


G-genの杉村です。Google Cloud(旧称 GCP)のフルマネージドなデータウェアハウスサービスである BigQuery の料金体系である BigQuery Editions について解説します。

概要
BigQuery の課金体系
前提知識として、BigQuery の利用料金は以下の2つの合計であることを理解する必要があります。
- ストレージ料金(格納したデータサイズに応じた課金)
- コンピュート料金(コンピュート処理リソースに対する課金)
このうち、2. のコンピュート料金は、Google Cloud プロジェクトごとに「オンデマンド課金」と「BigQuery Editions」のいずれかから選ぶことができます。デフォルトでは、BigQuery はオンデマンド課金モードに設定されています。
オンデマンド課金は、スキャンしたデータのサイズに応じた課金が発生する料金体系です。課金額が予測しやすい反面、スキャン対象のデータサイズに比例してリニアに(直線的に)料金が高額になります。
当記事では、もう一方の BigQuery Editions を解説します。
- 参考 : ワークロード管理の概要
BigQuery のストレージ料金については、以下の記事も参照してください。
BigQuery Editions とは
BigQuery Editions とは、BigQuery の課金モデルの1つです。デフォルトのオンデマンドモードでは、データのスキャン量に応じてコンピュート料金がかかります。一方で、BigQuery Editions を選択すると、スロットと呼ばれる BigQuery のコンピュートリソース(仮想的な CPU の単位)を確保した量と時間に応じて課金されます。
なお、BigQuery Editions を使ったコンピュート課金方式のことを、オンデマンド課金の対義語として、容量ベースの課金(Capacity-based billing)と呼ぶこともあります。
- 参考 : スロットについて
スロットは、BigQuery Autoscaler によって動的に確保されます。BigQuery Editions はオンデマンド課金と比較すると課金額が予測しづらいものの、利用ボリュームが大きいときや、利用者が多かったり、利用頻度が多いときなどにコストメリットが得られます。
BigQuery Editions には、単価の異なる3つの価格ティアがあります。Standard、Enterprise、Enterprise Plus の3つであり、それぞれ料金単価と、利用可能な機能に違いがあります。
また BigQuery Editions では、後述の BigQuery Autoscaler 機能が有効になります。適切に設定すれば、従量課金のメリットを受けることができ、料金の最適化に繋がります。
- 参考 : BigQuery pricing
- 参考 : BigQuery エディションの概要
過去の経緯
2023年7月以前は、BigQuery の料金プランは「オンデマンド課金」と、事前に購入したスロットを定額利用する「Flat-rate 課金(定額課金)」の2種類でした。
2023年3月29日の Google Data Cloud & AI Summit において、BigQuery の新しい料金体系である BigQuery Editions が発表され、Flat-rate 課金は廃止されることになりました。また、新しいストレージ課金モデルである Physical storage 課金もこのときに公開されました。
変更は以下のようなタイムラインで行われました。
| 日付 | 内容 |
|---|---|
| 2023-03-29 | ・BigQuery Editions の販売開始 |
| 2023-07-05 | ・Flat-rate の新規販売の終了 ・Flex slots は Editions に移行 ・Monthly/Annual slots は期間終了すると Editions に移行 ・オンデマンド課金の単価が新料金に変更 |
3つのエディション
概要
BigQuery Editions には、単価の異なる3つの価格ティア(エディション)があります。Standard、Enterprise、Enterprise Plus の3つであり、それぞれ料金単価と、利用可能な機能に違いがあります。
エディションごとの機能差異や料金は以下のとおりです。なお記載の情報は一部抜粋であり、2025年4月現在のものです。最新情報は必ず公式の料金表やドキュメントをご参照ください。
| 比較項目 | Standard | Enterprise | Enterprise Plus |
