


G-genの杉村です。Cloud Logging は Google Cloud(旧称 GCP)上のシステム等が生成したログを収集・保管・管理する仕組みです。基本的な概念や仕組みを解説していきます。
- Cloud Logging 概要
- Cloud Logging が扱うログ
- 料金
- ログの閲覧
- ログの閲覧可能範囲を定義する
- ログルーティングとログの保存
- ログ監視
- Log Analytics
- サービス間連携
- Tips

Cloud Logging 概要
Cloud Logging とは
Cloud Logging(旧称 Stackdriver Logging)は Google Cloud 上のシステム等が生成したログを収集・保管・管理する仕組みです。
各 Google Cloud サービスが出力するログは自動的に Cloud Logging に集約されます。また、Cloud Logging の Web API やエージェントソフトウェアを通じて、任意のログを収集することもできます。
収集されたログはログバケットと呼ばれるストレージで保管され、期限が過ぎたら廃棄する等の設定を簡単に行うことができます。ログバケットの他にも、Cloud Logging や BigQuery など他のストレージにログを転送することも容易です。
ログは Web コンソールであるログエクスプローラで閲覧・クエリすることができます。さらに、指定の文字列がログに出力された際にアラートを発報する設定も可能です。
対象のログ
Cloud Logging で収集・管理可能なログには、以下の種類があります。
| 種別名 | 説明 |
|---|---|
| プラットフォームログ | BigQuery や Cloud Run 等、ほとんどの Google Cloud サービスのログ |
| コンポーネントログ | Google が提供するソフトウェア コンポーネントが生成するログ。Google Kubernetes Engine(GKE)の管理機構が出力するログなど |
| 監査ログ | Cloud Audit Logs やアクセスの透明性ログ(Google サポート等がユーザのコンテンツにアクセスした際に出るログ) |
| ユーザー作成のログ | ユーザーのアプリケーションなどによって出力したログ。エージェントや API 経由で収集 |
| マルチクラウドとハイブリッド クラウドのログ | Microsoft Azure や Amazon Web Services(AWS)から取り込んだログやオンプレミスから取り込んだログ |
ログの保存先
Cloud Logging の保存先ストレージは以下から選択できます。
- ログバケット
- Cloud Storage バケット
- BigQuery データセット
- Pub/Sub トピック
- Splunk
- 他の Google Cloud プロジェクト
ログバケット は Cloud Logging 独自の専用ストレージです。Cloud Storage バケットと名称が似ていますが、全く別のものです。ログバケットに保管されているログだけが、 Cloud Logging コンソールのログエクスプローラから閲覧できます。
ログバケットへのログ保管料金は、以下の公式ドキュメント「Google Cloud Observability の料金」の「Cloud Logging の料金概要」部分に記載されている「ロギング保持」がそれにあたり、$0.01/GiB(2025年2月現在)であり、Cloud Storage バケットの Standard Storage や Nearline Storage よりも少し安い価格設定です。
Cloud Logging が扱うログ
プラットフォーム ログ、コンポーネント ログ
ユーザーが意識しなくとも、様々な Google Cloud サービスが Cloud Logging にログを出力しています。
これにより、利用者は Web コンソール画面でいちいち各 Google Cloud サービスの画面へ遷移しなくても、Cloud Logging で集中的にログを管理・閲覧することができます。
