


G-gen の杉村です。Google Cloud(旧称 GCP)の認定資格である Generative AI Leader 資格の試験対策情報を紹介します。

基本的な情報
Generative AI Leader とは
Generative AI Leader 試験は、Google Cloud(旧称 GCP)の認定資格の一つです。当試験は、2025年5月14日(米国時間)に一般公開されました。
当試験は Foundational レベル(最初級)の資格であり、生成 AI に関する基礎的な知識や、Google Cloud や Google Workspace の生成 AI 関連サービス・機能の知識が問われます。また、Google Cloud 認定資格でありながら、非技術系のビジネスパーソンも対象としています。
試験時間は90分、問題数は50〜60問です。日本語版と英語版の試験が提供されています。認定の有効期間は3年間です。
この試験取得に向けて、Google は無料のオンライントレーニングコースを提供しています。当試験の合格に向けて有用なほか、ビジネスにおける生成 AI 活用のために重要な知識を学ぶことができます。
- 参考 : Generative AI Leader
- 参考 : Google Cloud announces first-of-its-kind generative AI leader certification
難易度
Generative AI Leader 試験の難易度は、他の認定試験と比較して、比較的低いといえます。
当試験はエンジニア向けというよりも、Generative AI Leader という試験名称のとおり、組織で生成 AI の活用をリードするようなビジネスパーソンに向けたものです。技術的に難しい内容は出題されず、コーディングの知識も必要ありません。
必要とされるのは、生成 AI の仕組みや振る舞いに関する基本的な知識や、ビジネスユースケースに応じて適切に Google Cloud や Google Workspace の生成 AI 関連サービス・機能を選定できる知見です。
生成 AI の基本的なキーワード(基盤モデル、プロンプトエンジニアリング、RAG など)や、Vertex AI、Gemini といった Google Cloud の主要な生成 AI 関連サービスについて理解していれば、合格を狙えるといえます。
出題傾向
当試験では、大きく分けて以下の4つの分野から出題されます。
| No. | セクション | 出題数 |
|---|---|---|
| 1. | 生成 AI の基礎(Fundamentals of gen AI) | 約30% |
| 2. | Google Cloud の生成 AI サービス(Google Cloud’s gen AI offerings) | 約35% |
| 3. | AI モデルの出力改善テクニック(Techniques to improve gen AI model output) | 約20% |
| 4. | 生成 AI ソリューションのビジネス戦略(Business strategies for a successful gen AI solution) | 約15% |
それぞれのセクションで出題される内容の詳細は、以下の公式試験ガイドを参照してください。また、当記事では各セクションごとに必要となる知識を整理しています。
試験対策
以下の勉強方法はあくまで一例であり、最適な方法は、受験者の予備知識や経験によって異なるものとご了承ください。
- 試験ガイドを確認する
- Google の無料オンライントレーニングを受講する
- Generative AI Leader Study Guide を確認する
- 公式の模擬試験を受ける
- 当記事で復習する
オンライントレーニングは、Skillsboost と呼ばれる Google Cloud の学習プラットフォームで公開されています。動画とテキスト、小テストを組み合わせたコースで、ウェブブラウザでいつでも受講することができます。試験問題はこの学習コースから出題されます。2025年5月現在、トレーニングコースの全編は英語ですが、動画では自動翻訳の日本語字幕を利用することができます。2025年5月現在は受験可能言語は英語のみなので、よく使われる英単語や表現に慣れておくことを推奨します。
また当記事ではこれ以降、試験の出題セクションごとに必要となる基本的な知識を紹介します。まずは公式トレーニングを受講することが推奨されますが、既にある程度知識のある方は、当記事をすぐに参考にすることも可能です。
生成 AI の基礎
このセクションでは、生成 AI に関する基本的な概念や用語について解説します。
生成 AI と基盤モデル
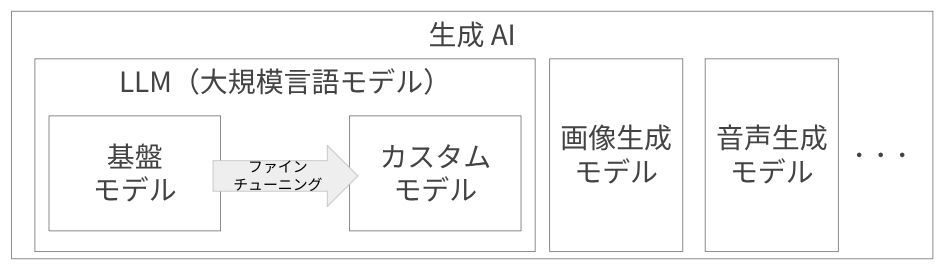