|---|---|---|---|
| 単価 (US) | $0.04/slot/h | $0.06/slot/h | $0.10/slot/h |
| 単価 (Tokyo) | $0.051/slot/h | $0.0765/slot/h | $0.1275/slot/h |
| 1年/3年コミット | × | ○ | ○ |
| SLA | 99.9% | 99.99% | 99.99% |
| スロット数 | 最大1,600slots | 制限なし | 制限なし |
| CMEK | × | × | ○ |
| VPC Service Controls | × | ○ | ○ |
| 動的データマスキング | × | ○ | ○ |
| 列レベルセキュリティ | × | ○ | ○ |
| 行レベルセキュリティ | × | ○ | ○ |
| BI Engine | × | ○ | ○ |
| BigQuery ML | × | ○ | ○ |
| キャッシュ利用 | 単一ユーザのみ | ユーザー間でキャッシュをシェア | ユーザー間でキャッシュをシェア |
エディションごとに単価が違うことと、利用可能な機能に差があることに留意してください。
例として CMEK 暗号化(Customer Managed Encryption Key。Cloud KMS で管理する秘密鍵によるストレージの透過的暗号化)や VPC Service Controls といった重要なセキュリティ機能が、Standard エディションでは使えません。このような機能の制約に着目して、適切なエディションを選択します。
なお BigQuery Editions を利用せずオンデマンド課金で BigQuery を利用すると、概ね Enterprise Plus 相当の機能が利用可能ですが、利用可否は機能により異なりますので、以下の公式ドキュメントを参照してください。
クエリがプロジェクトをまたぐ場合
BigQuery では、ある Google Cloud プロジェクトの BigQuery API から、別の Google Cloud プロジェクトの BigQuery テーブルに対するクエリを実行することができます。しかし、データを持つプロジェクトとクエリする側のプロジェクトで異なるエディションが使われている場合はどうなるでしょうか。
以下のようなケースを考えます。
| プロジェクト名 | 内容 |
|---|---|
| Google Cloud プロジェクト A | ・BigQuery は Enterprise Plus エディションを設定 ・データセット・テーブルを保有 ・テーブルには CMEK 暗号化や列レベルセキュリティが設定されている |
| Google Cloud プロジェクト B | ・BigQuery は Standard エディションを設定 ・データセット・テーブルは存在しない |
このとき、プロジェクト A のテーブルに対するクエリを、プロジェクト B の BigQuery API に投入すると、エラーになります。プロジェクト B では Standard エディションが設定されており、CMEK 暗号化や列レベルセキュリティはサポートされていないからです。
つまり、クエリする側のプロジェクト(ジョブを実行するプロジェクト)で、機能をサポートするエディションを選択する必要があります。
BigQuery Autoscaler
BigQuery Autoscaler とは
BigQuery Autoscaler は、需要に応じて自動でスロット確保量を増減する機能です。BigQuery Editions では BigQuery Autoscaler が有効化されており、確保するスロット量が自動的に最適化されます。
BigQuery Autoscaler には、以下のような特徴があります。
- クエリ(ジョブ)の需要に応じて、スロット数が自動増減
- 利用したスロット時間(確保した量 × 時間)に対して課金
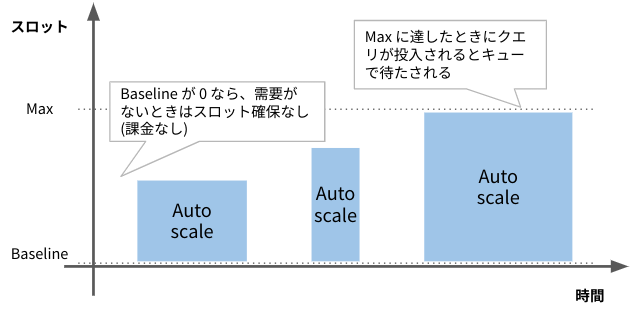
- Baseline(最低確保量)と Max(上限確保量)を設定可能
- Baseline を0に設定すると、BigQuery が使われていない時間帯はスロットがゼロになる
- Max 値を設定することで突発課金を防ぐ
- スケール幅は50スロットずつ
- 1秒単位で課金
- ただし最低でも60秒分から課金される。60秒経過後は1秒単位での課金になる(billed per second with a one minute minimum)