Cloud Run や Cloud Run functions 等の Google Cloud サービスで稼働するプログラムは、何も設定しなくても、標準出力が Cloud Logging にログエントリとして連携されます。ただし、適切なフォーマットで出力することで Severity(重要度)などの属性値を、閲覧しやすい形で出力できます。以下の記事も参考にしてください。
監査ログ
Cloud Audit Logs サービスによって生成されるログです。
Cloud Audit Logs については以下の投稿で解説していますので、そちらを参照してください。
ユーザー作成のログ
ユーザーが明示的に Cloud Logging に投入したログです。
Google Compute Engine(GCE)の VM 等から Ops エージェント などを通して投入することができます。
Cloud Logging にログを投入することで以下のようなメリットを享受できます。
- ログ閲覧の際にサーバにログインする必要がない
- サーバ障害やスケールインした際にもログが失われない
- 分析目的でログを BigQuery に投入できる
- ログの保管と保管期限の管理(ハウスキーピング)が容易に実装できる
VM に Ops エージェントをインストールするとデフォルトで、Linux では /var/log/messages や /var/log/syslog が、 Windows では System、Application、Security のイベントログが収集されます。
デフォルトで収集されるログ以外にも、設定ファイルを変更することで、任意のアプリケーションのログを収集することができます。 詳細は公式 ドキュメント を参照ください。
Compute Engine の VM から Cloud Logging にログを送出する方法については、以下の記事もご参照ください。
マルチクラウドとハイブリッド クラウドのログ
Microsoft Azure や Amazon Web Services(AWS)から取り込んだログやオンプレミスから取り込んだログです。
Ops エージェント等を通じて、Google Cloud 以外のプラットフォームからもログを収集し、管理することができます。
料金
Cloud Logging の料金
Cloud Logging の料金はログの取り込み処理量とストレージ保管量の2軸での従量課金です。
「取り込み処理量」への課金は、Cloud Logging ログバケットに取り込むログのサイズに応じて、ワンショットの料金が発生します。
「ストレージ保管量」への課金は、ログバケットで保管しているログのサイズに応じて、継続的に発生する料金です。
2025年2月現在の料金単価は、以下のとおりです。
| 料金名 | 単価 | 説明 |
|---|---|---|
| 取り込み処理量 | $0.50 / GiB | ・Cloud Logging ログバケットに投入されたログのデータサイズに応じて一度だけ課金 ・毎月、プロジェクトごとに最初の 50 GiB は無料 |
| ストレージ保管量 | $0.01 / GiB | ・ログバケット上に30日間以上保管されたログにのみ適用(30日間以内は無料) ・ログを BigQuery や Cloud Storage 等、他サービスに転送する場合はそちらの料金が発生 |
最新の料金単価は以下のページを参照してください。なお以下のドキュメントでは、前者の「取り込み処理量」は「Logging ストレージ」、後者の「ストレージ保管量」は「ロギング保持」と表現されています。
最初から存在するログバケットの料金
Google Cloud プロジェクトを作成すると、デフォルトで _Required と _Default という2つのログバケットが存在しています。
_Required は、Google Cloud が必須で取得する監査系のログが投入される特殊なログバケットです。ここに保存されるログは、取り込み料金もストレージ料金も発生しません。
_Default は、_Required に保存されるログ以外のログがすべて保存されるログバケットです。このログバケットは、初期設定で保持期限が30日ですので、保持期限を変更しなければストレージ料金は発生しません。ただし、取り込み処理料金は発生することに注意してください。
取り込み料金には、プロジェクトごとに最初の50GiBまでが無料枠として用意されていますので、相当のサイズまでは無料で取り込むことができます。
取り込み料金の節約
