


G-gen の杉村です。当記事は BigQuery について徹底的に解説する記事の応用編です。BigQuery に初めて触れる方は、まず基本編の記事をご参照ください。
- 基本編の記事
- 外部データ連携の概要図
- 外部テーブル
- BigLake
- BigQuery Omni
- 連携クエリ、連携データセット
- Apache Iceberg 対応
- モニタリング
- チューニング
- 同時実行とリソース
- コスト削減
- BigQuery ML
- データリネージ
- BigQuery Sharing
- 非構造化データの分析
- 高度なセキュリティ
- BigQuery BI Engine
- 開発

基本編の記事
当記事は BigQueryを徹底解説する記事の「応用編」です。基礎的な内容は「基本編」で解説しています。基本編で扱った内容は、以下のとおりです。
- 概要
- 料金
- コンポーネント
- データのロード
- データのクエリ
- エクスポート
- 可用性と耐久性
- バックアップ
- データパイプライン(ELT/ETL)
- データカタログ(BigQuery universal catalog)
- アクセス制御
- セキュリティ関連機能
- テーブル設計
- Gemini in BigQuery
当記事は応用編として、さらに詳細な内容に踏み込んでいきます。
外部データ連携の概要図
BigQuery は、内部ストレージに持っているデータだけでなく、外部サービスのデータをクエリすることが可能です。応用編記事ではいくつかの仕組みについて解説します。概要は以下の図のようになっています。
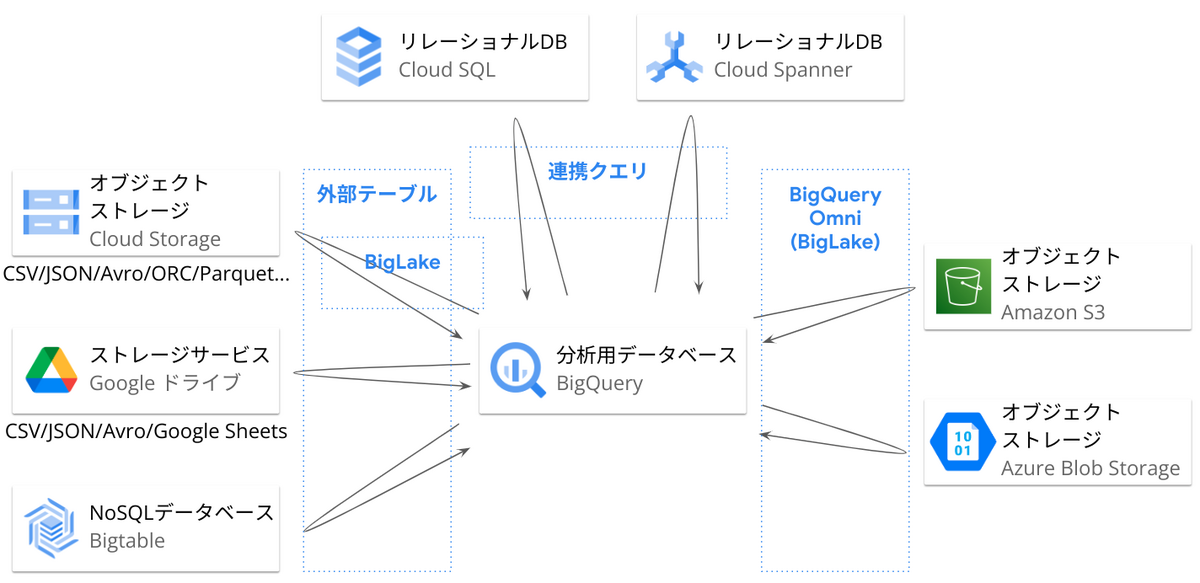
この図に表されている外部テーブル、連携クエリ(Federated query)、BigQuery Omni、BigLake については、それぞれ当記事内で解説します。
外部テーブル
外部テーブルとは
外部テーブルは BigQuery ストレージの外にあるデータを BigQuery から直接クエリできる仕組みです。以下のようなデータソースに対応しています。
- Cloud Storage
- Cloud Bigtable
- Google ドライブ
外部テーブルではスキーマ定義とメタデータだけを持ち、データの実体は外部に置いたままです。そのため BigQuery 内部のデータをクエリするよりも、パフォーマンスは劣ります。その代わり、データを定期的に BigQuery にロードすることなく最新のデータが得られたり、ELT パイプライン構築の必要性が無いというメリットがあります。
- 参考 : 外部テーブルの概要
なお Cloud Storage への外部テーブル定義の場合、外部テーブルの発展系である BigLake テーブル(後述)の利用が推奨されています。BigLake テーブルのほうが、よりきめ細かい制御が可能なうえ、テーブルのアクセス制御とデータソースへのアクセス制御を分離できるため、運用の簡素化にもつながります。
用途
外部テーブルの用途として、ELT 処理の中で外部テーブルに対して CREATE TABLE xxx AS SELECT 〜 や INSERT INTO xxx SELECT 〜 を行い BigQuery へのデータロードを行ったり、あるいは頻繁に変更がある外部データを、都度 BigQuery に取り込むことなく分析するなどが挙げられます。
外部テーブルでは外部データソースにアクセスするオーバーヘッドがあるため、通常のテーブルに比べるとパフォーマンスは劣ります。外部テーブルは、外部からのデータのロードや、小規模なマスターデータの SELECT など、適切なポイントで利用する必要があります。
Cloud Storage 外部テーブル
Cloud Storage に対する外部テーブルでは、以下のファイル形式に対応しています。
- CSV
- JSON(改行区切り)
- Avro
- ORC
- Parquet
- Datastore エクスポート
- Firestore エクスポート
例として、業務システムから定期的に Cloud Storage へデータをアップロードするような仕組みにしておき、BigQuery からは定期的に Cloud Storage 上のファイルを外部テーブルから INSERT INTO xxx SELECT 〜 するパイプラインを構築すれば、疎結合なデータ受け渡し場所として Cloud Storage が利用可能です。
Google ドライブ外部テーブル
Google ドライブに対する外部テーブルでは、以下のファイル形式に対応しています。
- CSV
- JSON(改行区切り)
- Avro
- Google スプレッドシート
BigQuery は、CSV や JSON のほか、Google スプレッドシートのデータもテーブルとして認識できます。そのため、従業員が普段使っているスプレッドシートの台帳をテーブルとして使い、ELT や分析に使うことが容易です。外部テーブルへのクエリでは常に最新のデータが得られるため、リフレッシュのためのバッチ処理が不要です。
- 参考 : ドライブデータをクエリする
以下の記事も参考にしてください。
Bigtable 外部テーブル
Bigtable は、Google Cloud のマネージドな NoSQL データベースサービスです。