当機能により、BigQuery Editions をオンデマンド課金と同様に柔軟・効率的に利用できます。
Baseline と Max
BigQuery Editions 利用時は、Autoscaler の Baseline(最低値)を0スロットに設定することで、クエリが発生していない時間帯はスロット確保がゼロになり、課金が発生しません。また、Max 値を指定することで、想定外の突発課金を防ぐことができます。
ただし制約として、Standard Edition だけは Baseline が必ず 0 になり、任意の Baseline を設定できません。
スロット確保量が Max 値に達した場合は、クエリがエラーになるわけではありません。新しいクエリはスロットが空くまで待たされます。また投入済みのクエリは、スロット確保量の範囲内で時間をかけて(引き伸ばされて)処理が行われます。
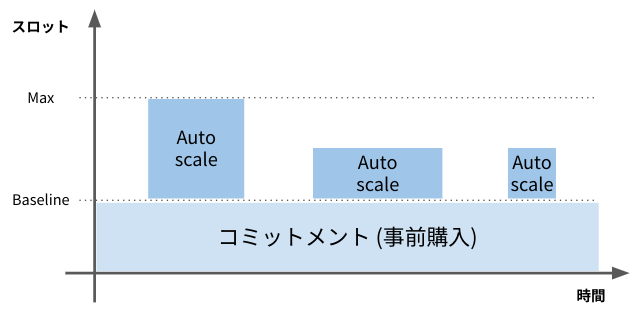
夜間や休日を含めて連続的に BigQuery にクエリが発生している環境の場合、BigQuery Editions の1年または3年のコミットメント(後述)を購入して、購入した分のスロット数を Baseline として設定し、Baseline を超える分については Autoscaler で必要なときのみ確保することで、コスト効率よく利用することが可能です。
コミットメント
Enterprise エディションと Enterprise Plus エディションでは1年または3年のコミットメントを購入できます。
コミットメントとは、1年間または3年間の Editions の利用を確約することであり、一度購入するとキャンセルできない代わりに、割引価格が適用されます。コミットメントは50スロット単位で購入できます。
コミットメントでスロットを購入すると、その分のスロットは常に確保されます。購入したスロットは 予約(Reservation)という管理オブジェクトに Baseline として設定し、Google Cloud プロジェクトに割り当てることができます。
スロットは、Baseline として確保されていても、クエリの処理に使われていない間はアイドルスロットの扱いとなり、他の予約(ただし同等エディションのみ)で分け合って使われます。アイドルスロットについては後に詳述します。
また、予約、割り当て、コミットメントといった概念の詳細については、当記事の「予約、割り当て、コミットメント」の項で詳述します。
いつ Editions を使うべきか
オンデマンド課金が適しているケース
デフォルトでは、BigQuery はオンデマンド課金モードに設定されています。
オンデマンド課金を使い続けるべきか、BigQuery Editions を選択すべきかの判断はどのようにすべきでしょうか。
無料枠内に収まる場合
オンデマンド課金モードには月あたり 1 TB のデータをスキャンできる無料枠(Free tier)があります。スキャンのボリュームが 1 TB を超えない場合は、オンデマンド課金で利用することで、コンピュート料金を無料に抑えることができます(ストレージ料金は発生する点に注意してください)。
BigQuery の利用が散発的な場合
BigQuery へのクエリが発生する頻度が少なく、散発的な利用に留まっている場合も、オンデマンド課金で利用するほうが安価になります。Editions では、一度スロットが確保されると、最低課金時間である60秒分の課金が発生してしまいます。
連続的にクエリが発生しない場合は、オンデマンド課金のほうがコスト効率が良いと言えます。
料金を正確に予測したい場合
オンデマンド課金では、データのスキャン量に応じて課金が発生するため、料金が予測しやすい点も重要です。BigQuery の Web コンソールやコマンドラインでは、クエリのドライランにより、事前にデータのスキャン量を確かめることもできます。
セキュリティ機能の PoC
例えば「普段は Standard Edition を使っているが、VPC Service Controls の機能を検証したい」などの場合に、一時的にオンデマンド課金を利用することも考えられます。なぜなら、オンデマンド課金では Enterprise Plus エディションと概ね同等の機能が利用できるためです(キャッシュのユーザー間シェアなど、一部例外はあります)。
VPC Service Controls や動的データマスキングなどのセキュリティ機能を検証する場合、オンデマンド課金は一時的には選択肢には成り得ます。
BigQuery Editions が適しているケース