ログのボリュームが大きくなると、$0.50 / GiB の取り込み料金はコストとして重くのしかかってきます。
この取り込み料金は Cloud Logging ログバケットに対して取り込むログサイズに対してのみ発生します。つまり、以下のログに対しては料金が発生しません。
- シンク(後述)により Cloud Storage バケット、BigQuery データセット、Pub/Sub トピック等にルーティングされたログ
- シンクの除外フィルタで除外したログ
ログ量が莫大になり、取り込み料金が多く発生している場合、除外フィルタで取り込むログをフィルタリングしたり、Cloud Storage や BigQuery に逃がすことで、取り込み料金を節約できます。ただし、ルーティング先の取り込み料金は発生しますので、そちらを確認する必要はあります。
例として Cloud Logging ログバケットへの取り込みと BigQuery へのエクスポートで料金を比較すると、以下の通りです。
- Cloud Logging (取り込み料金) : $0.5 /GB (2023年5月時点)
- BigQuery (Streaming inserts 料金) : $0.06 /GB ($0.012 per 200 MBと表記。東京リージョン、2023年5月時点)
BigQuery へログをエクスポートすると Streaming inserts 料金が発生しますが、Cloud Logging ログバケットへの取り込み料金と比較して、10分の1近くの料金設定となっています。
ログの閲覧
閲覧方法
Cloud Logging のログバケットに保存されたログは、Google Cloud の Web コンソール内に存在するログエクスプローラと呼ばれる画面で閲覧することができます。
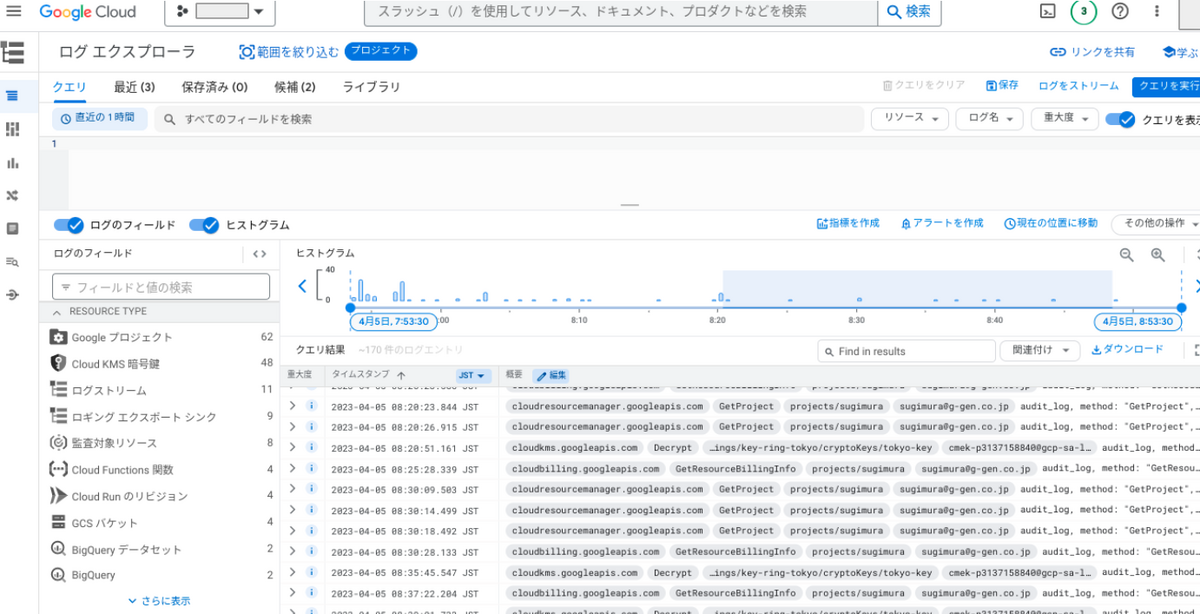
また他にも、gcloud コマンドラインツール等を用いてログを取得することも可能です。
クエリ言語
ログエクスプローラや gcloud コマンドでは、独自のクエリ言語である Logging query language を用いて、ログをフィルタして表示させることができます。
Logging query language は、ログエクスプローラから直感的に生成することもできますので、ゼロから時間をかけて学習する必要性はありません。公式のリファレンスは以下のリンクから参照できます。
- 参考 : Logging のクエリ言語
以下は、クエリの例です。my-project というプロジェクトにおける Cloud KMS 関連のログだけを抽出しています。
protoPayload.serviceName="cloudkms.googleapis.com" resource.labels.project_id="my-project"
以下の当社記事では、Logging query language について詳細に解説しています。
インデックス
Cloud Logging にはインデックスの概念があります。
以下のフィールドにはデフォルトでインデックスが作成されており、クエリに含めることで、ログ抽出を高速化できます。
- resource.type
- resource.labels.*
- logName
- severity
- timestamp
- insertId
- operation.id
- trace
- httpRequest.status
- labels.*
- split.uid
またログバケットごとに、フィールドに対してカスタムインデックスを明示的に指定することができます。
ログの閲覧可能範囲を定義する
ログビュー
ログビューとは、ログバケットに保存されているログの一部のみ(ログのサブセット、と表現します)を利用者に閲覧させたい場合に、事前に定義したログ範囲のみの閲覧権限を付与できる機能です。
ログビューでは、対象のログバケットと、Logging query language で記述するフィルタを定義します。管理者はログ閲覧者のために、このログビューに対する閲覧権限を付与します。これにより、閲覧者は定義されたログバケット内のフィルタされたログだけを閲覧できるようになります。
詳細と具体的な手順は以下のドキュメントを参照してください。
- 参考 : ログバケットのログビューを構成する
ログスコープ