生成 AI (Generative AI)とは、文章、音声、画像、動画などのコンテンツを生成することに特化した AI(人工知能)のことです。特に、文章の理解や生成に特化した生成 AI モデルは Large Language Model(LLM)と呼ばれ、Google 社の Gemini や、Open AI 社の ChatGPT などが有名です。
基盤モデルとは、テキスト、画像、音声など、多様な形式の膨大なデータセットで事前トレーニングされた大規模な AI モデルであり、特に生成 AI の文脈で使われます。特定のタスクに特化せず、ファインチューニングやプロンプトエンジニアリングを通じて、翻訳、要約、質問応答、コンテンツ生成など、様々な下流タスクに対応できる汎用性が特徴です。
基盤モデルは、ファインチューニング(微調整のための追加のトレーニング)を通じて、特定のタスクに特化させることもできます。
データタイプ
AI モデルのトレーニングや利用においては、様々な種類のデータが扱われます。
まず、構造化データ(Structured Data)は、行と列を持つ表形式のデータ(例: データベースのテーブル、CSV ファイル)を指し、スキーマが明確に定義されている点が特徴です。
次に、非構造化データ(Unstructured Data)は、テキスト文書、画像、音声、動画など、特定の構造を持たないデータです。E コマースサイトのユーザーレビュー(自由記述テキスト)などがこれに該当します。
また、データの特性によっても分類されます。ラベル付きデータ(Labeled Data)は、データに対して人間が付与した正解ラベルやタグが付与されたデータです。例えば、画像に「猫」「犬」といったラベルが付いているデータセットが該当し、主に教師あり学習で利用されます。
一方、ラベルなしデータ(Unlabeled Data)は、正解ラベルが付与されていないデータであり、教師なし学習や自己教師あり学習で利用されます。
学習方法
AI モデルをトレーニングする方法は、データの種類や目的に応じて異なります。
教師あり学習(Supervised learning)では、ラベル付きデータを用いて、入力と出力の関係性を学習します。これは、分類(例: スパムメール判定)や回帰(例: 株価予測)などのタスクに用いられます。
教師なし学習(Unsupervised learning)では、ラベルなしデータを用いて、データに内在するパターンや構造を学習します。クラスタリング(例: 顧客セグメンテーション)、異常検知(例: 工場機器のセンサーデータからの異常検出)、次元削減などに用いられ、データの「自然な集まり(natural groupings)」を見つけるようなタスクに適しています。
強化学習(Reinforcement Learning)は、エージェントが環境と相互作用(interact)し、試行錯誤を通じて得られる報酬(フィードバック)を最大化するように行動を学習する方法です。ゲーム AI やロボット制御などに用いられます。
生成 AI ソリューションのレイヤー
Google の定義では、生成 AI ソリューションはいくつかのレイヤーで構成されます。このレイヤーを俯瞰して全体を見ることを、Google は Landscape(景観、展望、特質)と表現しています。
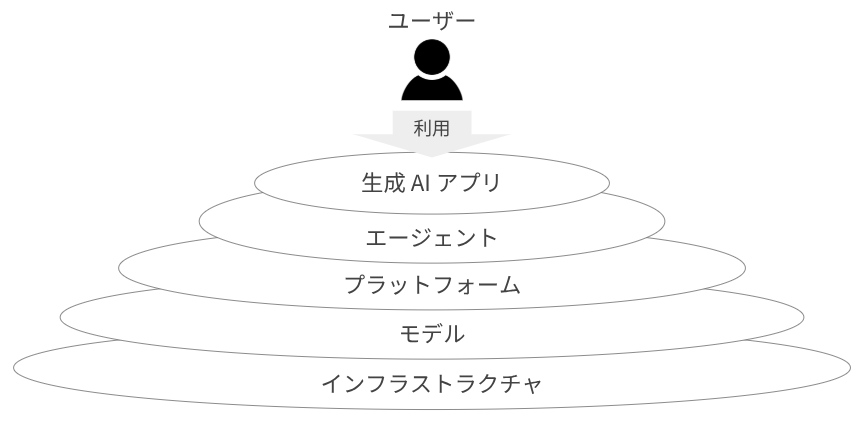
インフラストラクチャ(Infrastructure)レイヤーは、モデルのトレーニングや推論に必要な計算リソースを提供します。これには物理サーバー、CPU などに加えて、GPU や TPU といった AI に最適化されたハードウェアが含まれます。
モデル(Models)レイヤーは、AI ソリューションの頭脳にあたる部分です。Gemini のような生成 AI モデル(LLM)などが該当します。
プラットフォーム(Platform)レイヤーは、モデル開発、管理、デプロイのためのツールやサービスを提供し、Vertex AI やデータマネジメントツールなどが該当します。
エージェント(Agents)レイヤーは、モデルレイヤーを利用して複雑なタスクを行います。エージェントは周囲の環境に働きかけたり、情報を収集して、実行するアクションを決定し、実行します。
生成 AI アプリケーション(Gen AI applications)レイヤーは、エンドユーザーが直接利用する AI アプリケーションであり、ユーザーインターフェイスを提供します。
エージェント
エージェントとは
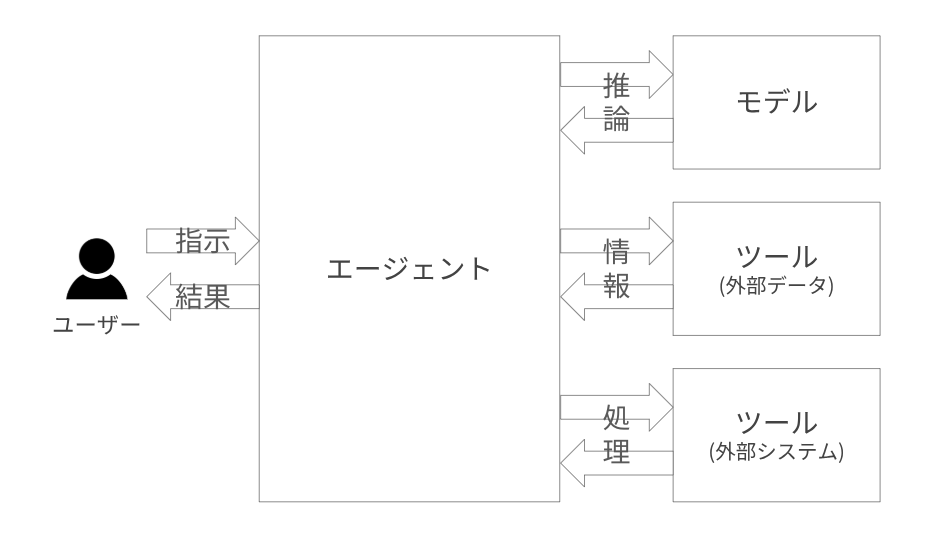
エージェント(Agents)とは、与えられた目標を達成するために、自律的に推論(Reasoning)し、ツール(Tools)を使用して行動(Acting)する AI システムです。この一連のプロセスは推論ループ(Reasoning Loop)と呼ばれることもあります。
なお、日本語では reasoning は「思考」や「推論」と訳されます。AI モデルがインプットに基づいてアウトプットを出力する処理を一般的に inference と呼びますが、この語も「推論」と訳されます。特に生成 AI の背景で、LLM が inference を繰り返し実行して論理的なタスクを行うことが reasoning であるといえます。
