


Google Cloud (旧称 GCP) の生成 AI チャットモデルである PaLM 2 の chat-bison モデルを使い、運用を考慮に入れたチャットツールを作成してみましたのでご紹介します。

はじめに
先日、「Googleの生成AI、PaLM 2をSlack連携して社内ツールとして導入してみた」というブログ記事で、PaLM 2 の text-bison (テキスト生成用モデル) を使用した簡易的なチャットボットアプリの開発について語りました。
その時、私は PaLM 2 の text-bison が1問1答形式の入力出力にしか対応できないと理解し、その改善点について同記事の「アプリケーションの改善」の章で取り上げました。
この課題を解決するために、当記事では使用モデルを PaLM 2 の chat-bison (チャットモデル) に切り替えましたのでご共有します。前述の記事をまだお読みになっていない方でも、本記事の内容を理解できるように、可能な限り PaLM 2 の chat-bison の説明に焦点を当てて記述します。
前提知識
Vertex AI PaLM API
PaLM 2 は Google が開発した生成 AI モデルであり、一般向けチャットツール「Bard」のバックエンドでも使用されています。モデルは Vertex AI の PaLM API として公開されており、Google Cloud 経由で有償で利用できます。
我々開発者はこの Vertex AI PaLM API を使うことで、自社アプリに生成 AI 機能を追加することができます。
今回は Vertex AI PaLM API の中でも、会話に特化した chat-bison を使用します。
Vertex AI PaLM API の詳細については、以下の記事をご確認ください。
サンプルコード (Python)
chat-bison モデルのサンプルコード (Python) は以下のリンクをご参照ください。
- Test chat prompts
- https://github.com/GoogleCloudPlatform/python-docs-samples/blob/d5ca4a4518cb20040287129624466fd36b5a646a/generative_ai/chat.py
ステートフルとステートレス
当記事では「アプリケーションの状態を維持する」という課題について述べます。アプリケーションのステートフルとステートレスについては以下のリンクをご参照ください。
運用化のポイント
運用化する際に考慮すべきポイントを2つまとめました。1つ目は、インフラの課題を解消するためにチャットボットをステートレスにすること、そして2つ目は回答を改善するためのコツです。
ポイント1: チャットボットをステートレスにする
課題
chat-bison モデルの簡単なサンプルコードは Vertex AI の Web コンソール画面の右上にある「VIEW CODE」から確認できます。
import vertexai from vertexai.language_models import ChatModel, InputOutputTextPair vertexai.init(project="thanab", location="us-central1") chat_model = ChatModel.from_pretrained("chat-bison") parameters = { "max_output_tokens": 1024, "temperature": 0.2, "top_p": 0.8, "top_k": 40 } chat = chat_model.start_chat( context="""my context""", ) response = chat.send_message("""my message no. 1""", **parameters) print(f"Response from Model: {response.text}") response = chat.send_message("""my message no. 2""", **parameters) print(f"Response from Model: {response.text}")
このコードでは、会話履歴(以下、会話のステート)は chat オブジェクトに格納されます。それにより、再度 chat.send_message 関数を呼び出した際に、過去の会話を考慮した回答が PaLM 2 から得られます。
会話のステートはこのコードを実行するインスタンスのメモリに保存されているため、ステートフルなアプリケーションになります。それにより、運用時に以下の課題が生じます。
1. スケーラビリティ
ユーザー数が増えると、会話のステートのボリュームが大きくなり、コストの高い資源であるメモリが多く必要となります。
2. フェイルオーバーと復旧
インスタンスが停止した場合、以前の会話のステートは消えてしまい、インスタンスを再開した後に会話を継続することが難しくなります。
以下のようにこの課題を再現してみます。まず chat_1 チャットセッションで私の名前を覚えさせます。その後、このコードを実行するインスタンスが停止するシナリオを再現するために、関連オブジェクトを削除しました。インスタンスが再開し、同じ会話を続けようとしたところ chat_2 チャットセッションでは私の名前は忘れられてしまいました。

