


G-gen の杉村です。 BigQuery の Scheduled Query (スケジュールされたクエリ) で自動実行するクエリの、ジョブ失敗通知を行う方法について解説します。

はじめに
Google Cloud (旧称 GCP) のデータウェアハウスサービスである BigQuery には Scheduled Query という機能が存在します。別名をスケジュールされたクエリ、あるいはクエリのスケジューリングと言います。この機能では定期的に BigQuery 上で SQL を実行することができ、この機能の利用自体に料金は発生しません (通常通りの BigQuery 料金のみが発生します)。
この機能では、前後関係や分岐のある複雑なジョブ管理はできないものの、日時を指定して定期的に SQL が実行できるため、簡易的な ELT 処理やデータマートテーブル作成などを行わせることができます。
しかしこの機能を使うに当たって課題となるのが、ジョブが失敗したときの通知です。当記事では、 Scheduled Query を使った際の失敗通知について解説します。
- 参考 : クエリのスケジューリング
3つの方法
1. メール通知機能
Scheduled Query には、ジョブが失敗した際にメールを送信する機能が備わっています。

多くの方が、これを第一の選択肢として考えるはずです。
しかしながら、この機能は ジョブ作成者の Google アカウントのメールにしかメールが送信できない という仕様があります。
ドキュメントではワークアラウンドとしてメールを自動転送する方法が記載されていますが、これだとジョブ作成者のアカウントが退職等で削除されたときに通知ができなくなってしまいます。
- メール通知 (このリンクは BigQuery Data Transfer Service のドキュメントですが、 Scheduled Query は同サービスの一部です)
ジョブの失敗通知は、監視チームのメーリングリストであったり、インシデント管理ツールやチャットツールへの通知が必要になってくるでしょう。
そのようなニーズに、このデフォルト通知機能では答えることができません。
2. Pub/Sub
もう一つの方法として、 Pub/Sub への通知が挙げられます。
前掲のスクリーンショットにあるように、ジョブの成功/失敗通知は Cloud Pub/Sub に通知することができます。
しかしながら Pub/Sub からメッセージを読み出すには、 Cloud SDK 等を用いる必要があり、基本的にはノーコードで実現できません。
Pub/Sub から Push 型で直接メール通知を発出する方法は 2022 年 1 月現在では存在しないため、例えば Pub/Sub トリガの Cloud Functions を作成してメール/チャットへ連携するなど、通知の仕組みを別途作成する必要があります。
Scheduled Query をそもそも、手軽にデータ変換を行うために利用しているのだとすれば、このような手間のかかる実装は選択肢としては選びづらいかもしれません。
その場合は次に挙げる代替案を検討します。
3. ログベースの指標
次の方法は、ログベースの指標とアラートを用いることです。
Scheduled Query (BigQuery Data Transfer Service) はジョブ実行の結果を Cloud Logging へ出力しています。
成功時・失敗時ともにログを出力します。エラー時のログは以下のようなものです。

このエラーログを検知して通知することが一つのワークアラウンドになりそうです。
この方法は簡単に実装できるため、以降当記事では、ログベースの指標とアラートを用いた通知の実装方法を紹介していきます。
※なお特定ログを検知してアラートを発報する方法としては、今回ご紹介する「ログベースの指標 + アラート」よりもさらに簡単に実装できる ログベースのアラート 機能があります。こちらは執筆当時の 2021 年 12 月現在ではプレビュー機能だったため採用しませんでしたが、現在は GA されています。
ログベースの指標とアラートの作成手順
ログベースの指標とは
ログベースの指標とは、 Cloud Logging に出力されたログにフィルタをかけて、その検出数を Cloud Monitoring の指標 (メトリクス) として利用する機能です。
今回は Cloud Logging に出力されたエラーログを、以下のようなフィルタで検知してみます。
resource.type="bigquery_dts_config" AND severity = "ERROR"
上記のフィルタは重要度が ERROR である Scheduled Query (BigQuery Data Transfer Service) ログを抽出するものです。
このフィルタを使ってログベースの指標を作成すると、 該当するログレコードの数を Cloud Monitoring に数値メトリクスとして送る ことができます。
そのメトリクスがしきい値を超えたときにアラートを発報するよう設定すれば、エラーログ出力を契機にメール通知や Slack 通知などを行うことができます。
ここからは、ログベースの指標と、それを元に通知を発報するアラートを Google Cloud コンソールで作成する手順をご紹介します。
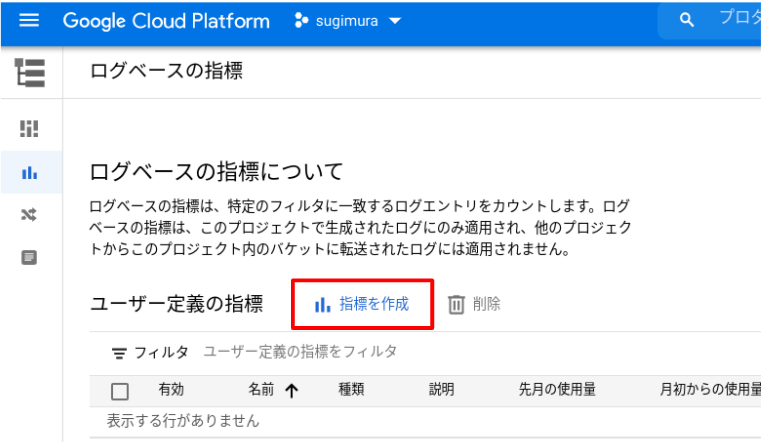
手順 1: ログベースの指標作成
Google Cloud コンソールで ロギング > ログベースの指標 画面へ遷移します。
ボタン 指標を作成 を押下します。
指標の設定値は以下のようにします。
- 指標タイプ: Counter
- ログ指標の名前: (任意)
- 説明: (任意)
- 単位: 空白
- フィルタの作成: 以下の通り
resource.type="bigquery_dts_config" AND severity = "ERROR"