連続的に BigQuery へクエリが投入される時間帯がある場合、BigQuery Editions が適している可能性があります。
夜間はバッチジョブが実行され、昼間はダッシュボード参照により継続的にクエリが発行されている場合、データのスキャン量は膨大になります。BigQuery Editions を使えば、スロットを時間ベースの課金で確保できるため、コスト効率が良くなります。
オンデマンド課金で既に BigQuery を利用している場合、後述するスロット見積もりツールを使い、Editions へ移行したあとの料金がどのくらいになるかを確認し、より安くなる可能性があるのであれば、Editions への移行を検討します。
ケーススタディ
ケース ①
BigQuery に対する夜間バッチ等が少なく、利用が日中帯に集中している場合は、以下のような利用方法になります。
- BigQuery Editions + BigQuery Autoscaler を利用
- コミット購入なし
- Baseline を0に設定
- 安全柵として Max slot を100に設定
- 設定値は数ヶ月間の Slot 利用実績を確認して調整
Baseline が 0 のため、BigQuery が利用されていない間はコンピュート課金が発生しません。
利用ボリュームが小さいのにも関わらず Max 値に 800 などの高すぎる値を設定すると、ジョブ(クエリ)が散発的な場合、ジョブ実行時間が短くても重い処理だと 800 スロット × 60 秒の最低課金が発生してしまい、これが積み重なって料金が高くなってしまう場合があります。
まずは 100 や 200 などの小さい値から始め、ジョブ実行時間が実業務で耐えうる範囲なのかどうかを確認するのが望ましいでしょう。後述する管理リソースグラフを使い、スロットの利用状況をモニタリングすることができます。
ケース ②
夜間・休日はバッチ処理が BigQuery に対して実行されており、日中帯は従業員の BI ツールやオンデマンドなクエリにより BigQuery が利用されているというケースを想定します。このようなケースでは、1日を通して、また月間を通して BigQuery の利用ボリュームが比較的大きく、ほぼ常時、スロットが使われているとします。
- BigQuery Editions + BigQuery Autoscaler を利用
- コミットメントを購入し、Baseline 値として設定
- 常に確保しておくスロット分、コミットメントを購入
- リソースグラフを確認して無駄なく使い切れる値に設定する
- 安全柵として Max 値を設定
- 設定値は数ヶ月間の Slot 利用実績を確認して調整
- 利用料金と処理効率のバランスを取って設定
- Max 値が高すぎると、クエリが散発的で小さい場合でも60秒分の課金が発生するので注意
ケース ③
一部の部署のみが BigQuery を利用している。もしくは PoC レベルであり無料枠に収まる可能性が高い場合、オンデマンド課金が適しています。
- オンデマンド課金を利用
まだ BigQuery の利用が小規模であり、スキャン量が 1 TB に満たない可能性がほとんどの場合は、無料枠が用意されているオンデマンド課金を利用します。ストレージ容量も、10 GB までは無料です。
ケース ④
一部の部署のみが BigQuery を利用しており、データアナリストやマーケティング部門による、探索的なクエリが散発的に発生する場合を考えます。このような場合、オンデマンド課金が適しています。
- オンデマンド課金を利用
散発的で小さいクエリが主なユースケースの場合、BigQuery Editions を使うと、60秒の最低課金が逆にコスト効率を悪くする場合があります。このようなとき、オンデマンド課金を選択します。
サイジングと料金の見積もり
サイジングの概要
BigQuery Editions では 予約(Reservation)というオブジェクトを作成してプロジェクトに BigQuery Editions を適用します。予約を作成する際、適用するエディション(Standard、Enterprise、Enterprise Plus)と、Autoscaler の Baseline 値と Max 値を指定します。
Baseline 値は、1年または3年のコミットメントを購入していれば、それを使い切るように設定するのが一般的です。
一方の Max 値は、パフォーマンスとコスト(料金)を天秤にかけて決定する必要があります。
コンソール画面では、Max 値はプルダウンメニューで以下のように選択できるようになっています。S、M、L といった名称が付いてはいますが実際には利用環境に応じて適切な値を選択することが望ましいです。