エージェントは、旅行予約サイトで飛行機やホテルを予約したり、カスタマーサポートで顧客との受け答えを行うなど、従来は人間が行っていたタスクを代わりに実行します。
エージェントは内部的に生成 AI(LLM)を利用しており、タスクを実行するときにはツール(Tools)と呼ばれるプログラムを呼び出して、タスクを実行します。一般的にはツールはプログラミング言語で書かれており、プログラムのロジックに従って計算を行ったり、外部 API へリクエストしてカレンダー予定の作成、メール送信、宿泊の予約などを行います。
種類
エージェントにはいくつかの種類や概念があります。
マルチエージェント(Multi-agent)は、複数のエージェントが協調して、より複雑なタスクを分担・実行するシステムです。Google は、特にこのマルチエージェントの考え方を推し進めています。
会話型エージェント(Conversational agents)は、テキストや音声による人間との会話を通じて、会話を理解し、質問に答えたり、タスクを実行します。
ワークフローエージェント(Workflow agents)は、人間の仕事を合理化(streamline)し、また自動化するエージェントです。人間が書いた申請書に基づいて、複数のシステムに対して入力を行ったり、また人間の代わりに様々な情報をインターネットから調査してレポート化したりします。
いずれのエージェントも、内部では生成 AI モデルを利用し、推論(Reasoning)を行い、ツール(Tools)を呼んでタスクを実行しています。
ユースケース
エージェントは、ユースケース別にも分類することができます。
Code Agent は、自然言語による指示に基づいて、ソースコードの生成、デバッグ、レビューなどを行うエージェントを指します。
Data Agent は、データに関するタスク(取得、分析、可視化など)を支援します。
Security Agent は、セキュリティに関するタスク(脅威検出、脆弱性分析など)を支援するエージェントです。
Customer Service Agent は、顧客からの質問への回答、問題解決、パーソナライズされた推奨事項の提供などを行うエージェントを指します。
Employee Productivity Agent は、従業員の情報検索、タスク管理、ワークフローの自動化などを支援するエージェントです。
Creative Agent は、新しいアイデアの生成、画像や動画などのコンテンツ作成、言語翻訳などを行うエージェントを指します。
ツール
エージェントは、目標達成のために様々なツール(Tools)を利用します。ツールは以下のような種類に分類できます。
Extentions(APIs) は、外部の API と連携するためのツールです。例えば、旅行予約 API を叩いて予約を行う Extension などが考えられます。
Functions は、特定のロジックを実行するためのツールです。例として、特定のロジックで料金計算を行う Function が考えられます。
Data Stores は、リアルタイムデータ、履歴データ、ナレッジベースなど、エージェントに情報を提供するためのツールであり、顧客データベースや天気予報の取得などが該当します。
Plugins は、外部システムと連携し、エージェントに新しいスキルを与えるツールです。例として、カレンダーアプリと連携して予定を作成したり、支払いシステムと連携して取引を成立させるなどの Plugin が考えられます。
推論ループ
エージェントは、「Reasoning(ツール選択)→Acting(ツール実行)→Observation(結果確認)→Iteration(繰り返し)」というサイクルを通じて、ツールを駆使しタスクを遂行します。
このようなループを推論ループ(Reasoning loop)といったり、ReAct サイクル(reasoning and acting cycle)と呼んだりします。
例えば、庭園リフォームコンサルタントの予約を行うエージェントを例に取ると、以下のようになります。ユーザーがコンサルの依頼をエージェントに投げかけると、以下のような処理が実行されます。
1. Reasoning
コンサルの空き時間を見つけるために、スケジューリングの Plugin を選択。
2. Acting
スケジューリング Plugin を使って、コンサルの空き時間を確認。また顧客情報データベースから、予約希望者の情報を取得。
3. Observation
スケジューリング Plugin が返した予約候補時間を確認。
4. Iteration エージェントが予約希望者に、候補時間を返答。希望者と時間をすり合わせて、予約が完了するまでやりとりを続ける。
Google Cloud の生成 AI サービス
このセクションでは、Google Cloud が提供する主要な生成 AI 関連サービスについて解説します。
