


G-gen 又吉です。当記事では、Google Cloud Next '23 で発表された BigQuery DataFrames を解説します。BigQuery 上のデータを、pandas ライクな、また scikit-learn ライクなインターフェイスで操作できるライブラリです。

概要
BigQuery DataFrames とは、BigQuery API を介したデータの変換や機械学習を容易に行える Python のオープンソースパッケージです。
BigQuery DataFrames では、以下の 2 つの機能を提供します。
- bigframes.pandas
- bigframes.ml
通常、機械学習モデルを構築する際、以下のようなフローが発生します。

BigQuery DataFrames を用いると、BigQuery 上のデータを pandas のような操作感で処理ができ、scikit-learn のような操作感でモデルトレーニングと評価、予測が行えます。
また、データの処理と保管を BigQuery 上で管理できるため、クライアントのマシンスペックやメモリ容量を気にせず開発ができます。
尚、BigQuery DataFrames は 2023 年 10 月現在プレビュー機能となります。
参考 : BigQuery DataFrames Python API
参考 : BigQuery DataFrames クイックスタート
bigframes.pandas
概要
bigframes.pandas では、BigQuery 上のデータを pandas ライクに処理できます。一次元データを格納する Series クラスや、二次元データを格納する DataFrame クラスが用意されており、pandas でデータ処理を行うメソッドもほとんど用意されています。
仕組み
bigframes.pandas の実態は、BigQuery API が裏側で実行されており、各メソッドを実行すると BigQuery にジョブを発行して BigQuery のコンピューティングリソースで処理し、またデータも BigQuery に保持します。つまり、クライアントのマシンスペックやメモリ容量を気にせず開発ができます。
例えば、サイズが約 60GB ある Wikipedia のページビューが格納された BigQuery サンプルテーブルを bigframes.pandas で処理してみたいと思います。
# input[0] df_sample = bqd.read_gbq("bigquery-samples.wikipedia_pageviews.200809h") df_sample.head(3)

