


G-genの杉村です。当記事では、AI エージェント時代に対応する次世代データ基盤アーキテクチャとして「メダリオンアーキテクチャ 2.0」と、その中核をなす「プラチナレイヤー」をGoogle Cloudで実現する方法を解説します。

はじめに
概要
当記事では、AI エージェント時代のデータ基盤の新たなあり方として、従来のメダリオンアーキテクチャを進化させた「メダリオンアーキテクチャ 2.0」というコンセプトについて、筆者の視点から再整理し、その具体的な実装方法と共に論じます。
そして、その中核となる「プラチナレイヤー」の概念と、Google Cloud でどのように実現するかを解説します。
メダリオンアーキテクチャ 2.0 は、Google Cloud Japan 公式の Zenn Publication(ブログ)の記事「AIエージェントが真価を発揮するデータ基盤へ -メダリオンアーキテクチャ 2.0 と "プラチナレイヤー" を考える」で提唱されました。当記事では、このアーキテクチャのうちリアルタイムデータやガバナンスなどの責務を分離して再定義したうえで紹介しています。
メダリオンアーキテクチャとは
メダリオンアーキテクチャは、データレイクハウス内のデータを3つの論理的な層(レイヤー)で段階的に処理し、品質と価値を高めていくアプローチです。
メダリオンアーキテクチャを提唱したのは米国の Databricks 社です。同社の製品である Databricks は、クラウド型の統合データプラットフォーム製品であり、データの変換・保存・管理・可視化・分析などを総合的に扱うことができます。2013年に Databricks 社が設立されて以降、データ分析基盤の構築にあたり高い存在感を持っています。
このアーキテクチャでは、基盤に保存されるデータを3つの抽象的なレイヤーに分類します。
1. ブロンズレイヤー
未加工データを保存するレイヤー。ソースシステムのデータをそのまま保管する。後のレイヤーのためにデータを加工しても、ブロンズレイヤーには生のデータを保持しておく。
2. シルバーレイヤー
ブロンズレイヤーのデータを変換・抽出してある程度の整備を施したもの。顧客マスタ、店舗マスタ、重複排除済みのトランザクションデータなど。アドホックな分析や機械学習への利用などが可能。
3. ゴールドレイヤー
シルバーレイヤーのデータにさらに加工を施したもの。より非正規化され、キュレート(目的に応じて整備)されており、より多くのユーザーから利用される準備ができている。
レイヤーが進むごとにデータの価値が向上する様を、ブロンズ、シルバー、ゴールドといったメダルになぞらえていることから「メダリオン(Medallion)」アーキテクチャと名付けられています。
なおこれらのレイヤーは、書籍等では以下のように呼称されることもあります。呼び名が異なっても、ほとんど同じ概念と捉えることができます。
- ブロンズレイヤー -> データレイク層
- シルバーレイヤー -> データウェアハウス層
- ゴールドレイヤー -> データマート層
Databricks では、Cloud Storage(Google Cloud)や Amazon S3(AWS)などのクラウドストレージサービスと連携しながら、Apache Spark 等を基盤技術として、上記のレイヤーを実現しています。
AI エージェント時代のメダリオンアーキテクチャ
2022年末ころに ChatGPT がブームになってから2025年7月の現在に至るまで、生成 AI は日常業務レベルにまで発展・普及しました。最近では、AI が人間の代わりにタスクを行う AI エージェントの活用が盛んに論じられるようになっています。AI エージェントは早晩、日常業務で人間を助けるようになっていくでしょう。