Vertex AI
Vertex AI とは
Vertex AI は、機械学習モデルの開発、トレーニング、デプロイ、管理を行うための統合プラットフォームであり、Google Cloud で提供されています。
Vertex AI はトレーニング、推論、開発ツール、パイプライン管理など、MLOps のための包括的な機能を提供します。そのため、各ステップで個別のプラットフォームを選定する必要がありません。また、Google Cloud サービスであるため、Google の基盤モデルへのアクセスが容易なほか、オープンソースモデルやサードパーティのモデル(Claude や Llama など)へのアクセスも提供します。
このように、Google はオープンなプラットフォームを提供することを意識しています。Google Cloud(Vertex AI)では特定の会社が開発した AI モデルだけが利用可能なのではなく、さまざまな出自のモデルが利用可能です。
- 参考 : Vertex AI の概要
Model Garden
Model Garden は、Google やパートナー、オープンソースコミュニティによって開発された多様な基盤モデルや事前トレーニング済みモデルを発見、探索、試用できるカタログです。ここからモデルを選択し、Vertex AI 上でファインチューニングやデプロイを行うことができます。
Gemini のような、Google のファーストパーティモデルは Vertex AI にネイティブに統合されている(組み込まれている)ので、Model Garden から呼び出す必要はありませんが、Claude や Llama のような他社の(サードパーティの)モデルを使いたいときは、Model Garden 経由でモデルをデプロイします。
Model Registry
Model Registry は、トレーニング済みの機械学習モデルを一元的に管理、バージョニング、デプロイするためのリポジトリです。モデルのライフサイクル管理を効率化し、本番環境への安全なデプロイを支援します。モデルのバージョン管理機能により、必要に応じて過去のバージョンに戻す(ロールバック)ことも可能です。このようなモデルのバージョン管理戦略は、モデルバージョニング(Model Versioning)と呼ばれます。
Vertex AI Search
Vertex AI Search は、ウェブサイトや非構造化・構造化データソースに対して、高度なセマンティック検索(意味論検索)やチャットボットなどを迅速に構築できるサービスです。EC サイトの商品検索精度向上などに活用できます。
なお、Vertex AI Search は AI Applications(旧称 Vertex AI Agent Builder)という Google Cloud プロダクトの1機能です。
- 参考 : AI Applications とは
Vertex AI Search では、企業が持つデータをベクトル化(エンベディング)し、データストアに格納します。これにより、文字列一致ではなく、意味による検索を可能にします。
以下の記事も参考にしてください。
Vertex AI Pipelines
Vertex AI Pipelines は、機械学習ワークフローを自動化、管理、監視するためのサービスです。モデルのトレーニング、評価、デプロイといった一連のステップをパイプラインとして定義し、再現性のある ML プロセスを構築できます。
試験で細かく問われることはありません。上記のように、AI モデルの開発ライフサイクル全体をカバーするプラットフォームであることを理解しましょう。
Gemini
Gemini と関連サービス
Gemini は、Google が開発したマルチモーダルな(テキスト、画像、音声、動画などを扱える)基盤モデルファミリーです。様々なサイズと能力のモデルが提供されており、ユースケースに応じて選択できます。Gemini は、以下のように、さまざまなサービスに組み込まれています。
Gemini in Google Workspace は、Gmail、ドキュメント、スプレッドシートなどの Workspace アプリケーションに組み込まれ、文章作成支援、要約、データ分析などを支援します。セールスチームがメール作成や顧客対応を効率化するなどのユースケースが考えられます。
Gemini アプリ は、一般ユーザー向けの対話型 AI アシスタントです。パソコンの Web ブラウザから使う Gemini ウェブアプリや、スマートフォンから利用する Gemini モバイルアプリがあります。また、有償版である Gemini Advanced では、より高性能なモデルや追加機能が利用できます。
- 参考 : Gemini アプリ
Gems は、特定のタスクや目的に合わせて Gemini アプリをカスタマイズできる機能です。無償版の Gemini アプリには付属しておらず、有償版である Gemini Advanced で利用することができます。