Open Job をクリックすると、実行された SQL を確認できます。

また、上記セルの実行前後で、クライアント側のメモリ使用量にはほとんど影響していないことから、60GB のデータはクライアント側に保存されていないことがわかります。
データをクライアントマシンにダウンロードしたいときは、to_pandas メソッドを用いることでデータのダウンロードも可能です。
bigframes.ml
概要
bigframes.ml では、BigQuery ML API を scikit-learn ライクに操作することができます。
例えば、ほとんどのモデルに共通して以下のメソッドが用意されています。
サポートされているモデルも、回帰や分類、クラスタリングや次元削減といった基本的な機械学習モデルはもちろん、 Vertex AI PaLM API を利用した LLM モデルもサポートされています。
さらに、トレーニング後のモデルを to_gbq メソッドで BigQuery に保存することもできます。
参考:Train models
自動前処理
概要
bigframes.ml では、BigQuery ML を用いてモデルトレーニングが行われるため、BigQuery ML の標準機能である特徴量の自動前処理を理解しておく必要があります。
自動前処理の主な機能は以下の通りです。
- 特徴の自動変換
- 欠損データの自動補完
また、Preprocessing モジュールを用いることで、ユーザーが手動でデータの前処理を行うことも可能です。
特徴の自動変換
入力された特徴量は次のように自動変換されます。
| No | 入力データの型 | 変換方法 | 説明 |
|---|---|---|---|
| 1 | INT64, NUMERIC, BIGNUMERIC, FLOAT64 | 標準化 | 各特徴量の最大と最小の幅が大きいと、特徴量をそのまま比較することが困難になるため、標準化を行うことで「平均値を 0 、標準偏差を 1」にして各特徴量のスケールを合わせる。 |
| 2 | BOOL, STRING, BYTES, DATE, DATETIME, TIME | one-hot encoding | 数値や配列、TIMESTAMP 以外のデータ型では、ダミー変数用いて数値化します。 |
その他の入力データ型は以下の公式ドキュメントをご参照下さい。
欠損データの補完
欠損データ (NULL) がある際、列の型によって以下のように値が補完されます。
| No | 列の型 | 補完方法 |
|---|---|---|
| 1 | Numeric | 数値列の NULL 値は、元の入力列の平均値に置換します |
| 2 | One-hot/Multi-hot encoded | 新規のカテゴリとして扱われます。つまり、NULL 値を持つデータは、新しいカテゴリとしてone-hot/Multi-hot encoding されます |
その他の列の型は以下の公式ドキュメントをご参照下さい。
制限事項
基本的には、BigQuery の割り当てと制限 に従いますが、他にも以下のような制限事項があります。
- BigQuery セッション で指定しているロケーションと read_gbq / read_gbq_table / read_gbq_query で読み込むデータセットのロケーションは同じである必要があります。
- bigframes.ml では、モデルトレーニングのサポートはロケーションによって異なります。詳細は BigQuery ML のロケーション をご覧ください。
使ってみる
やること
BigQuery DataFrames を用いて、機械学習モデルを構築します。
扱うデータは、BigQuery 公開データセットにある penguin テーブル を使用して、ペンギンの種類、居住島、くちばしの長さと深さ、足ひれの長さ、性別に基づいてペンギンの体重を予測する線形回帰モデルを作成します。
penguin テーブルのスキーマ情報は以下のとおりです。
| No | フィールド | 型 | モード | 説明 |
|---|---|---|---|---|
| 1 | species | STRING | REQUIRED | ペンギンの種類 |
| 2 | island | STRING | NULLABLE | 居住島 |
| 3 | culmen_length_mm | FLOAT | NULLABLE | くちばしの長さ |
| 4 | culmen_depth_mm | FLOAT | NULLABLE | くちばしの深さ |
| 5 | flipper_length_mm | FLOAT | NULLABLE | 足ひれの長さ |
| 6 | body_mass_g | FLOAT | NULLABLE | 体重 |
| 7 | sex | STRING | NULLABLE | 性別 |
環境構築
当記事では、Notebook 環境に Colab Enterprise を用います。
Colab Enterprise を使用すると、インフラストラクチャを管理せずに Notebook で作業できます。
Colab Enterprise の Notebook 作成方法は公式ドキュメントのクイックスタートをご参考下さい。
初期設定
パッケージのインストール
Notebook で使うパッケージをインストールします。
# input[1]
!pip install bigframes
BigQuery セッションの設定
プロジェクト ID をご自身の値に書き換えて実行します。
# input[2] import bigframes.pandas as bpd PROJECT_ID = ${プロジェクト ID} REGION = "US" bpd.options.bigquery.project = PROJECT_ID bpd.options.bigquery.location = REGION
データのロード
bigframes.pandas では、pandas と同様に csv や json を読み込むメソッドもありますが、BigQuery 上のデータを読み込む read_gbq メソッドが用意されています。
今回は read_gbq メソッドを利用します。
# input[3] df = bpd.read_gbq("bigquery-public-data.ml_datasets.penguins") df.head(3)

read_gbq の引数にテーブル ID を入力してデータを取得しましたが、BigQuery に対して SQL を実行して出力結果をデータフレームで取得することも可能です。
# input[4] query_df = bpd.read_gbq(""" SELECT species, AVG(body_mass_g) as avg_body_mass_g FROM `bigquery-public-data.ml_datasets.penguins` GROUP BY species """) query_df

参考:bigframes.pandas - API リファレンス
前処理
特徴の変換
各カラムのデータ型を確認します。
# input[5]
df.dtypes

string と Float64 の 2 種類のデータ型が存在します。
BigQuery ML の自動前処理 (特徴の変換) により、string 型の場合は one-hot encoding され、Float64 型の場合は標準化されるため、ここでは何も手を加えないことにします。
欠損値の対応
各カラムの欠損値の個数を確認します。
# input[6]
df.isnull().sum()

BigQuery ML の自動前処理 (欠損データの補完) では、string 型の場合は NULL が新規のカテゴリとなり、Float64 型の場合は元の入力列の平均値となります。
ここで、全体の行数も確認します。
# input[7]
df.shape