解決策
考え方
以下のコードのように、チャットオブジェクトの ._message_history 属性を何処かに保存しておき、再度チャットのオブジェクトを作成する際に chat_model.start_chat 関数の引数として用いることで、会話を再開した後も会話を継続することが可能になります。
Python SDK においては、チャット履歴の内容はチャットオブジェクトの ._message_history 属性に保存されています。これはドキュメントには明記されていません (当記事を書いた理由の一つは、この発見のご共有です)。
ここでは、可読性のために会話のステートを my_historical_chat という変数に保存しました。

変数 my_historical_chat の内容はこのようになります。

運用性の検証
では、次に外部のデータストレージに会話のステートを保存し、それを復元してみましょう。
データを保存できるサービスは様々ありますが、今回は安価に利用できる Cloud Storage (以下、GCS) に保存し、ステートレス化します。会話のステートを GCS バケットに書き込み、後で読み込む動作を次のように行います。GCS バケットは事前に作成済みの前提です。
まず、以下のように会話のステートをシリアル化してから、GCS バケットに書き込みます。ここで利用している pickle は、Python オブジェクトをシリアル化 (シリアライズ = 直列化。バイト列に変換することでファイル保存等を可能にする) するための Python 標準モジュールです。
import pickle from google.cloud import storage import vertexai from vertexai.language_models import ChatModel # パラメータ設定 bucket_name = "historical-chat-object" destination_blob_name = "会話識別番号_001.pkl" parameters = { "max_output_tokens": 1000, "temperature": 0.2, "top_p": 0.95, "top_k": 40 } # 関数宣言 def upload_blob(bucket_name, source_file_name, destination_blob_name): """Uploads a file to the bucket.""" storage_client = storage.Client(credentials = credentials) bucket = storage_client.bucket(bucket_name) blob = bucket.blob(destination_blob_name) blob.upload_from_string(source_file_name) def serialize_to_pickle(python_object): # Serialize the Python object to a pickle serialized_object = pickle.dumps(python_object) return serialized_object # アプリ vertexai.init(project="thanab", location="us-central1", credentials = credentials) # あるユーザーがチャットセッションを開始 chat__1 = chat_model.start_chat() response = chat__1.send_message("""my name is thana""", **parameters) response = chat__1.send_message("""my age is 30""", **parameters) response = chat__1.send_message("""what is my name""", **parameters) print(f"Response from chat__1: {response.text}") my_historical_chat = chat__1._message_history # 会話のステートをシリアル化 serialized_chat_state = serialize_to_pickle(my_historical_chat) # GCSへアップロード upload_blob(bucket_name, serialized_chat_state, destination_blob_name)
上記のコードを実行すると、このように GCS バケットに会話のステートがアップロードされました。

次は、このステートを読み込んで会話を再開するコードです。
import pickle from google.cloud import storage import vertexai from vertexai.language_models import ChatModel bucket_name = "historical-chat-object" source_blob_name = "会話識別番号_001.pkl" def download_blob(bucket_name, source_blob_name): """Downloads a blob from the bucket.""" storage_client = storage.Client(credentials = credentials) bucket = storage_client.bucket(bucket_name) blob = bucket.blob(source_blob_name) return blob.download_as_bytes() def deserialize_from_pickle(serialized_object): # Deserialize the object from a pickle python_object = pickle.loads(serialized_object) return python_object # GCS から会話のステートをダウンロード serialized_object = download_blob(bucket_name, source_blob_name) # シリアル化された会話のステートを逆シリアル化し、使える形にする my_loaded_historical_chat = pickle.loads(serialized_object) vertexai.init(project="thanab", location="us-central1", credentials = credentials) # インスタンス再開 chat_model = ChatModel.from_pretrained("chat-bison@001") # ユーザーが続いて会話する chat__2 = chat_model.start_chat(message_history = my_loaded_historical_chat) response = chat__2.send_message("""what is my name""", **parameters) print(f"Response from chat__2: {response.text}")
上記のコードを実行すると、私の名前を覚えていて会話を継続できることが確認できます。