ログスコープとは、複数の Google Cloud プロジェクトの Cloud Logging ログを、横断して閲覧するための機能です。
通常、ログエクスプローラでは、単一のプロジェクトのログバケットを対象としたログのクエリ・閲覧しかできません。
ログスコープを使うと、複数のプロジェクトやログビューをグルーピングすることができます。ログエクスプローラ上でログスコープを対象にしてクエリを投入すると、複数のプロジェクトやログビューを横断してログが検索されます。
ログスコープ自体は、プロジェクトレベルのリソースとしてプロジェクト内に作成します。
当機能を使って各プロジェクトのログを閲覧するには、閲覧者が対象のプロジェクトにログの閲覧権限を持っている必要があります。
ログスコープ機能は2025年2月現在、Preview 段階です。
ログルーティングとログの保存
ログルーティングとは
Cloud Logging で特に重要な概念がログルーティングおよびシンク(sink)です。おおまかな概念を以下に図示します。
- 参考 : 転送とストレージの概要
- 参考 : サポートされている宛先にログをルーティングする
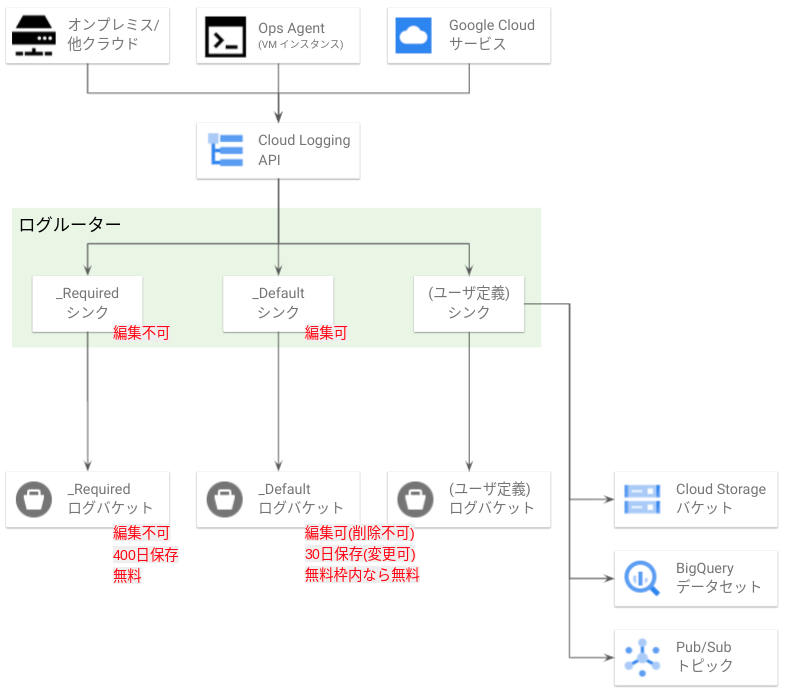
図の最上部は、ログの発生元を表しています。ここからログが Cloud Logging API に向けて投入されます。
投入されたログはログルーターという Cloud Logging の内部機構により、振り分け先を決定されます。ログルーターはシンクという個別設定を持っており、ログはシンクに定義された設定に応じて保存先に振り分けられます。
ログの振り分け先としてログバケット 、Cloud Storage バケット、BigQuery データセット、Pub/Sub トピック、他の Google Cloud プロジェクト、Splunk を指定することができます。
シンクとは
シンクは Cloud Logging に入ってきたログの振り分けをするコンポーネントです。
API を通じて Cloud Logging に入ってきたログは、シンクによって宛先であるログバケットや BigQuery などに振り分けられます。
シンクは設定値として 1. ログの保存先、2. 包含フィルタ、3. 除外フィルタ を持ちます。
まず 1. ログの保存先 は前述の通り「ログバケット」、「Cloud Storage バケット」、「BigQuery データセット」、「Pub/Sub トピック」等からいずれかを指定します。
そして 2. 包含フィルタ と 3. 除外フィルタ は、そのシンクがどのログを ログの保存先 に振り分けるかを決定するためのフィルタであり、 Logging query language で定義します。以下のようなものです。
resource.type="bigquery_dataset" AND
LOG_ID("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="google.cloud.bigquery.v2.DatasetService.UpdateDataset"
上記は「BigQuery データセットが UpdateDataset により更新されたときに発生したアクティビティログをキャッチせよ」という意味です。
- 参考 : フィルタの例
なお、複数のシンクでフィルタの設定が重複していて、同じログをキャッチするようになっている場合、それら全てのシンクにログが複製されて振り分けられます。
たとえばシンク A はあるログをあるログバケットに転送する設定になっており、シンク B は同じログを BigQuery に投入する設定になっているとします。この場合は、ログバケットと BigQuery の両方に、同じログが投入されます。
初期設定で存在するシンクとログバケット
初期設定で _Required と _Default というシンクが存在しています。それぞれのシンクは _Required と _Default というログバケットにログをルーティングする設定になっています。
_Required ログバケットには「管理アクティビティ監査ログ」「システム イベント監査ログ」「アクセスの透明性ログ」が保存され、400日間保存されます。なお「管理アクティビティ監査ログ」「システム イベント監査ログ」は Cloud Audit Logs という監査ログの仕組みによって取得されるログです。