これらのように Google がユーザー向けサービスとして提供している AI ソリューションを利用していれば、将来的に AI モデルが新しくなったときにも Google が随時、最新のモデルに更新してくれます。これは、API 経由でモデルを呼び出すような独自の AI アプリをユーザーが開発するのに比べて、メリットとなります。
Gemini を使った開発
ユーザーは前述のように Gemini が組み込まれているサービスを利用できますが、開発者が Gemini モデルを使用して、独自のアプリケーションを開発することができます。開発者向けのプラットフォームとして、以下のようなものがあります。
Google AI Studio は、個人開発者や学生、研究者向けの、ウェブベースの開発ツールです。難しい設定をすることなく、すぐに Gemini モデルが試用できるほか、パラメータを変更して生成コンテンツの変化を確認することができます。
一方で、会社などの組織が Gemini を用いて開発する場合は、Google Cloud と統合された Vertex AI を使うことが望ましいといえます。Vertex AI の中の Vertex AI Studio を使うと、簡単に Gemini モデルを試用したり、パラメータ調整を試したり、プロンプトを保存して再利用することができます。
- 参考 : Google AI Studio
- 参考 : Vertex AI Studio - エンタープライズ対応の生成 AI のテスト、チューニング、デプロイ
- 参考 : Gemini Proを使ってみた。Googleの最新生成AIモデル - G-gen Tech Blog
Gemini 系プロダクト
上記のように、Gemini と名のつくプロダクトは多数あります。以下の記事では、それぞれの詳細が解説されています。
Gemini Enterprise(旧称 Google Agentspace)
Gemini Enterprise(旧称 Google Agentspace)は、企業のデータを横断検索する機能と、検索結果をもとに AI が要約を生成したりコンテンツを生成する機能、また他システムに働きかけて人間の代わりにタスクを行うエージェント機能を備えた、Google の SaaS です。Gemini Enterprise を、Microsoft 365 の SharePoint や Teams に接続したり、Box や Google ドライブといったストレージサービスに接続することで、データを横断検索したり、活用することができます。
企業は、Gemini Enterprise を導入することで、従業員が散在するデータを活用できるようになり、コラボレーションが促進されます。
詳細は、以下の記事も参照してください。
NotebookLM
NotebookLM は、「パーソナライズされた AI リサーチパートナー」であると位置づけられている Google の AI サービスです。
ユーザーが独自のドキュメントや画像などを NotebookLM にアップロードすることで、AI が要約、分析、コンテンツの生成を行うことができます。Gemini アプリが、生成 AI の学習データやインターネット上のデータに基づいてタスクを行うのに対して、NotebookLM はユーザーの独自データに基づいてタスクを行うことができます。
NotebookLM には、無償版のほか、有償版の NotebookLM Plus、企業向けの NotebookLM Enterprise が存在しています。
NotebookLM の基本や使い方については、以下の記事も参照してください。
画像・動画生成
画像や動画の生成に特化したモデルやサービスもあります。
Imagen は、テキストの説明から高品質な画像を生成するモデルです。
Veo は、テキストや画像から高品質な動画を生成するモデルです。
Google Vids は、Google Workspace アプリとして提供される、AI を活用した動画編集ツールです。カスタムアバターやナレーション生成機能があり、既存の動画や写真、音声などの素材から、簡単に完成度の高い動画を編集できます。Google Workspace のエディションに組み込まれているため、追加の費用を払うことなく、動画を作成したい場合に適しています。
Chirp は、テキストから自然な読み上げ音声を生成(いわゆる Speech-to-Text)できるモデルです。
- 参考 : Vertex AI の Imagen | AI 画像生成ツール
- 参考 : Veo 2
- 参考 : Google Vids
- 参考 : Chirp: ユニバーサル音声モデル
各モデルの役割が試験で問われる可能性がありますので、以下のように覚えましょう。
- 画像生成 → Imagen
- 動画生成 → Veo
- 動画編集 → Google Vids
- 音声生成 → Chirp
オープンモデル