Bigtable は行と列の概念を持ちますが、NoSQL であるため独特のスキーマ構造をしています。詳細は以下のドキュメントをご参照ください。
BigLake
BigLake とは
BigLake は、アクセス権限の委任を使用して、BigQuery 外部のストレージにあるデータをクエリするための仕組みです。BigLake の仕組みで作成されたテーブルは BigLake テーブルと呼ばれ、外部テーブルの発展系とされています。
BigLake テーブルでは「ユーザからテーブルへのアクセス権限」と「テーブル (BigQuery) からデータソースへのアクセス権限」を分けて考えます。テーブルをクエリするユーザは、BigLake テーブルへのアクセス権限だけがあればよく、データソースからテーブルへデータを取得する権限は接続(Connection。基本編を参照)に紐付けられたサービスアカウントの権限で行われます。

なお BigQuery Omni を使うテーブルは、常に BigLake テーブルです。接続(Connection)に AWS の IAM ロールの認証情報を持たせることで、Amazon S3 のデータをクエリできます。
- 参考 : BigLake テーブルの概要
データソース
BigLake テーブルに対応しているデータソースは、以下です。
- Cloud Storage
- Amazon S3(BigQuery Omni)
- Azure Blob Storage(BigQuery Omni)
通常の外部テーブルとの違い

BigLake テーブルではない通常の外部テーブルでは、テーブルをクエリするユーザは、テーブルへのアクセス権限と同時にデータソースへのアクセス権限も持つ必要があります。
すなわち、通常の外部テーブルと BigLake テーブルの違いは、クエリを行うユーザがデータソースへのアクセス権限を持っている必要があるか、ないか、という点になります。
利点
BigLake の最大の利点は、権限管理運用の簡素化です。
通常の外部テーブルでは、テーブルを新規作成したり、あるいは既存の外部テーブルへアクセスできる人を増やす、あるいは減らす場合などに「Cloud Storage 等のデータソースへのアクセス権限」と「テーブルへのアクセス権限」の両方を編集する必要があります。BigLake ではこれらの権限が分離され疎結合になるため、運用の簡素化に繋がります。
また、BigLake テーブルではデータソースへのアクセス権限とテーブルレベルのアクセス権限を分けられるため、以下のような機能が使えるようになります。
- 行レベル・列レベルセキュリティ
- 動的データマスキング(Cloud Storage のみ)
BigLake テーブルでなければ、ユーザはデータソースのファイルへのアクセス権限をまるごと持つため、上記のような細かい制御は意味を成しません。BigLake ではユーザのアクセス権限をテーブルレベルで制御できるため、上記のような細かい粒度でのアクセス制御ができるようになります。
これらの利点から、特に Cloud Storage への外部テーブルを作成する場合は、BigLake テーブルを利用することが推奨されています。
権限の持たせ方
接続(Connection)を作成する際に、BigLake の種類を選択します。接続先環境によって、権限を持たせるための手順は異なります。
Cloud Storage 用の BigLake 接続を作成すると、サービスアカウント ID が払い出されるので、そのサービスアカウントに、対象の Cloud Storage の読み取り権限を持たせます。
Amazon S3 用の BigLake 接続では、IAM ロールの ARN を指定し、IAM ロール側の信頼関係ポリシーで接続の ID を信頼します。
Azure Blob では Federated Identity の利用有無により、方法が異なります。
それぞれ、詳細は公式ドキュメントをご参照ください。
- 参考 : Cloud リソース接続を作成して設定する
- 参考 : Amazon S3 に接続する
- 参考 : Blob ストレージに接続する
BigQuery コネクタ
BigQuery コネクタ(BigLake コネクタ)は、BigLake の追加機能の一つです。
BigQuery コネクタにより、Apache Spark、Apache Hive、TensorFlow、Trino、Presto など、BigQuery 以外のデータ処理ツールから、BigLake テーブルへのアクセスが可能になります。
- 参考 : コネクタ
BigQuery Omni
BigQuery Omni とは
BigQuery Omni は他のクラウドサービスとデータ連携を行い、BigQuery でのデータ分析を可能にする仕組みです。
データは Amazon S3 や Azure Blob に置いたまま、BigQuery のコンピュート能力を活かしてデータを分析したり、あるいは BigQuery へデータをロードすることもできます。クエリは Google が管理するクラスタで行われるため、AWS や Azure 側でデータのアウトバウンド転送料金は発生しません。
認証には、BigLake の仕組みを用います。BigQuery Omni では、AWS の IAM ロール等の認証情報を接続(Connection)に登録して認証します。
- 参考 : BigQuery Omni の概要
対応サービス