_Default ログバケットには、_Required に入らない全てのログが入るように初期設定されています。この設定は変更可能です。
これらのバケットに発生する料金は前述の最初から存在するログバケットの料金をご参照ください。
- 参考 : ログバケット
書き込み ID
シンクを作成した際、ログの振り分け先が「そのシンクが所属するプロジェクトのログバケット以外」である場合、書き込み ID(Writer Identity)と呼ばれるサービスアカウントが生成されます。
ログをルーティングするには、この書き込み ID に対して、書き込み先への権限を付与する必要があります。
書き込み ID の名称はコンソールでログシンクを選択し「シンクの詳細を表示する」を押下したり、gcloud で gcloud logging sinks describe ${SINK_NAME} を実行することで確認できます。
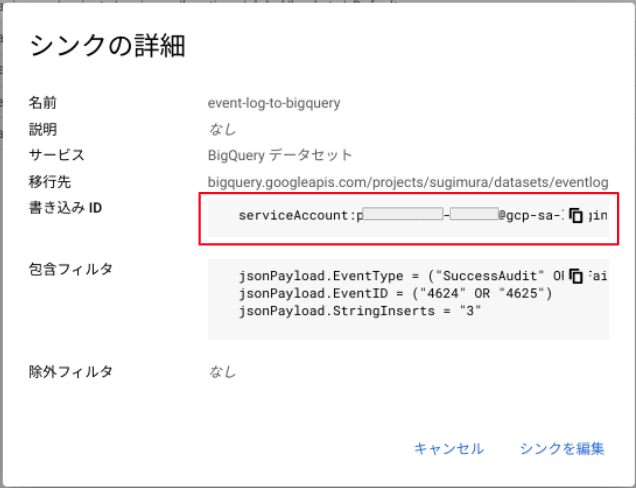
例えば書き込み先が BigQuery データセットの場合、当該のプロジェクトや BigQuery データセットにおいて、書き込み ID に BigQuery データ編集者 権限を付与する必要があります。
- 参考 : エクスポート先の権限を設定する
なおシンクと同じプロジェクト内のログバケットへログを送る際は、書き込み ID は不要であり、作成されません。
書き込み ID はシンクを作成するごとに一意に生成されます。後述する集約シンクを作成する際には組織レベルやフォルダレベルでシンクを作成しますが、シンクが作成されるレベルによって書き込み ID の命名規則が異なります。
| No | シンクのレベル | 書き込み ID の名称 |
|---|---|---|
| 1 | プロジェクトに作成されたシンクの書き込み ID | p(プロジェクト番号)-(6桁数字)@gcp-sa-logging.iam.gserviceaccount.com |
| 2 | フォルダレベルで作成されたシンクの書き込み ID | f(フォルダ番号)-(6桁数字)@gcp-sa-logging.iam.gserviceaccount.com |
| 3 | 組織レベルで作成されたシンクの書き込み ID | o(組織番号)-(6桁数字)@gcp-sa-logging.iam.gserviceaccount.com |
プロジェクトをまたいだログの集約
別プロジェクトのストレージにログを送る
Cloud Logging のシンクを使い、別のプロジェクトのログバケットや BigQuery データセットにログをルーティングすることができます。
この場合、シンクの書き込み ID が宛先のストレージに対して書き込み権限を持っている必要があります。
またシンクの宛先を「他の Google Cloud プロジェクト」にした場合、宛先プロジェクト内のログシンクに処理を委任することができます。次の項で説明するような組織構成を使わない場合でも、この方法でログの処理を1プロジェクトに集約することが可能です。
組織全体でログを集約する
以下のような理由で、組織全体でログを一つのプロジェクトのログバケットや BigQuery に集約したい要件が出てくるかもしれません。
- 複数プロジェクトのログを集約して SIEM 等で分析したい
- 監査などの理由で監査ログを第三者に提出する必要がある
- 複数プロジェクトでアプリケーションが稼働しておりログを横断して確認したい
その際は、シンクを組織やフォルダのレベルで作成し、配下の全てのプロジェクトのログを収集することが可能です。このように複数プロジェクトのログを集約するためのシンクを集約シンク(Aggregated sinks)といいます。
シンクを作成する際に「このリソースとすべての子リソースによって取り込まれたログを含める」オプションを有効化することで、その組織/フォルダ配下の全てのプロジェクトに対してシンクが有効になり、ログ集約用のプロジェクトにログを収集できます。
詳細な手順は、以下を参考にしてください。
- 参考 : 組織のログをログバケットに保存する
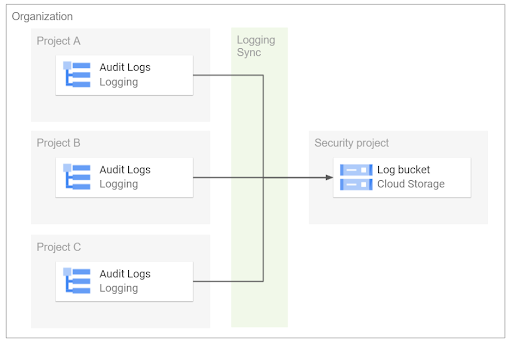
なお、単純に複数のプロジェクトを横断してログを確認したい場合、前述のログスコープ機能を使うこともできます。