Gemma は、Google が開発した、軽量で高性能なオープンモデルファミリーです。研究者や開発者が自由に利用・カスタマイズでき、要約やレポート草稿作成などのタスクに活用できます。
通常の Gemini が API 経由でリモートから呼び出して使うのに対して、Gemma はモデル自体を Google Kubernetes Engine(GKE)のようなプラットフォームに搭載するため、データが外部に出ません。これにより、機密性やレイテンシの面でメリットがあります。
- 参考 : Gemma
特定タスク向け AI/ML サービス
Google Cloud は、特定のタスクに特化した学習済み API やサービスも提供しています。これらは、機械学習の専門知識が少ない組織でも容易に AI を活用できる選択肢となります。
Document AI は、PDF や画像などのドキュメントからテキストや構造化データを抽出する AI サービスです。保険申込書の PDF から情報を自動入力するなど、手作業のデータ入力を効率化できます。
Natural Language API(Natural Language AI)は、テキストデータの感情分析、エンティティ抽出、構文解析などを行う API です。
Vision AI は、画像内のオブジェクト検出、ラベル付け、顔検出、OCR などを行う API です。
- 参考 : Document AI
- 参考 : Natural Language AI
- 参考 : Vision AI
Customer Engagement Suite
Customer Engagement Suite(with Google AI)は、AI 補助により、カスタマーセンター業務を補助するサービススイート(サービス群)です。Customer Engagement Suite には、以下の機能が含まれています。
| 機能名 | 説明 |
|---|---|
| Conversational Agents | 自然言語を理解し、自動応答を行う会話型 AI(チャットボット、ボイスボット)を構築するためのプラットフォーム |
| Agent Assist | 人間のオペレーターに対して、リアルタイムで関連情報を提供したり、応答文案を提案したりすることで、顧客対応を支援するツール |
| Contact Center as a Service (CCaaS) | 電話、チャット、メールなど、複数のチャネルを統合管理し、AI による自動応答や分析機能を提供する包括的なコンタクトセンタープラットフォーム |
Customer Engagement Suite というサービススイート名と、上記の3つの機能名については、名前と概要、ユースケースを覚えておき、試験で答えられるようにしてください。
イメージとしては、「AI が顧客対応をするのが Conversational Agents」「人間のオペレーターを補助するのが Agent Assist」「コンタクトセンター業務を包括的に支援するのが Contact Center as a Service(CCaaS)」と覚えてください。
セキュリティとガバナンス
AI 活用におけるセキュリティとガバナンスも重要です。
Identity and Access Management(IAM)は、Google Cloud リソースへのアクセス権限を管理するサービスです。生成 AI モデルや関連リソースへのアクセス制御にも IAM を使用し、最小権限の原則に従うことが重要です。適切な人が、適切なリソースにのみ、アクセスできることを担保するのが、この IAM です。
Secure AI Framework(SAIF)は、Google が提唱する、AI システムを安全に設計、開発、運用するためのフレームワークです。開発者は、AI アプリケーションのセキュリティを確保するためのベストプラクティスとして、SAIF を参照できます。AI アプリケーションをセキュアに設計するための道しるべであると覚えてください。
Secure-by-Design は、Google のインフラストラクチャやサービスが、設計段階からセキュリティを組み込む原則に基づいて構築されていることを示す原則です。企業の経営層が、Google Cloud の安全性について知りたいときは、Google 製品や Google Cloud が Secure-by-Design 原則に基づいて設計されていることを示します。
データの保護に関して、Gemini for Google Workspace や Vertex AI などの有償の Google サービスでは、顧客データがモデルのトレーニングに許可なく使用されることはありません。また、転送中および保管中のデータはデフォルトで暗号化されます。
- 参考 : 生成 AI とデータ ガバナンス - Generative AI on Vertex AI
- 参考 : Gemini for Google Workspace に関するよくある質問 - Google Workspace with Gemini ではどのようにデータが保護されますか?