AI エージェントは人間の指示に基づき、データを読み込んでコンテキストとして利用したり、あるいは SQL や API リクエストを生成してデータを取得し、自動で分析したり、人間にデータを提供するようになっていきます。AI エージェントはデータ分析基盤に存在する前述の各レイヤーからデータを取得して、利用したり、人間のためにデータを提供することになります。
AI エージェントの発展に伴い、前掲の Google Cloud Japan 公式の Zenn Publication(ブログ)で公開された以下の記事では、AI が自律的にデータを活用しやすくなるよう、第4のレイヤーであるプラチナレイヤーを提唱しています。
今回は、このプラチナレイヤーを深堀りし、前述の記事が提唱する新しいアーキテクチャである「メダリオンアーキテクチャ 2.0」を論じます。
アーキテクチャ
メダリオンアーキテクチャ(従来)
まず、Google Cloud を主な基盤としてメダリオンアーキテクチャを実現した場合の一例を以下の図に示します。
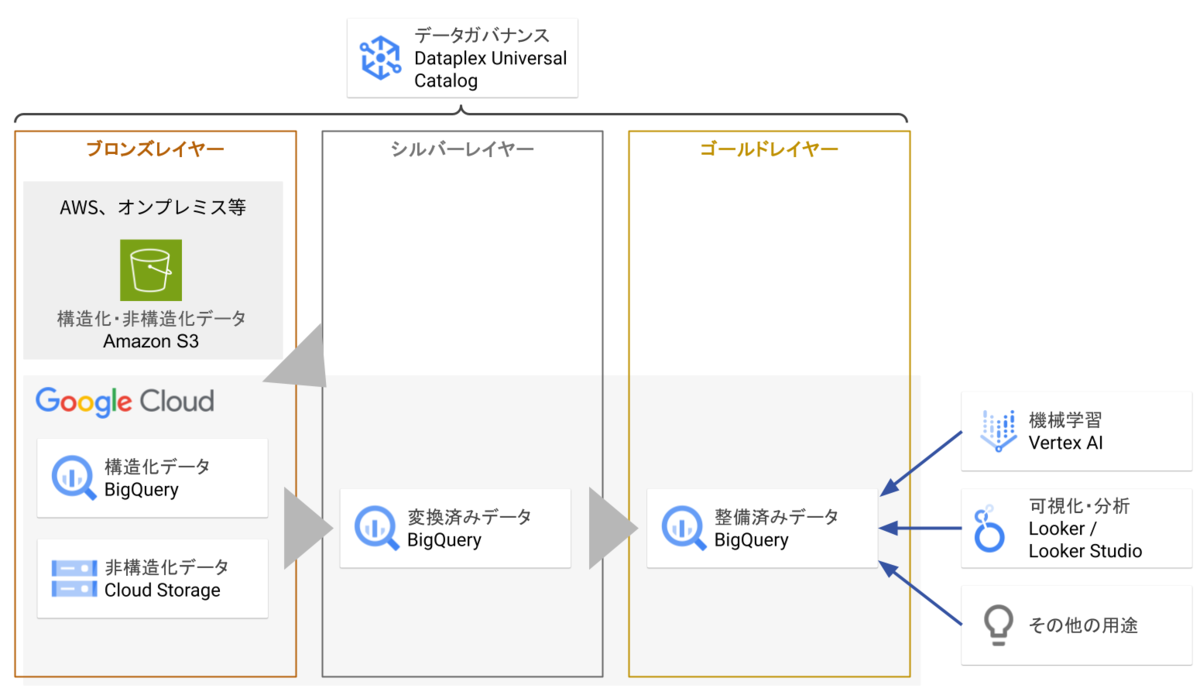
多くの組織では、元データを持つシステムはオンプレミス、Amazon Web Services(AWS)、Google Cloud など、複数のプラットフォームに分散しています。よってブロンズレイヤーは、Amazon S3、Cloud Storage、BigQuery などに分散している可能性があります。これらの分散したデータを1つの抽象レイヤーとして管理するには、サードパーティ製品や、Dataplex Universal Catalog(旧称 Dataplex Data Catalog)でメタデータを管理しつつ、OIDC/SAML を用いた認証情報の連携などが必要になります。
シルバーレイヤーとゴールドレイヤーは、BigQuery で構成します。
各レイヤー間のデータ移送、変換は、Dataform と呼ばれる Google Cloud ネイティブな SQL ベースのワークフローツールや、サードパーティのワークフロー管理ツールなど、様々な候補が挙げられます。
また、Amazon S3 から Cloud Storage や BigQuery へのデータ移送には、BigQuery Data Transfer Service を用いたり、BigQuery Omni(ただし東京・大阪リージョンの Amazon S3・BigQuery には未対応)などを用いることができます。
このようなメダリオンアーキテクチャ型のデータ分析基盤は、2010年代以降、多くの組織で Google Cloud を使って実装されてきました。
メダリオンアーキテクチャ 2.0
前述の記事「AIエージェントが真価を発揮するデータ基盤へ -メダリオンアーキテクチャ 2.0 と "プラチナレイヤー" を考える」では、従来型のメダリオンアーキテクチャにプラチナレイヤーを加え、このレイヤーに以下のような機能を持たせています。
| 機能名 | 概要(前述記事からの引用) |
|---|---|
| セマンティックレイヤー | 「売上」「利益」「顧客数」といったビジネス指標とその計算方法、データ間の関係性を定義した「意味の辞書」 |
| ナレッジグラフ(データの相関関係) | データ同士の「関係性」をグラフ構造で表現したもの |
| ガバナンス | AI エージェントの自律的なデータ利用を、安全かつ透明性の高い形で実現するためのガードレール |
| マルチモーダルデータ | 契約書(PDF)、議事録(Docs)、画像、音声、動画などの非構造化・半構造化データ |
| リアルタイムデータ | 顧客の行動、IoTセンサー、ログデータといったストリーミングデータのリアルタイムな取り込み |