BigQuery Omni は以下のサービスに対応しています。
- Amazon S3(Amazon Web Services)
- Azure Blob Storage(Microsoft Azure)
注意点
BigQuery Omni は、業務システムが Amazon Web Services(AWS)でホストされており、データ分析基盤は Google Cloud(BigQuery)にあるような組織で特に有用です。ただし、特に日本のユーザーにとっての注意点としては、Amazon S3、Azure Blob ともに日本国内のリージョンに未対応である点です。以下の公式ドキュメントをご参照ください。
また BigQuery Omni では、通常のクエリとは異なる料金体系が適用されることに注意が必要です。
連携クエリ、連携データセット
連携クエリ(Federated query)とは
連携クエリ(Federated query)は BigQuery から他のデータベースエンジンへクエリを送信し、結果を返してもらう機能です。
外部テーブルとの違いは、クエリの相手先がデータベースエンジンであり、相手先のコンピュートリソースを使って処理された結果を BigQuery が受け取るという点です。
連携クエリは、以下のデータソースに対応しています。
- Spanner
- Cloud SQL
- AlloyDB for PostgreSQL
- SAP Datasphere(2025年4月現在、Preview)
クエリを実行する BigQuery のロケーション(リージョン)と、連携クエリの対象データベースのロケーションは同じである必要がある、などの制限があります。詳細は公式ドキュメントを確認してください。
- 参考 : 連携クエリの概要
連携データセット(Federated datasets)
連携データセット(Federated datasets)、または外部データセット(External datasets)とは、Spanner のデータベース全体を BigQuery と連携し、テーブル一覧やスキーマ情報の閲覧を可能にするほか、BigQuery から Spanner への読み取りクエリを可能にする機能です。
連携クエリでは、BigQuery で接続(Connection)を作成し、EXTERNAL_QUERY 関数で Spanner データベース内のテーブルを指定してクエリを実行する一方、連携データセットでは BigQuery で外部データセットを作成することで、FROM 句で外部データセット内のテーブルを直接指定してクエリを実行できます。
詳細は、以下の記事を参照してください。
Apache Iceberg 対応
BigLake tables for Apache Iceberg in BigQuery
BigLake tables for Apache Iceberg in BigQuery の機能により、Cloud Storage に保存された Iceberg テーブルをクエリしたり、変更したりすることができます。
Apache Iceberg は、大規模な分析用テーブルを効率的に管理するために設計されたオープンソースのテーブルフォーマットです。Iceberg では、データファイルとメタデータファイルのセットを使ってテーブルを定義します。これにより、データ変更の追跡、スキーマの進化、タイムトラベルクエリ、アトミックなトランザクションなどの高度な機能を実現します。Iceberg はデータファイル形式として ORC、Avro、Parquet などをサポートしていますが、BigQuery では Parquet に対応しています。
当機能によって作成されたテーブルは BigLake Iceberg tables in BigQuery とも呼ばれます。当機能では、BigLake の仕組みにより Cloud Storage に認証し、Cloud Storage 上に保存された Iceberg データを読み書きします。
Apache Iceberg read-only external tables
Apache Iceberg read-only external tables は、前述の BigLake Iceberg tables in BigQuery とは異なり、読み取り専用の定義方法です。
Cloud Storage 上の Iceberg テーブルを指定して、読み取り専用の外部テーブルを定義します。定義方法には「BigLake metastore を使う方法」と「JSON 形式のメタデータファイルを指定する方法」の2通りがあります。
モニタリング
INFORMATION_SCHEMA
INFORMATION_SCHEMA は、BigQuery の各種オブジェクトの情報を格納したシステムビューです。INFORMATION_SCHEMA は読み取り専用であり、多くの場合、リアルタイムで最新の情報が格納されています。
このビューをクエリすることで、BigQuery のテーブル、ジョブ、インデックスなどの各種情報を確認することができます。以下は、代表的なものだけをピックアップしたものです。
| ビュー名 | 内容 |
|---|---|
| TABLES | テーブル情報。テーブル名、スキーマ、作成時間、更新時間、DDL 等 |
| TABLE_STORAGE | テーブルのストレージ情報。テーブル名、物理バイト、論理バイト、タイムトラベルストレージ量、フェイルセーフストレージ量等 |