集約シンクの種類
集約シンクの作成時、非インターセプト型集約シンク(non-intercepting aggregated sink)とインターセプト型集約シンク(intercepting aggregated sink)の2種類から選択可能です。
前述の通り、組織の上流(組織のルートやフォルダ)で集約シンクを使用すれば、下流の子リソース(プロジェクト等)で発生するログを集約することが可能ですが、非インターセプト型集約シンクの場合は、親リソースの非傍受型集約シンクで収集したログは、子リソースでも収集することができます。一方のインターセプト型集約シンクの場合、上流のシンクで収集したログはそれより下流の子リソースでは収集できません。
インターセプト型シンクを使えば、子リソースでログを重複して収集し、ログ収集コストが肥大化することを避けることができます。逆に、子リソースでもログを自由に収集できるようにしたい場合は、非インターセプト型のシンクを利用します。
なおインターセプト型シンクは子リソース(プロジェクト)からも閲覧できます(コンソールのログルーター画面に表示されます)。
- 参考 : Overview
ログ監視
ログベースの指標
Cloud Logging でログの特定文字列を正規表現で検知し、その検知数を Cloud Monitoring に指標(メトリクス)として送信することができます。これをログベースの指標と呼びます。
この指標を Cloud Monitoring のアラートポリシー機能により検知・発報することで「XXログで Error という文字列を5分間で3個以上検知したらメール通知する」のようなログ監視が可能になります。
手順は以下をご参照ください。
- 参考 : ログベースの指標の概要
- 参考 : 指標ベースのアラート ポリシーを作成する
アラートポリシーについては、以下の記事もご参照ください。
ログベースのアラート
ログベースのアラートは、Cloud Logging に出力されたログエントリの文字列を検知して、E メールや Slack 等に対して通知を発報する機能です。
検知対象の文字列を指定してログベースのアラートを設定することで、アプリケーションや Google Cloud サービスのエラー等を検知して、運用者や管理者に対してアラートを発報することができます。
前述のログベースの指標による発報方法は、いったんログ文字列の検知数を Cloud Monitoring の指標としてカウントしますが、この「ログベースのアラート」では特定の文字列を検知すると直接、アラートを発報できます。
この「ログベースのアラート」は前述の「ログベースの指標 + アラートポリシー」とほとんど同じことが可能ではありますが、「ログベースのアラート」では文字列検知数を指標化しないため、数値として後から統計が取れない代わりに、より少ないステップで設定可能であり、後から見ても設定がわかりやすいという違いがあります。
- 参考 : ログベースのアラートを構成する
Log Analytics
Log Analytics とは
Log Analytics(ログ分析)は、Cloud Logging ログバケットに格納されているログに対して SQL でクエリすることができる機能です。
当機能リリース以前は、ログに対して SQL でクエリをかけるにはログルーター (シンク) を使って BigQuery へログをエクスポートする必要がありました。2023年1月に当機能が GA されて以降は、当機能により Cloud Logging ログバケットに直接 SQL を実行することが可能になりました。
またもう一つの機能としてログバケットを BigQuery データセットとリンクすることができます。 BigQuery データセットとリンクされたログバケットは BigQuery 側からビューとして使うことができます。これにより BigQuery の他のデータと結合しての分析も可能になります。
- 参考 : ログ分析
利用方法
ログに SQL を実行するには、ログバケットごとに Log Analytics を有効化する必要があります。
有効化されたログバケットに対して Google Cloud コンソールの Log Analytics ページから BigQuery 標準 SQL を実行することができます。
BigQuery データセットとのリンク