上記は、AI エージェントからデータを利用するにあたり有用です。しかしながら当記事では、メダリオンアーキテクチャの各層の命名の意味合いに鑑みて、以下のように整理しなおしました。
- セマンティックレイヤー、ナレッジグラフ、マルチモーダルデータ => プラチナレイヤー
- リアルタイムデータ => ブロンズレイヤーの追加インターフェイス
- ガバナンス => 全レイヤーのガバナンス補強
セマンティックレイヤー、ナレッジグラフ、マルチモーダルデータについては、ゴールドレイヤーのデータに価値を付加するという意味において、プラチナレイヤーと呼称するにふさわしいと考えます。
リアルタイムデータについては、加工前の生データとして最初にデータ基盤へ流入することが多いため、ブロンズレイヤーの責務としました。
ガバナンスはデータの発生から活用までのライフサイクル全体で一貫して適用されるべき原則であり、特定のレイヤーに限定されるものではないため、横断的な機能として捉え直しました。
当記事では上記の考えに基づき、先行記事で論じられたメダリオンアーキテクチャ 2.0 を捉え直します。
これを構成図に反映すると、以下のようになります。
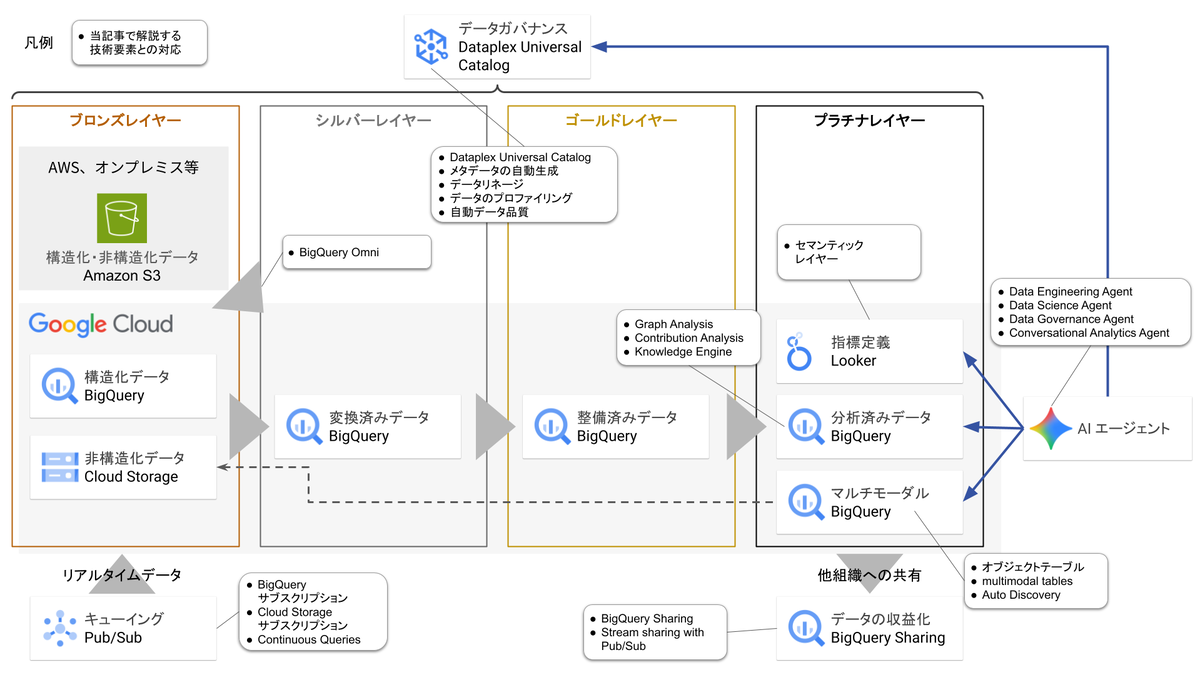
図に掲載されているサービスを、かならずしもすべて実装する必要はありません。必要に応じて追加の実装を行い、データの入口を追加したり、プラチナレイヤーを実装すればよいことになります。
実装
プラチナレイヤー
セマンティックレイヤー
セマンティックレイヤーの実装に当たっては、Google Cloud のデータプラットフォームおよびデータ分析・可視化ツールである Looker を使うことができます。
Looker で定義されたディメンションやメジャー(指標)を、AI 等から利用できるようにします。Looker に付帯の Gemini for Looker では、自然言語の指示により、AI がデータを可視化したり、AI にデータを分析させることができます。
Looker の大きな特徴は、LookML という仕組みにより共通のディメンションやメジャーを定義できる点です。「売上」「粗利」「営業利益」「顧客数」といった指標の意味を LookML で集中管理することで、データの解釈に齟齬がでないように統一できます。
Looker のディメンションやメジャー、また Gemini in Looker には、API 経由でアクセスすることができます。これにより、AI エージェントから、セマンティックレイヤーを経由してデータにアクセスさせることが可能になります。
ナレッジグラフ
ナレッジグラフは、データの相関関係を管理する仕組みです。Google Cloud サービスを使った、いくつかの実装が考えられます。
BigQuery Graph Analysis
BigQuery Graph Analysis は、BigQuery 上のデータに対して GQL(Graph Query Language)と呼ばれるグラフクエリ言語を実行できる機能です。2025年7月現在、まだ利用可能になっておらず、将来リリースされる予定です。
これによりデータ間の関係性を可視化することができ、関係性の情報を保持しておくことで、AI がデータ間の関係性を理解して適切なインサイトを提供するのに役立ちます。
BigQuery Contribution Analysis
BigQuery では、簡単に貢献度分析(Contribution Analysis)が可能です。この機能では、BigQuery ML を使って貢献分析を行う機械学習モデルをトレーニングし、ある多次元データにおいて主要な指標が変化した際に、どういったデータがその変化に貢献したのかを分析することができます。