| SCHEMATA | データセット情報。名称、作成日時、更新日時、ロケーション、DDL 等 |
| JOBS | ジョブ情報。ID、キャッシュヒット有無、作成日時、終了日時、エラーコード、SQL 等 |
クエリ時は、以下のようにプロジェクト ID(省略可)やロケーション名などを付与してクエリします。
SELECT * FROM `region-asia-northeast1`.INFORMATION_SCHEMA.TABLES;
INFORMATION_SCHEMA のビューには、プロジェクト単位や組織単位など、複数のレベルのビューが用意されていることがあります。
INFORMATION_SCHEMA のビューの一覧は、以下の公式ドキュメントを参照してください。
リソースモニタリング
BigQuery の Web コンソール画面やシステムビューには、各種モニタリングツールが用意されています。
- リソース使用率のモニタリング
- 予約(reservations)のモニタリング
- マテリアライズドビューのモニタリング
- BI Engine のモニタリング
具体的な方法については、以下のドキュメントを参考にしてください。
管理ジョブエクスプローラ
管理ジョブエクスプローラ(administrative jobs explorer、または単にジョブエクスプローラ)は、プロジェクトで実行されたジョブの一覧を確認することができる画面です。
同画面では、ジョブ一覧を各種属性でフィルタしたり、ソートすることができます。時間がかかっているジョブを確認し、最適化するために役立てることができます。
また、ジョブごとのスキャン量や占有したスロット量も確認できるため、コスト最適化に用いることができます。BigQuery の料金を節約したいとき、まずジョブエクスプローラでスキャン量やスロット占有量が大きいジョブを特定することが有用です。
- 参考 : 管理ジョブ エクスプローラを使用する

チューニング
パフォーマンスのためのテーブル設計
BigQuery においてパフォーマンスを最適化するためのテーブル設計は、まずは基本編で解説した「パーティショニング」と「クラスタリング」、また「非正規化」などのテクニックが重要です。
BigQuery では一般的な RDBMS(リレーショナルデータベースマネジメントシステム)とは異なり、インデックスを用いた検索パフォーマンス最適化は、特定のケースでのみ行われます。
詳細は、基本編の記事の「テーブル設計」の項を参照してください。
クエリプラン(実行計画)
BigQuery では、他の DBMS で EXPLAIN で取得できるようなクエリプラン(実行計画)の確認が可能です。
クエリジョブが投入されると、BigQuery は SQL を複数のクエリステージに分割し、さらにクエリステージは細かいステップに分割されます。複数のワーカーがクエリステージを並列実行するため、高速に処理されます。またクエリジョブの進捗はタイムラインで表現され、保留中・実行中・完了済の作業単位が確認できます。
クエリプランは、Google Cloud コンソールでジョブごとに確認できます。「実行の詳細」タブでは詳細を、「実行グラフ」タブではグラフィカルなフロー図を確認できます。

クエリとテーブルの最適化
想定よりもクエリが遅い場合は、クエリプランやタイムラインを参考に、SQL をチューニングします。また SQL の記述方法やテーブル設計のベストプラクティスに沿うことも重要です。例として、以下のようなベストプラクティスがあります。
- テーブルを非正規化して ネスト(
STRUCT)列やREPEATED列を使う WHERE句はSTRINGやBYTEより、BOOL、INT、FLOAT、DATEの方が高速REGEXP_CONTAINS()ではなくLIKEを使用- 不要な列を
SELECTしない - パーティションやクラスタリングを使用
JOINの前にデータを減らす- 複雑で長大なクエリをマルチステートメントクエリに分割し一時テーブルを活用
- 自己結合よりウインドウ関数
詳細は、以下の公式ドキュメントも参照してください。以下のページをはじめ、公式ドキュメントにはクエリパフォーマンスを最適化するための Tips が数多く用意されています。
- 参考 : クエリ パフォーマンスの最適化の概要
- 参考 : クエリ計算を最適化する
主キー制約・外部キー制約
BigQuery には、主キー制約(Primary Key Constraints)と外部キー制約(Foreign Key Constraints)が存在します。
しかし、これらの制約に強制力は無く(NOT ENFORCED)、主キー制約を設定した列でも値が重複できますし、外部キー制約を入れた列も行の追加・削除等に制限がかかりません。これらの制約の存在理由は、実行計画の最適化にあります。
BigQuery で主キー制約・外部キー制約を定義すると、それらに基づいてクエリオプティマイザがクエリプランを最適化し、JOIN 処理が高速化やスキャンボリュームの最適化に繋がる可能性があります。クエリプランの最適化は、コンピュート料金の最適化にも繋がります。
ただし「主キー制約をかけた列は NULL でなく一意であること」また「外部キー制約をかけた列は参照先テーブルで主キーであること」などの本来の制約条件はシステム的には強制されないため、これを守る義務はユーザー側にあります。データが制約に違反している場合、誤った結果が返される恐れがあるとされています。
