対して繰り返し、継続的に SQL を実行します。用途として「リアルタイム異常検知、感情分析、レコメンデーションなどの AI/ML 用のパイプライン」「BigQuery テーブルから他のテーブル、Pub/Sub、Bigtable などへのデータ移送「CRM 等、業務アプリケーションへのリバース ETL」などが考えられます。
リアルタイムなデータ移送は、これまで Dataflow 等を用いる必要がありました。今後は、高度な柔軟性と高いパフォーマンスが求められる場合は Dataflow を選び、学習コストの低い SQL を使ったパイプラインや BigQuery ML を用いたい場合は Continuous queries を選ぶなど、選択肢が増えることとなります。
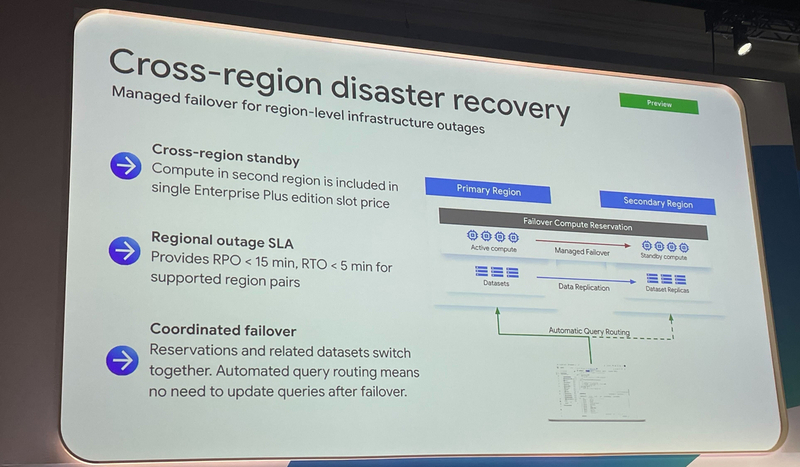
Cross-region disaster recovery(Preview)
Cross-region disaster recovery では、BigQuery でリージョンレベルの物理障害が発生した際に、セカンダリリージョンへのフェイルオーバが行われます。Enterprise Plus Edition で提供されます。コンピュート処理のフェイルオーバにより5分以下の RTO が実現されます。また、データの継続的なレプリケーションにより15分以下の RPO が実現されます。
なお、リージョン間のデータセットのレプリケーションは、2023年に発表されていました。今回の発表では、これにコンピュート処理のフェイルオーバが加わったことになります。クエリの向き先の変更は自動的に行われるため、SQL の書き換えは不要です。
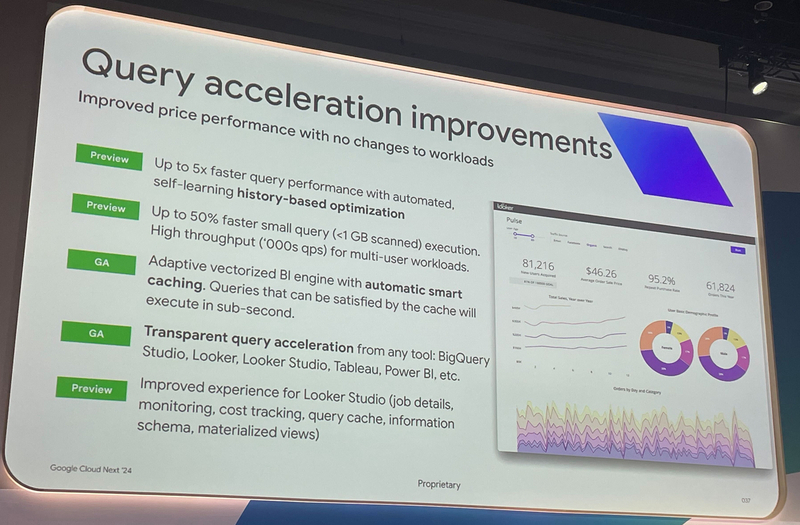
Query acceleration improvements(一部 GA、一部 Preview)
クエリのパフォーマンスや Looker Studio と BigQuery の統合に関する複数のアップデートが発表されました。
- 過去履歴からの実行計画の自動最適化。最大5倍の実行速度向上(Preview)
- 1GB 未満のスキャンを伴う小規模クエリの高速化と、複数ユーザー実行時のスループット改善(Preview)
- Automatic smart caching。BI engine で適応的なベクトル化が行われ、BI ツールからのクエリ実行を最適化(GA)
- BI ツールからの透過的なクエリ最適化。BigQuery Studio、Looker、Looker Studio、Tableau、Power BI 等に対応(GA)
- Looker Studio からの利用の最適化(ジョブ詳細、モニタリング、コスト追跡、クエリのキャッシュ、INFORMATION SCHEMA、マテリアライズドビュー)
Looker Studio との統合に関しては、Looker Studio で実行されたクエリに関する BigQuery の INFORMATION_SHEMA (システムビュー) や Cloud Logging から取得できる機能が強化されたり、マテリアライズドビューを使ったパフォーマンス向上などが発表されました。
関連記事
西島 昌太(記事一覧)
データアナリティクス準備室 データエンジニア
2023年4月に新卒入社。
元はフロントエンド開発を主戦場に、現在はデータエンジニアリングを勉強中。何でも屋さんを目指して、日々邁進。 休日は大体プログラムを書いてる人