これによりデータ間因果関係という関係性を可視化するのに役立ち、ナレッジグラフの構成に繋がります。
- 参考 : 貢献度分析の概要
BigQuery Knowledge Engine
BigQuery Knowledge Engine は2025年7月現在、未公開ですが、将来のリリースが予告されています。BigQuery knowledge engine は、複数テーブルにまたがるクエリの提案や、自然言語による質問への回答などにより、複数のデータセットやテーブルの間の関係性を可視化し、把握するための機能です。エンティティ間の関係性をグラフで表現し、データ間の繋がりを可視化したり、テーブルをまたいだクエリをサジェストできます。
この機能では、テーブル間の意味的な関係性を可視化し、ナレッジグラフを構成することに繋がります。
マルチモーダルデータ
BigQuery オブジェクトテーブル
BigQuery にはオブジェクトテーブルと呼ばれるタイプのテーブルがあります。BigQuery のテーブルにあたかも動画、画像、音声などの非構造化データを格納したかのように扱い、分析したり、BigQuery ML で機械学習のトレーニングや推論に使うことができます。実際にはテーブルには非構造化オブジェクトのメタデータが格納されており、データの実体は Cloud Storage バケットに格納されます。
- 参考 : オブジェクト テーブルの概要
BigQuery multimodal tables
BigQuery multimodal tables は、前述のオブジェクトテーブルよりもさらに構造化データと非構造化データの統合を推し進めたものです。ObjectRefs 型の値をテーブルに持つことで、非構造化データを BigQuery の標準テーブルに持たせることができます。こちらも、データの実体は Cloud Storage に格納されます。標準テーブルに非構造化データを統合できるため、構造化データと組み合わせた分析や BigQuery ML からの利用、Python ライブラリである BigQuery DataFrames からの利用など、より分析の利便性が向上します。当機能は、2025年7月現在、Preview 公開です。
BigQuery Auto Discovery
BigQuery Auto Discovery は、Cloud Storage 上の非構造化データを自動で検出して、BigQuery オブジェクトテーブルを作成する機能です。バックエンドでは Dataplex が使われています。
追加インターフェイス
リアルタイムデータ
Pub/Sub の BigQuery サブスクリプション
Pub/Sub は、フルマネージドのメッセージキューサービスです。BigQuery サブスクリプション機能を使うと、Pub/Sub に発行(パブリッシュ)されたメッセージを、直接 BigQuery に書き込むことができます。メッセージを受け取って BigQuery に書き込むプログラムは必要ありません。
Pub/Sub の Cloud Storage サブスクリプション
Pub/Sub の Cloud Storage サブスクリプション機能を使うと、Pub/Sub に発行(パブリッシュ)されたメッセージを、直接 Cloud Storage に書き込むことができます。こちらも、メッセージを受け取って Cloud Storage に書き込むプログラムを作成する必要はありません。
BigQuery の Continuous Queries(継続的クエリ)