ログバケットごとに BigQuery データセットとのリンクを行うことができます。
リンクすると BigQuery に新規データセットが作成され、その中に _AllLogs というビューが生成されます。このビューに対してクエリを実行することでログを抽出できます。
BigQuery を使って _AllLogs ビューに対してクエリを実行すると、スキャンしたデータ量に応じて BigQuery のクエリ料金が発生します。一方で Log Analytics 画面からのクエリは無料です。
ユースケース
Log Analytic は、アプリケーションのトラブルシューティングや、アプリログを BigQuery の自社データやパブリックデータセット等と結合する等の用途が想定されます。
従来、こういった分析をするためにログルーター(シンク)を使って BigQuery にログをエクスポートして長期保存することもありました。しかし Log Analytics 登場後は、事情が変わります。
Cloud Logging のログバケットの保存料金は、 BigQuery のストレージ料金(アクティブ/長期保存)と同等あるいは安価なためです。最終的に Cloud Logging ログバケットに保存したほうが安価になるのか、あるいは BigQuery の方が安価になるのか、については後述します。
制限
代表的な制限のみを記載します。
- クエリできるのは Log Analytics 有効化後に発生したログのみ
- ログバケットが CMEK 暗号化されていない
- ログバケットがロックされていない
その他の制限や最新情報は以下の公式ドキュメントをご参照ください。
- 参考 : 制限事項
Log Analytics の料金
Log Analytics では通常の Cloud Logging 以外に発生する追加料金はありません。Log Analytics 画面からクエリした場合、クエリ料金も無料です。
一方でログバケットを BigQuery データセットとリンクして BigQuery からクエリした場合 BigQuery のクエリ料金が発生します。
ログをログバケットに保存するのと、BigQuery にエクスポートするのでは、最終的にどちらが安価になるのでしょうか。それには、以下の要素が関わってきます。
- ログ取り込み時の料金
- Cloud Logging (取り込み料金) : $0.5 /GB (2023年5月時点)
- BigQuery (Streaming inserts 料金) : $0.06 /GB ($0.012 per 200 MBと表記。東京リージョン、2023年5月時点)
- クエリ時の料金
- Cloud Logging (Log Analytics 画面) でのクエリ : 無料
- BigQuery でのクエリ (オンデマンド料金) : $6 /TB (最初の 1TB は無料) (東京リージョン、2023年5月時点)
つまり、ログ取り込みの料金は BigQuery の方が安価ですが、クエリ時の料金は Cloud Logging(Log Analytics 画面)のほうが安価(無料)ということで、一長一短です。利用実績を確認し、どちらのほうが安価になるかを判断してから決定することになります。
サービス間連携
Cloud Run functions のログ
以下は、Cloud Run functions から Cloud Logging へログを投入する方法について解説した記事です。Cloud Run functions では、標準出力に文字列を出力するだけで Cloud Logging へログとして投入されますが、特定の設定をすることで 重要度(Severity)等を設定することができます。
Compute Engine VM(Windows)のログ
以下の記事では、Compute Engine VM から Cloud Logging へ任意のログファイルを取り込むための方法を紹介しています。Ops Agent という Cloud Monitoring のエージェントソフトウェアをインストールすることで実現できます。
Tips
以下の記事では、Cloud Logging の運用上の Tips が紹介されています。
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it