データ基盤との連携
生成 AI はデータ基盤との連携により真価を発揮します。
BigQuery は、フルマネージドのデータウェアハウスであり、構造化データ、半構造化データ(JSON など)、ストリーミングデータなどを格納・分析できます。BigQuery ML を使用すれば、SQL だけで機械学習モデルを構築・利用できます。
Cloud Storage は、スケーラブルで耐久性の高いオブジェクトストレージで、非構造化データ(画像、動画、ログファイルなど)の格納に適しています。
Pub/Sub は、スケーラブルな非同期メッセージングサービスであり、ストリーミングデータの取り込みに適しています。
これらのサービスを組み合わせることで、多様なデータを収集・処理し、生成 AI モデルのトレーニングや推論に活用する基盤を構築できます。例えば、Pub/Sub でストリーミングデータを受け取り、Cloud Storage や BigQuery にデータを格納することができます。そのデータを AI モデルのトレーニングや、RAG(後述)に活かすことができます。
AI モデルの出力改善テクニック
生成 AI モデルの出力を意図通りに制御し、質を高めるためのテクニックについて解説します。
プロンプトエンジニアリング
プロンプトエンジニアリングとは、モデルへの指示(プロンプト)を工夫することで、出力結果を改善する手法です。
Zero-shot Prompting は、モデルにタスクの例を一切示さずに、タスクの説明だけで指示する方法です。モデルが持つ汎用的な知識だけで対応できる場合や、事前データがほとんどない新しい分野での探索に適しています。
One-shot Prompting は、タスクの例を 1 つだけ示して指示する方法です。
Few-shot Prompting は、タスクの例をいくつか (2〜5個程度) 示して指示する方法です。これにより、モデルにタスクのパターンや期待する出力形式をより明確に伝えられます。例えば、メールを指定されたラベル(例: バグ報告、技術的な質問)に分類するようなタスクでは、ラベルごとの分類例を示す Few-shot Prompting が有効です。
Role Prompting は、モデルに特定の役割(例:「あなたは親切なカスタマーサポート担当者です」)を与えることで、出力のトーンやスタイルを制御する方法です。モデルの再トレーニングなしに、より顧客に寄り添った応答を生成させたい場合に有効です。
Prompt Chaining は、一つの複雑なタスクを複数の単純なプロンプトに分割し、前のプロンプトの出力を次のプロンプトの入力として連鎖させる方法です。チャット形式で過去のやり取りを踏まえた応答を得ることもこれに含まれます。
- 参考 : プロンプトの概要
パラメータ調整
モデルの生成プロセスを制御するパラメータを調整することで、出力の特性を変えることができます。
Temperature(温度)は、出力のランダム性を制御します。値を高くすると、より多様で創造的な出力になりますが、一貫性が失われる可能性もあります。設定値としては、0〜1 の範囲が一般的です。生成されるデザインの幅を広げたり、独創性を高めたい場合などは、Temperature を上げることを検討します。
Output Length(Max output tokens)は、生成されるテキストの最大長(トークン数)を指定します。
Top-K は、次の単語を選択する際に、確率の高い上位 K 個の候補からランダムに選ぶ方式です。Top-P(Nucleus Sampling)は、次の単語を選択する際に、確率の合計が P を超えるまでの上位候補からランダムに選ぶ方式です。いずれも、ランダム性を増やしたい場合は数字を大きくします。
- 参考 : パラメータ値を試す
グラウンディング
グラウンディング(Grounding)とは、モデルの知識を外部の信頼できる情報ソースで補強し、出力の正確性や信頼性を向上させる手法です。これは、モデルが事実に基づかない情報を生成するハルシネーションを抑制するのに有効です。
Google Search によるグラウンディングでは、モデルの回答生成時に Google Search を利用して最新情報や信頼性の高い情報を参照させます。インターネット上の最新ニュースを収集・要約するような機能に適しています。
独自データによるグラウンディングは、企業内のドキュメントやデータベースなど、特定のデータソースを検索し、そこで見つかった関連情報をプロンプトに含めてモデルに渡すことで、そのデータに基づいた回答を生成させます。これにより、データソースにある最新の情報や内部情報に基づいた出力を得られます。
サードパーティデータによるグラウンディングでは、市場調査レポートや業界ニュースなど、信頼できる外部データソースを活用して回答の根拠づけを行います。
生成 AI アプリケーションにおいて、外部データに基づいたグラウンディングを行うアーキテクチャを、RAG(Retrieval-Augmented Generation)と呼びます。ハルシネーションを抑制するには、RAG を実装し、外部のデータや最新のデータを参照して、生成 AI に生成を行わせることが重要です。RAG を構成しない場合、生成 AI モデルは、過去に学習した大量のデータに基づいてのみ生成を行うため、古いデータをもとに、事実と異なる生成を行ってしまう可能性があります。
- 参考 : グラウンディングの概要
- 参考 : 検索拡張生成(RAG)とは
ハルシネーション
モデルが、学習データに含まれていない、または事実と異なる情報を、あたかも真実であるかのように生成してしまう現象をハルシネーションと呼びます。イベントの要約はできるが、詳細情報になると不正確な内容を出力し始める、といった場合にハルシネーションが疑われます。対策としては、前述のグラウンディングが有効です。
生成 AI ソリューションのビジネス戦略
生成 AI をビジネスに導入し、成功させるための戦略や考慮事項について解説します。
導入アプローチ
Google は、生成 AI の導入において、トップダウン(経営層主導)とボトムアップ(現場主導)の両方を組み合わせた双方向(Multi-directional)なアプローチを推奨しています。経営層がビジョンを示し、現場が具体的なユースケースや課題を特定することで、効果的な導入が促進されます。