BigQuery の Continuous Queries(継続的クエリ)を使うと、BigQuery テーブルに到着したデータ(レコード)に対して決まった処理(SQL)を実行することができます。BigQuery ML を使った推論を行わせることもできます。これにより、スケジュール実行でクエリを実行するよりも少ない考慮事項(どこまで処理したか、バックフィルなど)で継続的処理を実装できます。
情報のシェア・販売
BigQuery Sharing
BigQuery Sharing(旧称 Analytics Hub)は、BigQuery のデータセットを、他の組織に安全に共有したり、販売して収益化するための機能です。従来は Analytics Hub と呼ばれていましたが、2025年4月に改名されました。データクリーンルーム機能により、きめ細かいアクセス制御を設定することができます。また Google Cloud Marketplace を通じて、データを販売して収益化することができます。
Stream sharing with Pub/Sub
Stream sharing with Pub/Sub は、Pub/Sub トピックを異組織間でシェアするための仕組みです。リアルタイムデータを別の組織に共有したり、逆に共有を受けることができます。基盤として BigQuery Sharing(旧称 Analytics Hub)の仕組みを利用しています。
- 参考 : Pub/Sub を使用したストリーム共有
ガバナンス補強
メタデータ管理
Dataplex Universal Catalog(旧称 Dataplex Catalog)は、BigQuery や Cloud Storage などの Google Cloud サービス、およびサードパーティのストレージに格納されたメタデータを管理するフルマネージドサービスです。
BigQuery のデータセットやテーブルの説明(Description)、Pub/Sub トピックの情報などは自動的に収集され、Dataplex Universal Catalog の画面から検索・表示可能です。
さらに Dataplex Universal Catalog は、Cloud Storage 内のデータを検出して外部テーブルや BigLake テーブル、オブジェクトテーブルなどとして定義する Data Discovery 機能も備えています。
メタデータの自動生成を使うと、BigQuery テーブルやそのカラムに対して、AI によりメタデータを自動生成できます。メタデータの整備は人間にとって重要であることに加えて、AI がデータを適切に取得して分析手法を確立するために必須です。
- 参考 : Generate data insights in BigQuery - Generate table and column descriptions
- 参考 : BigQueryのメタデータ自動生成を解説 - G-gen Tech Blog
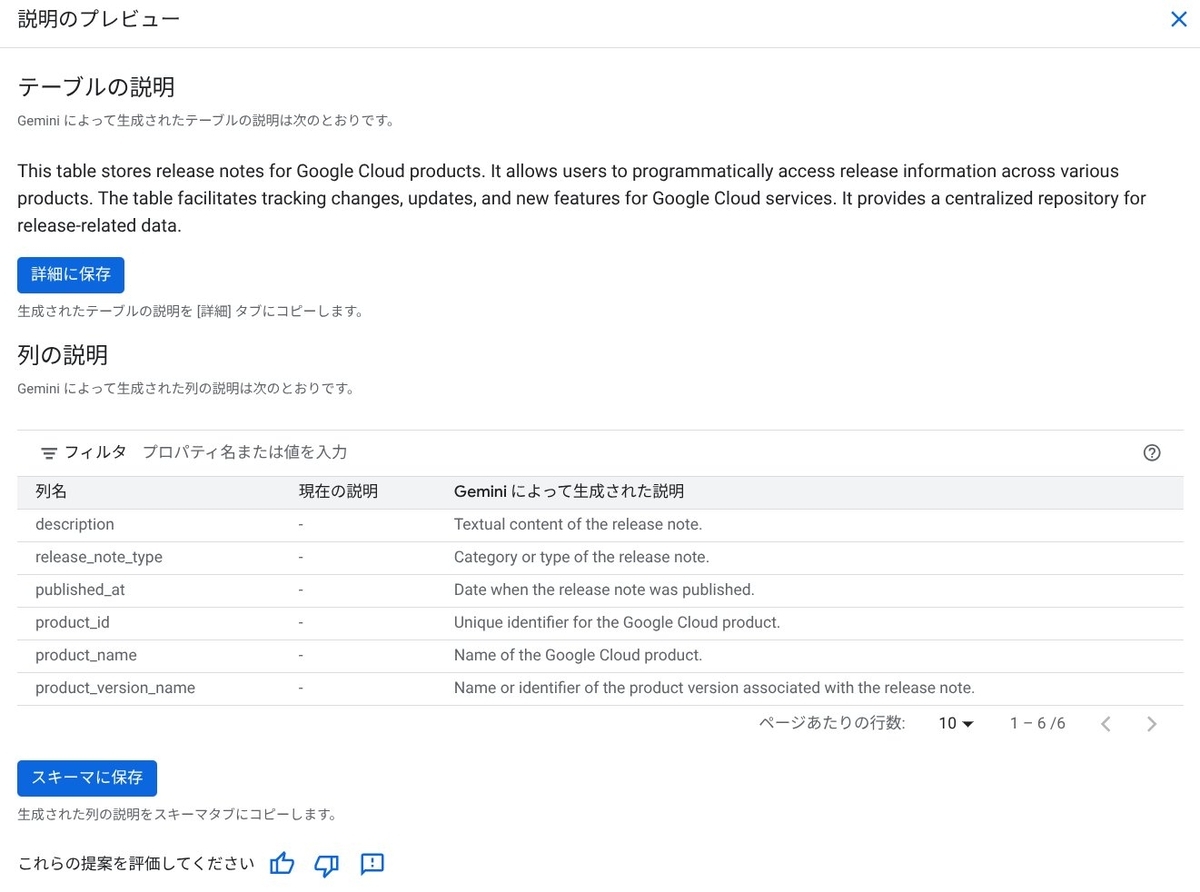
データリネージ
Google Cloud プロジェクトで所定の API を有効化するだけで、BigQuery のデータリネージを記録・可視化することができます。BigQuery テーブルに対して実行された COPY、CREATE、INSERT SELECT、MERGE、UPDATE などが自動的に記録され、リネージグラフとして表示可能です。
- 参考 : データリネージについて

データのプロファイリング
Dataplex Universal Catalog を使って BigQuery のテーブルに対してデータプロファイリングを行うと、null 値の割合、近似値の割合、平均値や標準偏差、最小値など、テーブルの統計的な情報を簡単に生成できます。
この情報は AI がデータの特性を把握するために重要になります。