| 名称 | スロット数 |
|---|---|
| Extra Small | 50 |
| S | 100 |
| M | 200 |
| L | 400 |
| XL | 800 |
| 2XL | 1,600 |
| 3XL | 3,200 |
| 4XL | 4,800 |
| Custom | 任意の数値 |
スモールスタート
まずは 50〜200 など小さめのスロット数を Max に設定しでスモールスタートすることを検討します。
BigQuery に対するクエリが散発的であるのにも関わらず 800 など大きめのスロット数を Max としてしまうと、以下のようなことが起こります。
- 比較的重いクエリが1個、投入される
- そのクエリを処理するために800スロットが確保され、処理が1秒で終わる
- 処理が1秒で終わっても、スロットの最低課金時間は60秒のため、800 スロット × 60秒の課金が発生
このケースでは、1個のクエリを実行するためだけに800スロット × 60秒の課金が発生することになり、無駄が大きいことがわかります。
一方で同じクエリを処理する場合で Max 値が200の場合、以下のような挙動になります。
- 先程と同じクエリが投入される
- 200スロットが確保され、処理が4秒で終わる
- スロットの最低課金時間は60秒のため200スロット × 60秒の課金が発生
この場合はスロット数が4分の1のため処理時間が4倍掛かっていますが、料金も4分の1です。
ただし、同時間帯に多数のクエリが投入されるような環境であれば、60秒間で確保されたスロットが無駄なく使われることになりますので、どのくらいの頻度・密度でクエリが実行されるかを考慮に入れて、Max 値を検討する必要があります。
料金の基本的な考え方
BigQuery Editions の料金を見積もるには、(スロット単価)×(スロット時間)を計算します。
スロット単価はエディションによって異なりますので、料金ページを確認します。どのエディションを選択するかは、前掲の機能表を参考にしてください。
- 参考 : BigQuery pricing
スロット時間は、(確保されたスロット量) × (確保された時間)を意味しています。スロット量は、クエリの需要に応じて Baseline から Max の間で確保されます。また、確保時間は、クエリの頻度と処理の重さに依存しますので、予測が難しいものとなります。
例えば、100スロットが6分間(=0.1時間)確保されると、スロット時間は「10スロット時間(10 slot hour)」となります。US リージョンの Enterprise エディションの単価は $0.06 / slot hour ですので、このときかかるコンピュート料金は、$0.06 × 10 = $0.6 となります。
もし既に BigQuery を利用中であれば、後述のスロット見積もりツールで実績ベースの見積もりを確認することができますが、これから初めて BigQuery を使う場合は、見積もりの難易度は高くなります。
オンデマンド課金で PoC を行ってある程度のスロット利用量の目算をつけたり、小さめの Max 値でスモールスタートして利用実績を積み、徐々にスロット数を増やしていくのが望ましいといえます。
スロット見積もりツール
BigQuery の Web コンソールには スロット見積もりツール(Slot estimator)が用意されており、既存の BigQuery ユーザーであれば、BigQuery Editions の見積もりに利用できます。
スロット見積もりツールは、過去30日間の利用実績から、パフォーマンスをできるだけ落とさずにコスト最適化するために推奨される Baseline 値や Max 値を表示したり、想定月額費用を表示します。
スロット見積もりツールは、BigQuery コンソールの「容量管理」画面から「スロット見積もりツール」画面へ遷移することで閲覧が可能です。
ただし、あくまで目安であり、コストを優先したい場合は表示されているよりも Max 値を小さくして設定するなど、判断はあくまで運用者がする必要があります。
- 参考 : スロットの容量要件の見積もり

また BigQuery コンソールでは、費用の最適化に関するレコメンデーション(推奨事項)を表示する Slot Recommender が利用できます。Slot Recommender は過去30日間のスロット使用量に基づいて自動スケーリングの使用量を推定し、推奨される設定値をレコメンドしてくれます。
過去実績の確認