入力後、ボタン 指標の作成 を押下すると指標が作成されます。
以後は Cloud Monitoring の Metrics Explorer で、検出数をメトリクス (指標) として確認できます。
メトリクス名は logging/user/(指定した指標名) となります。
手順 2: アラートの作成
指標作成後に現れる以下の画面から「指標に基づくアラートを作成する」を押下します。

この画面を閉じてしまっている場合は、 Google Cloud コンソールで Monitoring > アラート 画面へ遷移してボタン + CREATE POLICY を押下します。
次の画面で ADD CONDITION を押下し、 Target として logging/user/(指定した指標名) を指定します。
(指標作成後の画面から遷移した場合は、ここまでは自動で入力されます)

Period として、メトリクスを集計する時間単位を指定します。
Configuration のブロックで、発報の条件を指定します。

例えば Period が 10 minutes で Aggregator が Sum 、 Configuration にて is above 10 for most recent value のように設定した場合、 10 分間で検知されたログ数の合計が 10 を超えた場合に発報がトリガーされます。
is above 0 としておけば、 1 個でもエラーが出れば発報されるようになります。
ボタン ADD を押下してしきい値設定画面を閉じたら 次へ を押下して、通知先設定へ遷移します。

通知先は Cloud Monitoring の Notification Channel という設定値として管理することができます。
メールや Slack の他、 Webhook で外部 API を呼び出したり、 Pub/Sub へメッセージを Publish することもできます。
Notification Channel を事前に作っていない場合、この画面で新規作成が可能です。
なおアラートが発生すると Cloud Monitoring 内で「インシデント」が起票されますが、インシデントの自動クローズ期限などもここで設定できます。
ボタン NEXT を押下して、最後にアラート名を設定し、ボタン SAVE を押下します。

ここまで設定すると、しきい値を超えた際に Notification Channel へ通知が行われます。
メール通知の例と課題
通知先をメールとした場合、以下のようなメールが届きます。

課題として、メール本文からは 「どのジョブがコケたか」「どのようにコケたか」は分からない 点があります。
その代わりメール内の VIEW LOGS ボタンを押下して Google Cloud コンソールへログインして該当するログを閲覧すれば、エラー本文や該当する Scheduled Query ジョブの ID が確認できます。
しかしこれでは、 Google Cloud コンソールへログインする権限を持たないメンバーがメールを受け取る場合、対処が取れません。
メール本文からどのジョブがこけたかを把握するには、例えばフィルタを以下のようにして、ジョブごとにログベース指標とアラートを作成する方法が挙げられます。
resource.type="bigquery_dts_config" AND severity = "ERROR" AND resource.labels.config_id="xxxxxxxx-0000-0xxx-0000-xxxxxxxxxxxx"
resource.labels.config_id として指定している xxxxxxxx-0000-0xxx-0000-xxxxxxxxxxxx の部分は、各 Scheduled Query の詳細画面の 構成 タブで確認できる「リソース名」の末尾部分の英数字です。

こうしてジョブごとにログベース指標とアラートを作成すれば、メール本文にはアラート名や指標名が記載されるため、メール本文から「どのジョブがコケたか」までは把握することができます。
ただし、依然として「どのようにコケたか」までは分からないうえ、ジョブ数 (Scheduled Query 数) が多くなると、ジョブごとに指標とアラートを作成しなければならず、現実的ではありません。
メールによる通知はあくまで簡易的な通知に留め 、実際の対処はコンソールにログインしてログを確認する、というオペレーションが現実的でしょう。
Scheduled Query の限界
Scheduled Query では、前述の通知の課題に加えて、前後関係や分岐のあるジョブネットを組むことに限界があります。
ジョブ失敗時のリトライ処理なども、うまく管理することが難しいでしょう。
一定以上複雑なジョブの場合は Scheduled Query だけでジョブを構成することを諦めて、 ワークフロー管理ツールを導入することを検討 しましょう。
3rd party 製品の検討はもちろん、 Google Cloud サービスであれば Cloud Composer などが該当します。
また Cloud Data Fusion や Dataprep といったツールも検討対象です。
Cloud Monitoring と Cloud Logging
当記事でご紹介した Cloud Logging の使い方や、 Cloud Monitoring の指標やアラートの概念については以下の記事で紹介していますので、ご参考にお願いいたします。
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it