- 参考 : データ プロファイリングについて

自動データ品質
Dataplex Universal Catalog の自動データ品質機能は、定義済みのルールに基づきデータのスキャンを自動化し、データの品質要件を満たさない場合にはアラートを記録・発報する機能です。
AI が正しいデータに基づいて分析ができるよう、可能な限り品質担保を自動化することができます。
- 参考 : 自動データ品質の概要
AI エージェント
4つのデータエージェント
メダリオンアーキテクチャ 2.0 は、AI エージェントがデータを活用できるように、従来型のメダリオンアーキテクチャに追加の実装を施したものです。
前述の記事では、データ基盤を利用する AI エージェントとして以下を紹介しています。
- Data Engineering Agent
- Data Science Agent
- Data Governance Agent
- Conversational Analytics Agent
これらは、2025年4月に米国ラスベガスで行われた Google Cloud Next '25 でもコンセプトが紹介されました。
Data Engineering Agent
Data Engineering Agent は、データエンジニアのタスクを代替したり、支援したりするエージェントです。自然言語の指示に基づいて、データパイプラインを生成したり、開発を支援します。
この実装の1つとして、BigQuery data preparation があります。BigQuery data preparation では、GUI 操作と自然言語での AI への指示により、容易に ELT パイプラインを構築できます。

- 参考 : BigQuery データの準備の概要
Data Science Agent
Data Science Agent は、データサイエンティストを支援したり、あるいはビジネスユーザーが容易にデータ分析を行えるように支援するエージェントです。
実装の1つとしては、BigQuery データキャンバスがあります。自然言語で AI に指示を出すと、AI が BigQuery データセットの中から必要なテーブルを結合してクエリし、可視化までを行います。

Data Governance Agent
Data Governance Agent はデータガバナンスを強化するエージェントです。これに関しては Google Cloud ネイティブの機能としてはまだ実装途中です。実装済みのものとして、前述のメタデータ自動生成などが挙げられます。また、BigQuery のデータ分析情報(Data insights)の生成には、Gemini が使われています。
Conversational Analytics Agent
Conversational Analytics Agent は、AI との自然言語での対話を通じてデータを分析するエージェントです。
BigQuery の Conversational Analytics(対話型分析)機能を使うと、BigQuery のテーブルに対して、自然言語を使ってクエリや可視化、分析を行うことができます。
また、Looker や Looker Studio Pro に付帯する Gemini in Looker でも、Conversational Analytics 機能が使用可能です。対話的にエージェントに指示を出して、データの可視化や分析を行わせることができます。
- 参考 : Gemini in Looker
- 参考 : 会話分析: 自然言語でデータにクエリを実行する
独自エージェントの実装