既に BigQuery を利用中の場合、前述の基本的な考え方を踏まえた上で、これまでのクエリのスロット利用実績から Max 値の当たりをつけることもできます。
管理リソースグラフ(administrative resource charts)を使うことで、過去のスロット利用実績を確認可能です。
オンデマンドモードを利用中の場合、セレクタで利用リージョンを選択のうえ、チャートを「オンデマンド料金」「スロットの使用状況」とすることで、過去の特定時間帯の平均スロット利用量を確認できます。これにより、Max 値を例えば 100 に設定した際に、どの時間帯のジョブのパフォーマンスが落ちる可能性があるかを確認することができます。

例えば上記の例だと、あるオンデマンド課金を利用している組織の、99パーセンタイル(全ジョブの中でスロット使用量が上位1%のジョブ)の「平均スロット使用量」を表示しています。スパイク的に 2,000 近くまでスロットが確保されている時間帯がある一方で、ほとんどの時間帯は 100 以下に収まっていることが分かります。 選択した期間中の平均は 9.3 スロットでした。
このような場合、Max 値を例えば「100 スロット」に設定することを検討します。しかし、スパイクしている時間帯のジョブはその分引き伸ばされてしまうことになります。具体的にどんなクエリが影響を受けるかは INFORMATION_SCHEMA.JOBS ビューなどで個別に確認してください。
予約、割り当て、コミットメント
基本的な概念
BigQuery Editions を利用するには、予約(Reservation)、割り当て(Assignment)、コミットメント(Commitment)と呼ばれる管理用オブジェクトを作成します。
これらの管理オブジェクトの関係の例を模式図にすると、以下のようになります。

予約(Reservation)
予約(Reservation)は BigQuery Editions の管理オブジェクトです。利用するエディション、Baseline 値、Max 値などの設定値を持っています。
「予約」という名称から、1年間や3年間の利用コミットがされてしまうのではないか、と誤解されがちですが、「予約」は長期コミットメントとは関係がありません。予約と、後述する割り当てを作成して BigQuery Editions を利用開始しても、割り当てを削除することで、Editions の利用をやめていつでもオンデマンド課金に戻ることができます。
予約は Google Cloud プロジェクト内に作成し、またロケーション(リージョン)ごとに作成します。
割り当て(Assignment)
割り当て(Assignment)は、予約と Google Cloud プロジェクトを紐づけるリレーションです。BigQuery Editions を利用するには、予約を作成した後、割り当てを作成して予約と Google Cloud プロジェクトを紐づけます。
割り当ては Google Cloud プロジェクトに対してだけでなく、組織やフォルダに対して作成することもできます。組織やフォルダに割り当てを作成した場合、予約が配下のプロジェクトに継承されます。プロジェクトに割り当てがない場合、継承された親リソースの予約(割り当て)が利用されます。
なお、継承された予約(割り当て)を使用せず、明示的にオンデマンド課金を利用するようにプロジェクトを設定することもできます。
割り当てを作成するときには、ジョブタイプを指定します。プロジェクトに割り当てられた予約は、指定されたジョブタイプのジョブのために使われます。
| ジョブタイプ | 説明 |
|---|---|
| QUERY | SQL や BigQuery ML の組み込みモデルの実行 |
| BACKGROUND | 検索インデックス管理、CDC、BigLake メタデータキャッシングなどのバックグランドジョブ (※1) |
| CONTINUOUS | 継続的クエリ |
| ML_EXTERNAL | BigQuery ML の外部モデルの CREATE MODEL クエリ (※1) |
| PIPELINE | LOAD や EXPORT 等 (※2) |
(※1) Standard エディションの予約は、BACKGROUND と ML_EXTERNAL としては割り当てることができません。
(※2) LOAD や EXPORT 等のジョブは無料ですが、スループットを保証していません。性能を確保したい場合に PIPELINE として割り当てを作成します。
コミットメント(Commitment)