詳細な概念として、Inner Join Elimination(内部結合解除)、Outer Join Elimination(外部結合解除)、Join Reordering(結合順序変更)が以下の公式記事で紹介されています。
レコメンデーション
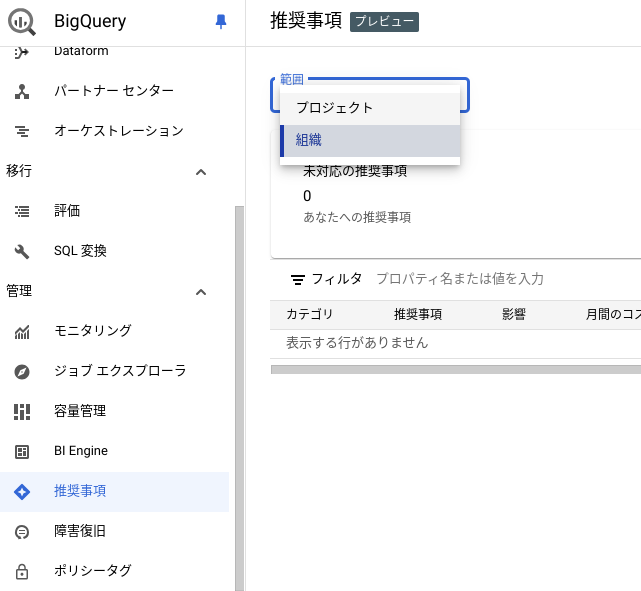
BigQuery の Web コンソール(BigQuery Studio)では、パフォーマンスチューニングやコスト削減に役立つ推奨事項(Recommendations)を一覧表示できます。BigQuery は、AI/ML も活用し、以下のような推奨事項を表示します。
- パーティショニングとクラスタリングの推奨事項
- マテリアライズド ビューの推奨事項
- IAM の推奨事項
例えば、「パーティショニングとクラスタリングの推奨事項」では過去30日間の利用実績に基づいて、どのテーブルのどの列にパーティショニングやクラスタリングを設定すべきかを推奨してくれます。詳細は以下のドキュメントも参照してください。
- 参考 : 推奨事項の概要
推奨事項はプロジェクト単位で閲覧できるほか、適切な権限を持っていれば組織レベルでも閲覧できます。
同時実行とリソース
クエリの同時実行
BigQuery はサーバーレスのサービスであり、分散アーキテクチャを採用しているため、高度な並列処理が可能です。
クエリの同時実行数は、オンデマンドモードの場合はプロジェクトごとに、BigQuery Editions を使っている場合は予約(Reservation)ごとに決まります。
オンデマンドモードのプロジェクトでは、クエリの最大同時実行数は動的に決まります。
一方で予約(Reservation)を使っているプロジェクト、すなわち Editions が割り当てられているプロジェクトでは、最大同時実行数を明示的に設定できます。
- 参考 : Use query queues
フェアスケジューリング
クエリが並列で実行される際、リソース(スロット)の割り当ては BigQuery によって動的に決まります。この割り当ての仕組みをフェアスケジューリングと呼びます。
フェアスケジューリングにより、プロジェクト間やジョブ間で自動的にスロットが分配されます。スロットを大きく要するクエリには大きなスロット数が、そうでないクエリには少ないスロット数が動的に割り当てられます。
クエリキュー
オンデマンドモードであるか、Editions であるかに関わらず、BigQuery にはクエリキューの概念があります。前述の仕様で決定した最大同時実行数を超えたクエリは、キューに溜まります。
インタラクティブクエリの場合は最大 1,000、バッチクエリの場合は最大 20,000 クエリがキューに滞留することができ、それを超えたクエリ投入はエラーになります。
- 参考 : クエリキューを使用する
コスト削減
コスト削減のベストプラクティス
BigQuery にはコスト削減のためのベストプラクティスも存在します。以下の記事をご参照ください。
上限設定
BigQuery のオンデマンド課金が一定以上にならないように、クエリ量に上限設定をすることが可能です。以下をご参照ください。
BigQuery ML
BigQuery ML とは
BigQuery ML とは、BigQuery の SQL インターフェイスを使って機械学習モデルをトレーニングしたり、推論を実行できる機能です。トレーニングや推論には、BigQuery 内のデータをシームレスに利用できます。
機械学習の専門知識がなくても、SQL による呼び出しで、以下のような組み込みモデルをトレーニング可能です。
- 線形回帰
- ロジスティック回帰
- K-means クラスタリング
- 行列分解(Matrix factorization)
- 主成分分析 (PCA)
- 時系列予測
また Vertex AI や AutoML でトレーニングしたモデルを利用することも可能です。こちらではディープニューラルネットワークやランダムフォレスト、ブーストツリーなども利用できます。
BigQuery ML のモデルを Vertex AI Model Registry に登録して、オンライン推論用のエンドポイントにデプロイすることも可能です。
- 参考 : BigQuery ML とは
徹底解説記事
以下の記事では BigQuery ML を詳細に解説していますので、ご参照ください。
利用例
以下のように SQL 構文で BigQuery ML を利用することができます。以下は、モデル作成の例です。
#standardSQL CREATE MODEL `bqml_tutorial.sample_model` OPTIONS(model_type='logistic_reg') AS SELECT IF(totals.transactions IS NULL, 0, 1) AS label, IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(geoNetwork.country, "") AS country, IFNULL(totals.pageviews, 0) AS pageviews FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20160801' AND '20170630'