前述の4つのデータエージェントは、Google Cloud Next などで繰り返し謳われているものの、まだいずれもコンセプチュアルなものです。また製品化しても、多くの場合でまずは英語版がリリースされ、日本語対応版は数カ月の遅れをもってリリースされます。
早期に日本語に対応した、あるいは自社特有の業務ドメインに対応した AI エージェントを実装したい場合、私たちユーザーは、以下のような Google Cloud サービスを利用することができます。
- Vertex AI 経由で提供される Gemini や Claude などのサードパーティモデル
- マルチエージェント開発のための Python フレームワークである Agent Development Kit(ADK)
- エージェントをホストするフルマネージドプラットフォームである Vertex AI Agent Engine や Cloud Run
上記のようなサービスを使い、Google Cloud のエコシステムに閉じて AI データエージェント開発を行うことで、エージェントからデータへの認証機構がシンプルになるほか、データ転送料金やネットワークレイテンシを抑えることができます。以下の記事も参考にしてください。
- 参考 : 全Geminiプロダクトを徹底解説! - G-gen Tech Blog - Generative AI on Vertex AI
- 参考 : Agent Development Kitでエージェントを開発してAgent Engineにデプロイしてみた - G-gen Tech Blog
- 参考 : 入門!Cloud Runのススメ - G-gen Tech Blog
データの民主化へ
ユーザーへのデータ解放
生成 AI ブーム以前から、データの民主化というキーワードは謳われてきました。Google Cloud には、これを強力に後押しする機能が多数備わっています。
BigQuery(ゴールドレイヤー、プラチナレイヤー)に保存されているテーブルデータへの直接クエリはもちろん、今回プラチナレイヤーに分類した Looker の Explorer 機能を用いたオンデマンドなデータ探索は、データの民主化に繋がります。
また、Google Workspace のアプリの1つである Google スプレッドシートには、コネクテッドシートと呼ばれる機能があります。これは、スプレッドシートと BigQuery を接続し、BigQuery テーブル内のデータをスプレッドシートに吸い上げ、処理可能にする機能です。SQL の知識がないビジネスユーザーでも、使い慣れた Excel ライクなインターフェイスでデータを可視化できます。
このように Google Workspace は、ゴールドレイヤーやプラチナレイヤーのデータへのユーザーインターフェイスになり得ます。
スプレッドシートと AI
さらに、スプレッドシートに組み込みの AI 関数を用いることで、スプレッドシート上のデータに対して生成 AI モデル Gemini による推論・生成を実行できます。
このように Google 製品を組み合わせることで、データの民主化や AI の民主化の助けになるといえます。
プラチナレイヤーとデータの民主化
プラチナレイヤーを整備することで、AI エージェントがデータを解釈しやすくなり、AI エージェントを利用する人間の利便性向上に繋がります。
当記事で解説したメダリオンアーキテクチャ 2.0、特にAIが意味を理解し自律的に活用できるプラチナレイヤーを整備したり、メタデータ整備を始めとするデータガバナンスを強化することで、単なるデータやツールの解放に留まらず、人と AI エージェントの協働による、進化したデータの民主化を実現する鍵となると考えられます。
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it