コミットメント(Commitment)は1年間また3年間のスロット予約を確約ための仕組みです。コミットメントを作成することで、割引価格でスロットを利用することができます。コミットメントは一度作成すると、解約することはできません。コミットメントや予約はロケーション(リージョン)ごとに作成します。コミットメントで確保されたスロットは、同じロケーションの予約によって利用されます。
コミットメントは、50スロットを最小とし、50スロットの倍数で購入することができます。
また、コミットメントの自動更新を設定することもできます。コミットメントには更新プランを「なし(None)」「年間(Annual)」「3年間(Three-Year)」の中から選択でき、コミットメント期限が切れたときの自動更新の挙動を事前に設定できます。「なし」であれば更新はされません。「年間」であれば、1年間のコミットメントとして、「3年間」であれば3年間のコミットメントとして更新されます。
管理プロジェクト
予約、割り当て、コミットメントは、Google Cloud プロジェクトの中に作成されます。
Google は、これらのオブジェクトを単一の管理用の Google Cloud プロジェクトに集約して作成することを推奨しています。このプロジェクトを管理プロジェクトと呼びます。
管理プロジェクトにこれらの管理オブジェクトを集約することで、後述するアイドルスロットを共有できるようになったり、見通しが良くなって管理工数が低減するなどのメリットがあります。
アイドルスロット
コミットメントによって購入されたスロットは、予約の Baseline 値として使用されます。原則的には、Baseline として設定された分のスロットは常時確保されるのですが、クエリが処理されていないときには、スロットはアイドルスロットという扱いになります。
また、コミットメントとして購入されているが、どの予約のベースラインとしても使われていないスロットも、アイドルスロットになります。
アイドルスロットは、他の予約から利用することができます。ただし、エディションやロケーションが同じであること、スロットを共有する予約同士が同じ管理プロジェクトに所属していること、などが条件です。
予約で、設定値 ignore_idle_slots を true に設定することで、他の予約のアイドルスロットを使用しないように明示的に設定することもできます。
- 参考 : スロットについて - アイドル スロット
管理プロジェクト内に複数の予約が存在し、アイドルスロットがどのように予約に分配されるかを細かく調整したい場合は、予約ベースの公平性(Reservation-based fairness)と、予約の予測可能性(Reservation predictability)いう設定値を使って、調整することもできます。
- 参考 : Understand slots - Reservation-based fairness
- 参考 : Workload management using reservations - Reservation predictability
プロジェクト内での使い分け
ある Google Cloud プロジェクトで実行される BigQuery ジョブは、ロケーション(リージョン)ごとに作成される予約を使用するため、あるプロジェクトのあるロケーションのジョブは、Editions を使うか、オンデマンド課金を使うか、原則的にどちらか1つになります。しかし、1つのプロジェクト・リージョンで、ジョブ(クエリ等)ごとに使う予約を切り替えることもできます。
- 参考 : Workload management using reservations - Flexibly assign reservations
- 参考 : Work with reservation assignments - Override a reservation on a query
この機能を使うと、Editions を使うか、オンデマンド課金を使うかをジョブごとに切り替えることができます。上記のドキュメントに従い、Web コンソール、bq コマンド、API 経由でのジョブ実行時に、使用する予約を指定できます。ただし、2025年7月現在、ジョブ実行時の予約指定は Preview 公開のステータスです。一般提供(GA)までに仕様が変更したり機能が廃止される可能性もあるため、本番環境での利用は推奨されないものとされています。
杉村 勇馬 (記事一覧)
執行役員 CTO / クラウドソリューション部 部長
元警察官という経歴を持つ現 IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it