応用
チャットボットに適用するシナリオを以下のように考えてみます。会話識別番号ごとに、会話のステートを管理します。そのために、会話の識別番号を GCS オブジェクト名にして会話のステートを保存します。
過去の会話ステートの有無の確認は、会話の識別番号に一致する GCS オブジェクトの有無で確認します。Slack でチャットボットを開発する場合、Slack のスレッド番号を会話識別番号として利用できるでしょう。

ポイント2: 回答スタイルを指定
概要
PaLM 2 のデフォルトの出力スタイルは簡潔なものです。より記述的な回答が望ましい場合は、入出力の例を指定することで、希望に近い出力スタイルを引き出すことができます。
入力出力例の有無によって、回答がどのように変わるか見てみましょう。
入出力例がない場合

入出力例がある場合

やり方
Google Cloud 公式の GitHub レポジトリを参考にして以下のように試しました。
1. 入出力例を用意
オリジナルで作成しても構いませんが今回は Hugging Face からいくつかのサンプルを拾って利用しました。一つをピックアップすると、以下のようなものです。
example_1_ja_output = """印刷された新聞とオンラインニュースメディアの強みと弱みは、多くの面で比較することができます。以下にそれぞれの面について詳しく説明します。
内容
印刷された新聞は、選択された記事を深く言及し、詳細な調査報告を提供することができます。一方、オンラインニュースメディアは、新しい情報にアクセスする速度が速く、即座に編集することができます。また、オンラインニュースメディアは、読者が自由に記事を共有できるため、より幅広い読者層に到達することができます。配信方法
印刷された新聞は、紙を介して届けられるため、読者が手に取って読むことができます。しかし、紙のニュースメディアは、定期的な配信サイクルに従う必要があります。一方、オンラインニュースメディアは、広範なデバイスで直接アクセスでき、随時更新されます。また、オンラインニュースメディアは、記事を即座に共有することができるため、情報の速度が向上します。対象読者
印刷された新聞は、購読者を対象にしています。しかし、オンラインニュースメディアは、より広範な読者層に到達することができます。特に、若い読者は、オンラインニュースメディアを使用することが多いです。広告モデル
印刷された新聞は、大部分の収益を広告から得ています。しかし、紙のニュースメディアは、競合が増える中で広告料が下がっています。一方、オンラインニュースメディアは、デジタル広告モデルを使用して収益を得ています。これは、読者層に対するターゲット広告を提供することができるためです。社会への影響
印刷された新聞は、コミュニティとのつながりにおいて重要な役割を果たしています。また、新聞社による深く詳細な調査報道は、社会問題の解決に役立ちます。一方、オンラインニュースメディアは、情報へのアクセス性が向上することで、より多くの読者層を影響することができます。バイアスの可能性
印刷された新聞には、報道規模の制限があります。報道の範囲や、編集方針によっては、バイアスが生まれる可能性があります。一方、オンラインニュースメディアは、より多岐にわたる記事を提供しており、バイアスの可能性を減らすことができます。第2のJSONコードを使用することで、デジタルジャーナリズムの移行の影響を評価することができます。多段階の推論プロセスを組み込むことで、印刷メディアが直面する課題について検討し、競争力を維持するための新しい戦略を探索することができます。このプロセスには、将来の印刷メディアの不確実性とイノベーションの必要性についても認識することが含まれます。"""
上記の入出力例をチャットモデルが使える形にします。