また、検討段階においては、どのツールを使うかなどの手段に着目するのではなく、投資対効果(RoI)やビジネスインパクトに着目することが重要です。
ライフサイクルにおける考慮事項
AI アプリケーションの開発ライフサイクル全体を通じて、様々な点に注意が必要です。
データ収集(Gathering)段階
- 収集するデータの品質と量を確保します。
- データのプライバシーとセキュリティを保護し、適切なアクセス制御を行います。
- データの偏り(バイアス)に注意します。
モデルトレーニング(Training)段階
- トレーニングデータのセキュリティを確保し、不正なアクセスや改ざんを防ぎます。
- モデルの性能評価指標を定義し、定期的に評価します。
- 過学習(トレーニングデータに過剰に適合し、未知のデータに対する汎化性能が低下すること)を防ぐための対策を講じます。
デプロイ・運用(Deploy、Operation)段階
- モデルの性能を継続的にモニタリングします。
- ユーザーからのフィードバックを収集し、モデル改善に役立てます。
- モデルの挙動(特に予期せぬ出力やバイアス)を監視します。
ビジネス上のメリット
生成 AI は様々なビジネス上のメリットをもたらします。
効率化と生産性向上として、レポート作成、メール作成、コード生成などの定型業務を自動化できます。
顧客体験の向上の面では、パーソナライズされたレコメンデーション、24 時間対応のチャットボットなどを提供できます。EC サイトにベクトル検索を導入し、顧客が目的の商品を見つけやすくすることで、顧客満足度向上と売上増加に繋がる可能性があります。
新しいインサイトの発見として、大量のデータから人間では気づきにくいパターンやインサイトを抽出できます。
イノベーションの加速にも繋がり、新製品やサービスのアイデア創出、研究開発のスピードアップを支援します。
責任ある AI
AI を倫理的かつ社会的に責任ある方法で開発・利用するための原則と実践が責任ある AI(Responsible AI)です。Google は責任ある AI の原則に注意深く従って、AI ソリューションを開発しています。また、それらのソリューションを利用したり、モデルを使って開発を行う我々ユーザーも、この原則に従うことが重要です。
バイアス(Bias)は、モデルが学習データに含まれる偏見(例: 性別、人種などに関するステレオタイプ)を学習・増幅し、不公平または差別的な結果を生み出すことです。採用候補者のスクリーニングで、過去のデータに基づき特定の属性(例: 男性)を不当に有利に扱ってしまうなどが該当します。
データ依存(Data Dependency)は、モデルの出力が、トレーニングに使用された特定のデータセットに強く依存してしまうことです。学習データが古かったり、特定の時期や状況に偏っていたりすると、現在の状況に合わない分析結果を出力してしまう可能性があります(例: 古い顧客の声データで学習したモデルが、現在の分析基準と合わない)。
説明可能性(Explainable AI / Interpretability)は、モデルがなぜそのような予測や判断を行ったのかを人間が理解できるようにすることです。特に金融(ローン審査)や医療など、判断根拠の説明責任が求められる分野で重要です。ユーザーがモデルの判断(例: ローン審査の拒否)に不満を持つ場合、判断理由を説明できることが重要になります。
透明性(Transparency)は、AI システムの動作、機能、限界について、情報を明確かつアクセス可能な形で提供することです。
公平性(Fairness)は、AI システムが、特定のグループに対して不当な不利益を与えないようにすることです。
プライバシーとセキュリティは、ユーザーデータや機密情報を適切に保護することです。
Human-in-the-Loop(HITL)は、AI の判断プロセスに人間が介在し、最終的な意思決定や品質チェックを行うアプローチです。例えば、口コミの文章における皮肉の表現のような AI が苦手とするニュアンスの解釈や、重要な判断において、人間の介入が有効です。
ユースケースの選定と導入戦略
生成 AI の導入にあたっては、適切なユースケースの選定と戦略が重要です。
適切なユースケースの選定においては、生成 AI が創造的なタスクやパターン認識に優れている一方で、厳密なルールベースの判断や計算が求められるタスクには必ずしも適していない点を考慮する必要があります。住宅ローンのように、厳密に定義されたルールに基づいて承認・拒否を決定するプロセスには、従来のプログラムの方が適している場合があります。
初期段階でのフォーカスとしては、新しい AI 機能を導入する際は、まずその機能がエンドユーザーにどのような価値(メリット、ポジティブな体験)をもたらすかを明確にすることが重要です。技術的な実現可能性やインフラ投資の前に、ビジネス価値を検証します。
組織における役割も、AI 導入にあたって重要になります。経営層は、的確なビジョンを示し、AI 導入が中長期的に見てビジネスにどのようなインパクトを与えるかを検討します。中間管理職(Mid-level managers)は AI 導入によって最もインパクトがありそうな業務プロセス(workflow)を特定し、具体的な課題を明確化する役割を担います。一方、従業員は新しい AI ツールを活用し、日々の業務を効率化することが期待されます。
生成 AI の導入は、単なる技術導入ではなく、ビジネスプロセスや組織文化の変革を伴います。明確な目標設定、適切なユースケース選定、そして責任ある AI の原則に基づいた慎重な導入が成功の鍵となります。
杉村 勇馬 (記事一覧)
執行役員 CTO
元警察官という経歴を持つ IT エンジニア。クラウド管理・運用やネットワークに知見。AWS 認定資格および Google Cloud 認定資格はすべて取得。X(旧 Twitter)では Google Cloud や Google Workspace のアップデート情報をつぶやいています。
Follow @y_sugi_it