上記は bqml_tutorial データセットの中に sample_model というモデルを作成しています。
パブリックデータセット上のデータ bigquery-public-data.google_analytics_sample.ga_sessions_* を利用してロジスティック回帰モデルをトレーニングしています。
推論は以下のように行います。
#standardSQL SELECT country, SUM(predicted_label) as total_predicted_purchases FROM ML.PREDICT(MODEL `bqml_tutorial.sample_model`, ( SELECT IFNULL(device.operatingSystem, "") AS os, device.isMobile AS is_mobile, IFNULL(totals.pageviews, 0) AS pageviews, IFNULL(geoNetwork.country, "") AS country FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` WHERE _TABLE_SUFFIX BETWEEN '20170701' AND '20170801')) GROUP BY country ORDER BY total_predicted_purchases DESC LIMIT 10
モデルが推論した結果は predicted_(元カラム名) という列に出力されます。
料金
BigQuery の課金モードがオンデマンドの場合、処理したデータ量に応じて課金が発生します。モデル作成と推論では料金単価が異なる点に注意が必要です。
BigQuery Editions を利用する場合は、BigQuery ML 内部モデルの作成・推論には Editions の QUERY 割り当てが利用されます。Vertex AI など外部モデルの利用には ML_EXTERNAL が使われます。
BigQuery ML 外部モデルの場合は Vertex AI などの利用料金も発生します。
料金表は以下をご参照ください。
- 参考 : BigQuery ML pricing
データリネージ
BigQuery では、データリネージを表示することができます。データリネージとは、ある BigQuery テーブルのデータがどこから来て、どこに渡されているかなど、データの出自を特定できる情報です。データリネージは、Dataplexの1機能として提供されています。
有効化すると、テーブルごとにグラフが生成され、BigQuery のコンソール画面(BigQuery Studio)からデータの流れをグラフィカルに確認することができます。INSERT SELECT や CREATE TABLE AS SELECT などのジョブが追跡され、以下の画像のようなリネージグラフとして表示可能になります。

- 参考 : データリネージについて
- 参考 : BigQuery テーブルのリネージを追跡する
詳細は、以下の記事を参照してください。
BigQuery Sharing
BigQuery Sharing
BigQuery Sharing は、BigQuery のデータセットを、他の組織に安全に共有したり、販売して収益化するための機能です。従来は Analytics Hub と呼ばれていましたが、2025年4月に改名されました。
BigQuery Sharing では、BigQuery データセットが共有可能なほか、Pub/Sub トピックを共有することで、ストリーミングデータを共有することもできます。
BigQuery Sharing には、追加の料金は発生しません。
仕組み
データを共有する側はパブリッシャー(Publisher)と呼ばれます。パブリッシャーは、データをパブリックエクスチェンジ(Public Exchange)またはプライベートエクスチェンジ(Private Exchange)に公開することで、データを共有します。
データを共有される側は、サブスクライバー(Subscriber)と呼ばれます。エクスチェンジからサブスクライブ(Subscribe)することで、データを利用可能になります。
サブスクライバーが BigQuery データセットをサブスクライブすると、リンクされたデータセット(Linked datasets)という形でデータが利用可能になります。サブスクライバーは自分の環境にデータセットをコピーする必要はなく、リンクされたデータセットを通じて、直接パブリッシャーのデータにアクセスすることができます。
パブリッシャーは、Data egress options を使うことで、サブスクライバーがデータをコピーしたり、ファイルとしてエクスポートすることを禁止することができます。このようなオプションにより、データを安全に共有することが可能です。
データクリーンルーム
BigQuery Sharing のデータクリーンルーム(Data clean rooms)は、セキュリティが強化された環境で、機密情報を安全に共有するための仕組みです。
パブリッシュとサブスクライブのモデルを採用している点では、通常の BigQuery Sharing によるデータ共有と同じです。しかし、データクリーンルームでは、分析ルールや Data egress controls などの仕組みにより、よりきめ細かいアクセス制御が可能になっています。