全データ数は 344 であり、sex の欠損値は 10 であり全体の 3% となります。
sex 列で、「FEMALE」と「MALE」以外の新規カテゴリが追加されるとノイズになる可能性があり、また欠損値は全体の 3% 弱のため、sex 列で NULL となる行を削除したいと思います。
# input[8] df2 = df[df["sex"].notna()]
# input[9]
df2.isnull().sum()

sex の欠損値が含まれる行を削除した結果、他の列にあった欠損値も無くなっていることから、欠損値は削除した行の中にすべて含まれていたことになります。
# input[10]
df2.shape

データ分割
特徴列 (入力) と正解データ列 (出力) に分割します。
# input[11] x = df2[["species", "island", "culmen_length_mm", "culmen_depth_mm", "flipper_length_mm", "sex"]] y = df2[["body_mass_g"]]
トレーニングデータとテストデータにデータを分割します。
scikit-learn でもよく使われる train_test_split が bigframes.ml にも用意されているためこちらを使います。
# input[12] from bigframes.ml.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=0)
# input[13] print(f"x_train : {x_train.shape}" ) print(f"x_test : {x_test.shape}" ) print(f"y_train : {y_train.shape}" ) print(f"y_test : {y_test.shape}" )

モデルトレーニング
bigframes.ml を用いて線形回帰モデルを構築します。
# input[14] from bigframes.ml.linear_model import LinearRegression # モデルの初期化 model = LinearRegression( enable_global_explain = True ) # モデルトレーニング model.fit(x_train, y_train)
モデルの初期化では、各特徴がモデルに対してどれだけ影響しているかを示す Explainable AI を有効にするため、enable_global_explain を有効にしています。
その他の調整可能なパラメータは公式ドキュメントをご参照下さい。
推論
モデルに対して、predict メソッドを用いることで推論 (予測) が可能です。
# input[15] pred = model.predict(x_test) pred.head(2)

モデル評価
モデルに対して、score メソッドを用いることで評価指標を取得できます。
# input[16]
model.score(x_test, y_test)
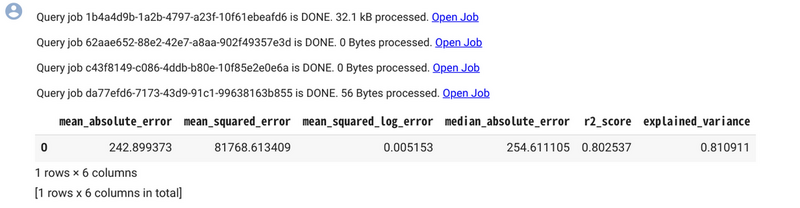
mean_absolute_error (MAE : 平均絶対誤差) が 242.9 であり、また、0~1 の間の値をとり値が大きくなるほど予測値と実測値の誤差が少ないことを意味する決定係数も 0.80 であった。
モデルの保存
作成したモデルを BigQuery に保存できます。
データセット ID をご自身の値に書き換えて実行下さい。
# input[17] # データセットの作成 DATASET_ID = ${データセット ID} from google.cloud import bigquery client = bigquery.Client(project=PROJECT_ID) dataset = bigquery.Dataset(PROJECT_ID + "." + DATASET_ID) dataset.location = REGION dataset = client.create_dataset(dataset, exists_ok=True) # モデルの保存 model.to_gbq(DATASET_ID + ".penguin_weight" , replace=True)
参考:Class LinearRegression - to_gbq
BigQuery にモデルが保存されているのを確認しました。

また、Explainable AI によって各特徴量がどれくらいモデルに寄与しているのかを調べることができます。

BigQuery DataFrames を用いることで、pandas のようにデータの前処理を行い、scikit-learn のようにモデルの構築と評価、予測を行うことができました。
クリーンアップ
先程作成したデータセットを削除します。
input[18] from google.cloud import bigquery client = bigquery.Client(project=PROJECT_ID) client.delete_dataset( DATASET_ID, delete_contents=True, not_found_ok=True )
又吉 佑樹(記事一覧)
クラウドソリューション部
はいさい、沖縄出身のクラウドエンジニア!
セールスからエンジニアへ転身。Google Cloud 全 11 資格保有。Google Cloud Champion Innovator (AI/ML)。Google Cloud Partner Top Engineer 2024。Google Cloud 公式ユーザー会 Jagu'e'r でエバンジェリスト。好きな分野は生成 AI。
Follow @matayuuuu