from vertexai.language_models import InputOutputTextPair examples = [ InputOutputTextPair( input_text=example_1_ja_input, output_text=example_1_ja_output, ), InputOutputTextPair( input_text=example_2_ja_input, output_text=example_2_ja_output, ), InputOutputTextPair( input_text=example_3_ja_input, output_text=example_3_ja_output, ), ]
2. examples を chat_model.start_chat 開始時に渡す
上記コードで作成した examples 配列オブジェクトを chat_model.start_chat 関数に引き渡します。
chat = chat_model.start_chat(examples = examples) response = chat.send_message("""円高とは""", **parameters) print(f"Response from Model:\n{response.text}")
動作確認
前回の記事「Googleの生成AI、PaLM 2をSlack連携して社内ツールとして導入してみた」を書く際に開発したアプリへ、上記のロジックを適用してみました。会話が継続しており、かつ記述的な回答が得られている様子が確認できました。
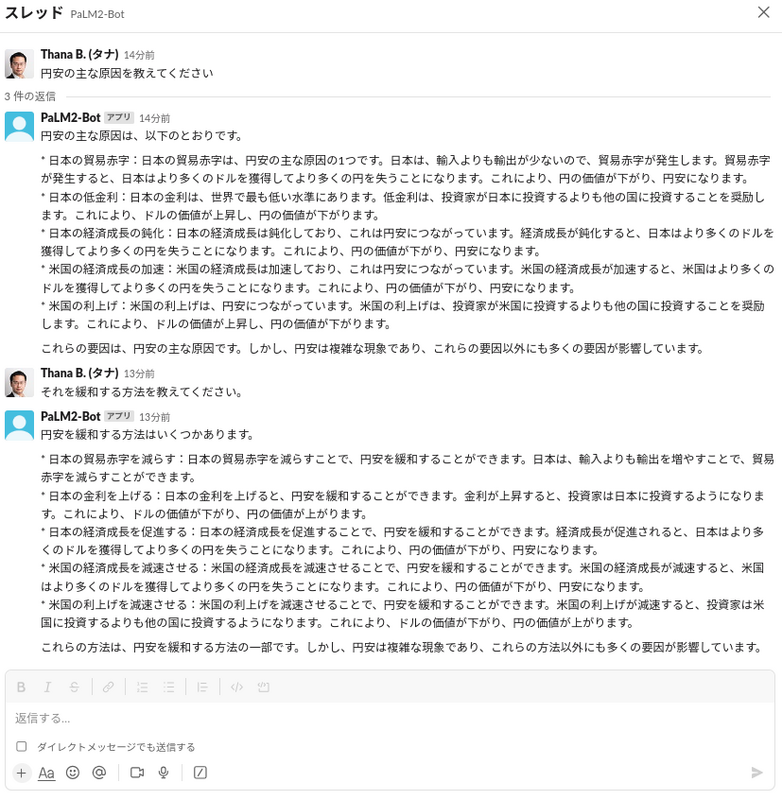
上記の例では、私の2つ目のプロンプトでは「それを」という曖昧な表現を使いました。それでも PaLM 2 の chat-bison がちゃんと過去の会話の内容を考慮して回答を返してくれました。
トラブルシューティング
読者が再現する際に起こり得る他のトラブルシューティングを以下のようにまとめました。
初期設定
Slack チャットボットのアーキテクチャや初期設定に興味がある方は以下のリンクをご参照ください。
ロジック適用
開発コードに興味がある方は、以下のレポジトリを確認することができます。
バックエンドフレームワークはSlackと連携する専用のPythonライブラリを利用しています。該当ライブラリについては以下のURLをご覧ください。
https://slack.dev/bolt-python/concepts
GitHub - slackapi/bolt-python: A framework to build Slack apps using Python · GitHub
FastAPI を App Engine でデプロイ
FastAPI のアプリを開発環境で実行する際、次のコマンドで実行できます。
uvicorn app:api --port 8080
しかし App Engine などの運用環境では、uvicorn でアプリをデプロイするとエラーが発生することがあります。その解決策として App Engine の app.yaml を用意する際に次のコマンドを entrypoint として指定すると、無事にアプリをデプロイすることができます。
gunicorn -w 2 -k uvicorn.workers.UvicornWorker -b 0.0.0.0:8080 app:api
-w と uvicorn.workers.UvicornWorker はそれぞれワーカー数とワーカークラスを指定するものです。
また instance class が F1 の場合、ワーカー数を2個に指定すれば無事に動作することを確認しました。その値を超えた場合、リソースが不足し、アプリがダウンする可能性があります。
当記事についてご興味を持たれ、自社でも実装してみたい場合は、G-gen の Web サイトからお気軽にお問い合わせください。
G-gen 編集部 (記事一覧)
株式会社G-genは、サーバーワークスグループとして「クラウドで、世界を、もっと、はたらきやすく」をビジョンに掲げ、クラウドの導入から最適化までを支援している Google Cloud 専業のクラウドインテグレーターです。