分析ルールでは、データへの直接アクセスを禁止して、集計クエリの実行のみを許可するなど、細かい制御が可能です。
マーケットプレイスでのデータ販売
BigQuery Sharing では、Google Cloud Marketplace を通じて、データを販売して収益化することができます。
Google Cloud Marketplace にデータをリスティングするには、Google による審査を受ける必要があります。また、特定の要件を満たしている必要があります。
非構造化データの分析
オブジェクトテーブル
オブジェクトテーブルは、Cloud Storage 内の非構造化データを分析するための仕組みです。オブジェクトテーブルは Cloud Storage 内のオブジェクトのメタデータを格納し、1行が1オブジェクトに対応します。
非構造化データとは、RDB のテーブルのように型(type)を含むスキーマが決まった構造化データや、CSV や JSON のように型が決まっていないが構造を有する半構造化データとは異なり、スキーマが決まっていないデータを指します。画像、動画、PDF、テキストファイルなどは非構造化データです。
オブジェクトテーブルはこれらのデータのメタデータを管理します。また仮想列である data にアクセスすることで、そのデータの RAW バイトにアクセスすることができます。
- 参考 : オブジェクト テーブルの概要
実現できること
オブジェクトテーブルの利用により、Cloud Storage 内の非構造化データに対して以下のようなことが実現できます。
- BigQuery ML による画像等の非構造化データを使った推論
- Cloud Vision API による画像の推論
- Cloud Translation API による翻訳
- Cloud Natural Language API による感情分析
- Apache Tika を用いた PDF のメタデータ抽出
アクセス制御
オブジェクトテーブルは、データソースへのアクセスに BigLake の仕組みを利用します。BigQuery は接続(Connection)に紐付けられたサービスアカウント権限を使って、Cloud Storage にアクセスします。
- 参考 : アクセス制御
高度なセキュリティ
基本編で解説したセキュリティ機能
基本編でもいくつかのセキュリティ機能を解説しています。基本編の以下の見出しをご参照ください。
- 参考 : BigQueryを徹底解説!(基本編) - アクセス制御
- 参考 : BigQueryを徹底解説!(基本編) - 暗号化
- 参考 : BigQueryを徹底解説!(基本編) - 列レベルのアクセス制御、行レベルのセキュリティ
- 参考 : BigQueryを徹底解説!(基本編) - VPC Service Controls
Sensitive Data Protection
Sensitive Data Protection は、機密性の高いデータを自動的に検出し、保護するためのフルマネージドサービスです。BigQuery とは別の Google Cloud プロダクトですが、BigQuery と密に連携できます。
Sensitive Data Protection を使うと、以下の方法で機密情報の所在を特定できます。
- データプロファイルの作成(Sensitive Data Protection が BigQuery テーブルを自動でスキャンして作成)
- オンデマンド検査(明示的に指示してテーブルまたは列をスキャン)
データのプロファイリングを行うと「リスクレベル」「機密性」などのインサイトがプロジェクトレベル、テーブルレベル、列レベルで得られます。
単一プロジェクトに対してプロファイルを行うことも、組織やフォルダレベルで指定して配下プロジェクト全体にプロファイルを行うことも可能です。
動的データマスキング
動的データマスキングは、セキュリティ目的で、クエリ結果を列レベルで動的にマスキングする機能です。
列レベルでアクセス制御をするという点で「列レベルのアクセス制御」と似ていますが、同機能では権限が無いアカウントがアクセス制御がかかった列にアクセスしようとすると権限エラーとなる一方で、動的データマスキングではエラーとならずに、難読化(null 化、マスキング、ハッシュ化など)された値が返ってきますので、既存の SQL を変更する必要がないという利点があります。
この機能は列レベルのアクセス制御と同様に分類(Taxonomy)やポリシータグを利用します。これらの概念については参考ドキュメントをご参照ください。
- 参考 : 動的なデータ マスキングの概要
- 参考 : BigQueryの列レベル・行レベルのセキュリティを解説
列レベル暗号化
Cloud KMS で暗号鍵を管理することで、透過的な暗号化とは別に、列レベルの暗号化をすることができます。
列レベルの暗号化は、データを暗号化するときに使う鍵、すなわち Data Encryption Key(DEK)とその暗号鍵をさらに暗号化する鍵である Key Encryption Key(KEK)を分けることで、キーの漏洩リスクを下げる手法であるエンベロープ暗号化で行われます。KEK は Cloud KMS で管理され、そのアクセス管理は IAM によって行われます。
暗号化は、INSERT/UPDATE 時の暗号化関数によって行います。確定的(deterministic)な暗号化関数と非確定的(non-deterministic)な暗号化関数があり、前者はインプットが同じであれば暗号文が同一になり、後者はインプットが同じでも、出力される暗号文が異なるものになります。前者の確定的暗号化を用いると、暗号化済みのテキストを使って集約や JOIN などの分析処理を行うことができます。
復号は SELECT 時に復号関数を用いることで行われます。クエリするユーザは、対象のテーブル・列に対するアクセス権限と同時に、Cloud KMS 鍵に対する権限も持っていなければ、データを復号することはできません。
- 参考 : Cloud KMS を使用した列レベルの暗号化
- 参考 : AEAD 暗号化のコンセプト
列レベルの暗号化の詳細は、以下の記事をご参照ください。
BigQuery BI Engine
BI Engine とは
BigQuery BI Engine(または単に BI Engine)とは、Looker Studio や Looker、Tableau などの BI ツールを主な対象として、クエリ結果をメモリにキャッシュすることで高速化する機能です。
BI Engine は BigQuery API と統合されており、BI ツールや API などから BigQuery が利用された際には自動的に BI Engine のキャッシュが適用されるので、アプリケーション側に変更が必要ありません。
- 参考 : BI Engine とは
料金
BI Engine では、予約というオブジェクトをプロジェクト内作成することでメモリ容量が確保されます。この確保した容量の GiB 数に応じて課金が発生します。
2025年4月現在の東京リージョンでは、$0.0499/GiB/hour です。
また BigQuery Editions でコミットメントを購入した場合、購入スロット数に応じて無料の BI Engine の GiB 枠が利用可能になります。
最新の料金は以下の公式ページをご参照ください。
- 参考 : BI Engine pricing
活用のテクニック
BI Engine では特にキャッシュを利用させたいテーブルを指定して、優先テーブルとしてマークできます。
また BI Engine を活用するテクニックとして、BI Engine を使用させたいクエリだけを別プロジェクトに切り出し、そのプロジェクトで BI Engine 予約を作成し、キャッシュを使わせたいクエリをそのプロジェクトに集中させるという方法もあります。これを優先テーブルと組み合わせることで、確保した BI Engine 予約を有効に活用することができます。
- 参考 : BI Engine に関する考慮事項
注意点
注意点として、BI Engine ではワイルドカードテーブルを参照するクエリをサポートしていません。
また他にも外部テーブルへのクエリやユーザ定義関数など、サポートされていない機能もあります。
- 参考 : サポートされていない機能
開発
BigQuery DataFrames
BigQuery DataFrames は、BigQuery API を介したデータの変換や機械学習を容易に行える Python のオープンソースパッケージです。
BigQuery DataFrames を用いると、BigQuery 上のデータを pandas のような操作感で処理ができ、scikit-learn のような操作感でモデルトレーニングと評価、予測が行えます。
以下の記事で詳細に解説していますので、ぜひご参照ください。
BigQuery リポジトリ
BigQuery リポジトリは、BigQuery と Git リポジトリを連携する機能です。Google Cloud コンソール(BigQuery Studio)上で、組み込みの Git リポジトリまたは GitHub 等の Git リポジトリと接続して、SQL ファイル等のバージョン管理をしたり、Git ワークフローを操作することができます。
詳細は以下の記事を参照してください。
パイプ構文
BigQuery では、標準的な SQL である Google SQL のほか、パイプ構文(Pipe syntax)でもクエリを記述することができます。
- 参考 : パイプクエリの構文を使用する
以下の例のように、構文をパイプでつなぐことで、順番に処理を記述することができます。処理の順に記述ができるため、アドホックな分析や、ログの分析の際に便利です。
FROM `myproject.mydataset.employee_master` |> WHERE location = 'Tokyo' |> JOIN `myproject.mydataset.sales` USING (employee_id) |> WHERE sales_date >= '2024-04-01' |> AGGREGATE SUM(sales_amount) AS total_amount GROUP BY employee_id, employee_name |> WHERE total_amount > 10000 |> ORDER BY total_amount DESC |> LIMIT 2
詳細は、以下の記事を参照してください。
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it